Особенности задач НЛП:
Вход представляет собой одномерную линейную последовательность (упорядоченную) переменной длины .
Поскольку текст может иметь удаленные функции, то, может ли экстрактор функций иметь возможность захватывать удаленные функции, также имеет решающее значение для решения задач НЛП. От того, адаптируется ли экстрактор признаков к характеристикам проблемной области, иногда зависит его успех или неудача, и направление многих улучшений модели на самом деле состоит в том, чтобы сделать ее более соответствующей характеристикам предметной области .
НЛП четыре категории задач:
Четыре основных типа задач НЛП: классификация, маркировка последовательностей, сопоставление текста и генерация текста.
- Вторая категория - задачи классификации, такие как наша общая классификация текста, эмоциональные вычисления и т. Д., Можно отнести к этой категории. Ее особенность в том, что какой бы объемной ни была статья, в ней нужно лишь дать классификационную категорию в целом.
- Одной из них является маркировка последовательностей, которая является наиболее типичной задачей НЛП, например, сегментация китайских слов, маркировка частей речи, распознавание именованных сущностей, маркировка семантической роли и т. д. Все они могут быть отнесены к этому типу проблем, и их характеристика что каждое слово в предложении требует модели для контекста, ему присваивается таксономическая категория.
- Третий тип задач — сопоставление текста, например, Entailment, QA, семантическое переписывание, рассуждение на естественном языке и другие задачи — все в этом режиме Его характеристика заключается в том, что при наличии двух предложений модель оценивает, имеют ли два предложения определенную семантическую связь. ;
- Четвертая категория — генерация текста, например, машинный перевод, обобщение текста, написание стихов и предложений, озвучивание изображений и т. д. — все они относятся к этой категории. Его особенность заключается в том, что после ввода текстового содержимого ему необходимо самостоятельно сгенерировать еще один фрагмент текста.
Преимущество глубокого обучения заключается в том, что оно «сквозное», что означает, что в прошлом персоналу НИОКР приходилось решать, какие функции проектировать и извлекать.После эпохи сквозного обучения вам не нужно беспокоиться о это вообще Бросьте исходный ввод в хороший экстрактор функций, и он автоматически извлечет полезные функции. Другими словами, что вам нужно сделать, это: выбрать хороший экстрактор признаков , передать ему большое количество обучающих данных, установить цель оптимизации (функция потерь) и сказать, что вы хотите, чтобы он делал. Тогда дизайн экстрактора признаков становится главным приоритетом.
1. Мешок слов (BoW)
BoW (Bag of Words) — широко используемый метод представления текста для преобразования текста в числовые векторы. Основная идея BoW состоит в том, чтобы рассматривать текст как слова в мешке (или наборе), игнорировать порядок и грамматическую структуру между словами и фокусироваться только на частоте слов. Конкретные шаги заключаются в следующем:
-
Пополнение словарного запаса. Во-первых, создайте словарный запас уникальных слов, которые встречаются во всех текстах.
-
Представление вектора признаков: для каждого образца текста, в соответствии со словами в словаре, отметьте количество вхождений слова в соответствующей позиции образца или используйте его вес.
-
Векторное представление: Матрица вектора признаков используется в качестве числового представления текста, то есть каждый образец текста сопоставляется с разреженным числовым вектором.
К преимуществам использования BoW для текстового представления относятся:
-
Простой и интуитивно понятный: метод BoW прост для понимания и применения независимо от грамматики и порядка слов.
-
Игнорирование ненужной информации: BoW может отфильтровывать ненужную грамматическую информацию и информацию о порядке слов и уделять больше внимания частоте слов в тексте.
Однако метод BoW также имеет некоторые ограничения и недостатки:
-
Потеря информации о порядке слов: BoW игнорирует отношения порядка между словами и, таким образом, не может получить контекстуальную и семантическую информацию между словами.
-
Многомерные разреженные векторы: для больших словарей и крупномасштабных наборов текстовых данных представления BoW генерируют многомерные разреженные векторы, что приводит к увеличению накладных расходов на вычисления и хранение.
Несмотря на некоторые ограничения, BoW по-прежнему является основным методом для многих задач обработки текста и может служить основой для других, более сложных методов представления текста.
2. РНН

Как видно из приведенного выше рисунка, каждый вход соответствует узлу скрытого слоя, и между узлами скрытого слоя формируется линейная последовательность, и информация постепенно передается в обратном направлении между скрытыми слоями спереди назад.
Вначале RNN принимает структуру линейной последовательности для непрерывного сбора входной информации от начала к концу, но длинный путь обратного распространения может легко вызвать исчезновение градиента или взрыв градиента. Чтобы решить эту проблему, были введены модели LSTM и GRU, а информация о промежуточном состоянии напрямую распространялась в обратном направлении, чтобы облегчить проблему исчезновения градиента, и были достигнуты хорошие результаты, поэтому LSTM и GRU вскоре стали стандартной моделью RNN.
Поскольку структура РНС естественным образом адаптирована для решения задач НЛП, входные данные НЛП часто представляют собой линейную последовательность предложений переменной длины, а сама структура РНС представляет собой сетевую структуру, которая может принимать входные данные переменной длины и передавать информацию. линейно спереди назад После, Таким образом, RNN особенно подходит для сценариев приложений линейной последовательности, таких как НЛП, что является основной причиной, почему RNN так популярен в мире НЛП.
Недостатки RNN: вычисление скрытого слоя зависит от двух входных данных, один из которых является вводом слова в предложении, а другой является выходом, который зависит от состояния предыдущего скрытого слоя. То есть конечный результат нужно рассчитывать поэтапно по временному шагу, то есть зависимости от последовательности . Именно потому, что структура, зависящая от последовательности, не очень дружелюбна к параллельным вычислениям, вычисления идут медленно, и ее легко заменить быстро восходящей звездой.
CNN и Transformer не имеют этой проблемы зависимости от последовательности и могут рассчитываться параллельно.
2.3 встраивание слов
Внедрение слов, которое отличается от модели мешка слов, например, word2Vec и GLoVe.

Идея основной функции P состоит в том, чтобы предсказать вероятность того, какое слово последует, на основе ряда предшествующих слов в предложении (теоретически, в дополнение к вышесказанному, вы также можете ввести контекст слова для совместного предсказания вероятность слова), тем больше значение представляет это больше похоже на человеческое высказывание. Дайте вам много корпуса, чтобы сделать это. Как хорошо обучить нейронную сеть. После обучения введите первые несколько слов предложения в будущем и попросите сеть вывести, какое слово должно следовать сразу. Что вы будете делать? - Языковая модель нейронной сети (NNLM).
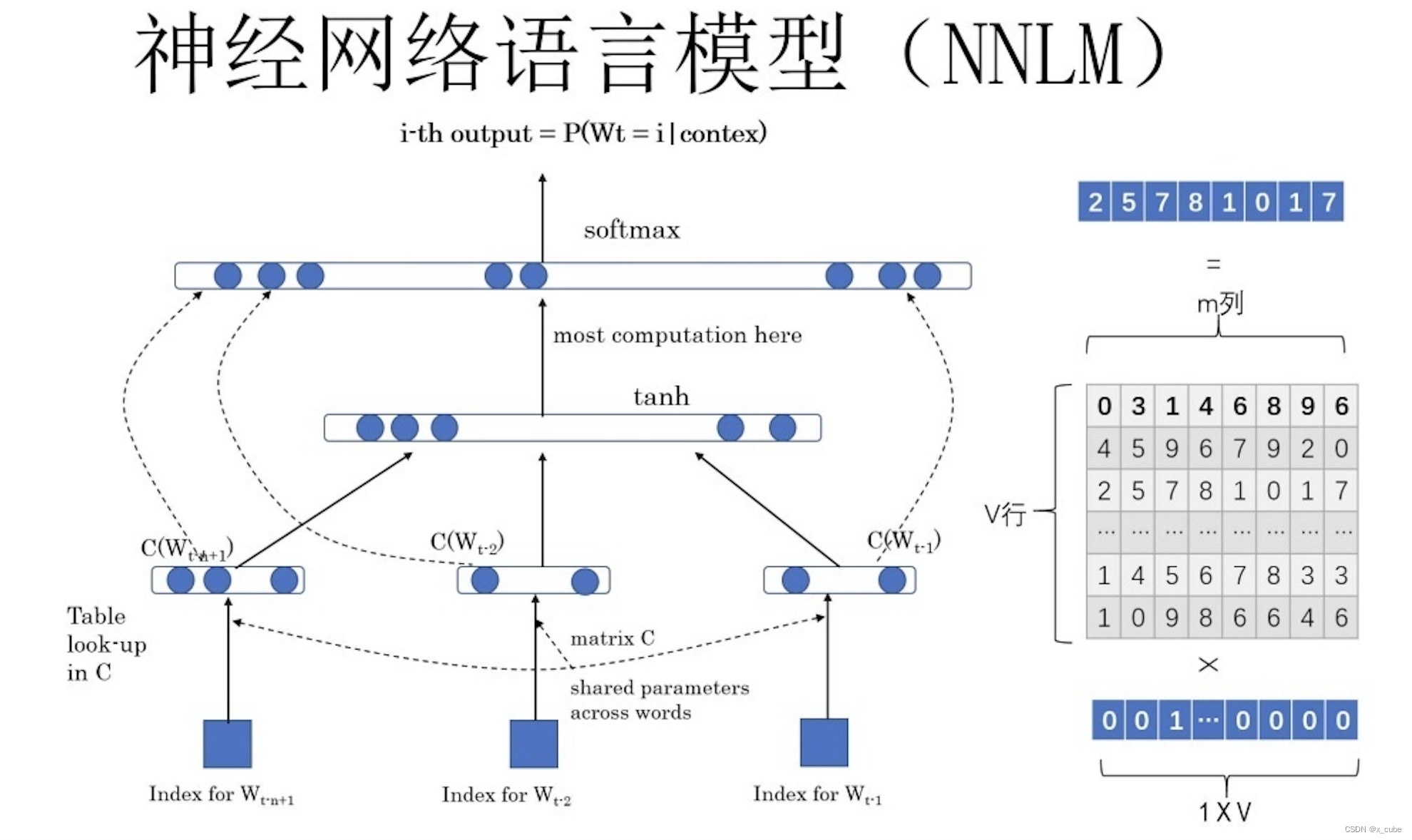
Любое слово W использует горячее кодирование в качестве исходного ввода, умноженное на матрицу Q, чтобы получить вектор C(W)) (то есть вложение слова, соответствующее слову, строка Q соответствует значению вложения слова слова, Q нужно выучить) каждое слово C(W) Splicing, подключить скрытый слой, а затем подключить softmax, чтобы предсказать, за каким словом следует следовать. С помощью этой задачи модели языка сетевого обучения сеть может не только предсказать, какое следующее слово будет основано на вышеизложенном, но также получить побочный продукт, который представляет собой матрицу Q, именно так изучается встраивание слова в слово.
2.3.1 Word2Vec

Сетевая структура Word2Vec в основном похожа на NNLM, но метод обучения отличается. NNLM заключается в том, чтобы вводить текст слова для предсказания слова, то есть видеть текст выше, чтобы предсказывать текст, а встраивание слов является побочным продуктом.
Word2Vec имеет два метода обучения:
- CBOW, основная идея состоит в том, чтобы удалить слово из предложения и использовать контекст и контекст слова, чтобы предсказать слово, которое было удалено;
- Skip-gram, который является полной противоположностью CBOW, вводит слово и просит сеть предсказать его контекстные слова.
Но цель Word2Vec другая, он просто для встраивания слов, это основной продукт, поэтому он может обучать сеть по желанию.
Встраивание Word — это процесс предварительной подготовки, как бы это сказать?
Это зависит от того, как использовать его в последующих задачах после изучения встраивания слов.
В NNLM каждое слово в предложении вводится в форме Onehot, а затем умножается на изученную матрицу встраивания слов Q, и вложение слов, соответствующее слову, напрямую извлекается. Q на самом деле представляет собой матрицу сетевых параметров, отображаемую из сетевого слоя Onehot в слой внедрения. Word Embedding эквивалентен инициализации сети из слоя Onehot в слой внедрения с предварительно обученной матрицей параметров Q. Просто Word Embedding инициализирует первый уровень сетевых параметров. Это типичная практика предварительного обучения в области НЛП 18-летней давности. Внедрение Word полезно для многих последующих задач NLP, но эффект не так хорош, почему?
Потому что проблема полисемии не рассматривается.
Какое негативное влияние полисемия оказывает на встраивание Word? Одно и то же слово имеет разные значения, но представлено одним и тем же вложением слова. Например, многозначное слово Bank имеет два часто используемых значения, но Word Embedding не может различить два значения при кодировании слова bank, что приводит к тому, что две разные контекстные данные кодируются в одно и то же пространство для встраивания слова go. Следовательно, встраивание слов не может различать различную семантику многозначных слов, что является его серьезной проблемой.
Хотя многие люди предлагали решения, но они дорогие или громоздкие, а ELMO предлагает простое и элегантное решение.
2.3.2 ЭЛМО
Внедрение слов до этого по сути является статическим методом.Так называемый статический означает, что выражение каждого слова фиксируется после обучения.При использовании в будущем, независимо от контекстного слова нового предложения, встраивание слов этого слово не изменится, оно будет меняться по мере изменения контекста сцены.
Основная идея ELMO заключается в следующем: я использую языковую модель, чтобы заранее изучить встраивание слова в слова, в настоящее время невозможно различить многозначные слова (смешанные с множественной семантикой). При фактическом использовании Word Embedded слово уже имеет определенный контекст. В настоящее время я могу настроить представление Word Embedded слова в соответствии с семантикой контекстного слова, чтобы скорректированное Word Embedded могло лучше выражать конкретный контекст в Это значение естественным образом решает проблему многозначности слов. Таким образом, ELMO сама по себе является идеей динамической настройки встраивания Word в соответствии с текущим контекстом.
ELMO использует типичный двухэтапный процесс,
- Первый этап заключается в использовании языковой модели для предварительного обучения;
- Второй этап заключается в извлечении встраивания слов каждого слоя сети, соответствующего слову, из предварительно обученной сети в качестве новой функции, дополняющей нисходящую задачу при выполнении нисходящей задачи.
Первый этап предварительной подготовки:

На приведенном выше рисунке показан процесс предварительного обучения. В его сетевой структуре используется двухуровневый двунаправленный LSTM. Текущая цель задачи обучения языковой модели — правильно предсказать слово W в соответствии с контекстом слова W. Последовательность слов перед W называется Context-before Above, следующая последовательность слов Context-after называется ниже.
Левый двухслойный LSTM является прямым кодировщиком, а входными данными является указанный выше контекст Context-before для прогнозирования W; правая сторона представляет собой обратный двухуровневый кодировщик LSTM, а входными данными является контекст-после предложения в обратном порядке. справа налево. Глубина каждого кодировщика представляет собой двухуровневый стек LSTM. Эта сетевая структура на самом деле очень часто используется в НЛП. Использование этой сетевой структуры и использование большого количества корпусов для выполнения задач языковой модели может предварительно обучить сеть.Если сеть обучена и вводится новое предложение Snew, каждое слово в предложении может получить три соответствующих вложения: нижний слой это слово Внедрение слова, вверх идет вложение, соответствующее позиции слова на первом уровне двунаправленного LSTM, которое содержит больше синтаксической информации для кодирования слов; дальше вверх находится вложение, соответствующее позиции слова на втором уровне LSTM , этот уровень кодирования Слова содержат больше семантической информации. Другими словами, процесс предварительного обучения ELMO не только изучает встраивание слов в Word, но также изучает двухуровневую двунаправленную сетевую структуру LSTM, и оба они пригодятся позже.
Фаза 2: Использование последующих задач
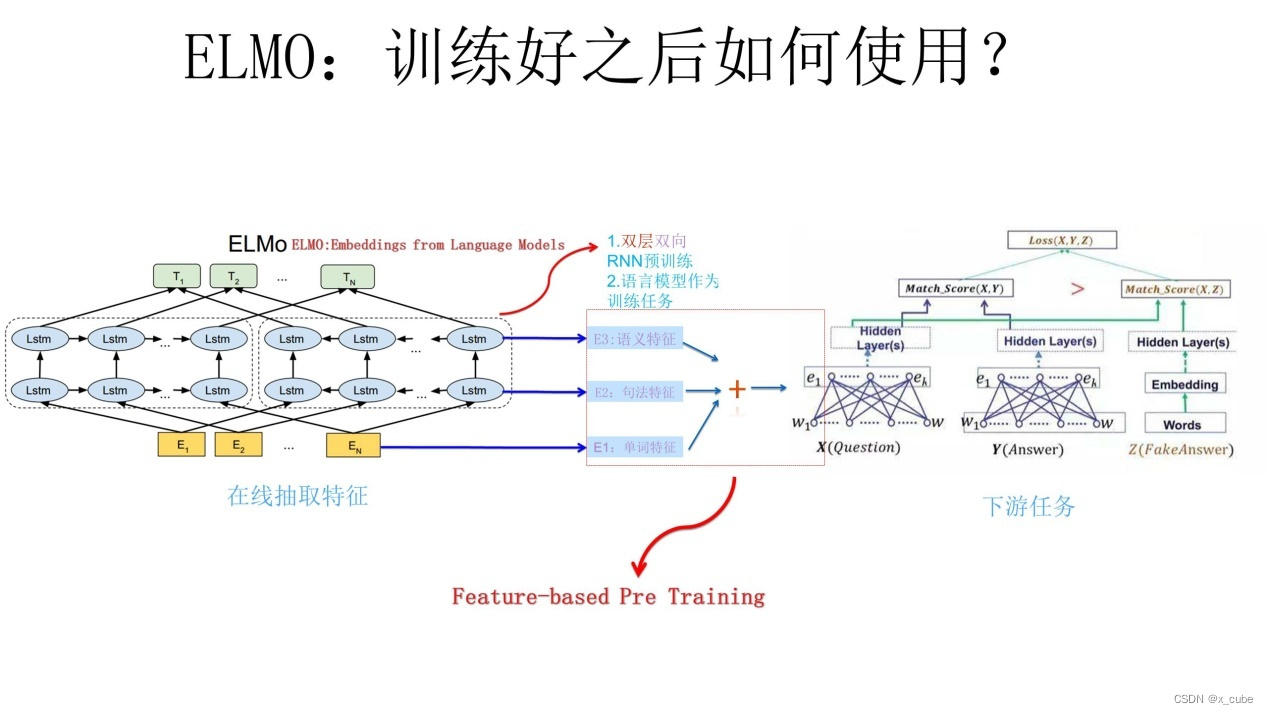
На рисунке выше показан процесс использования нисходящей задачи.Например, наша нисходящая задача - это проблема контроля качества.На данный момент для вопроса X введите его в предварительно обученную сеть ELMO, чтобы получить соответствующие три вложения, а затем дать три вложения Каждое вложение имеет вес А. Этот вес можно узнать, и три вложения объединяются в одно в соответствии с накоплением и суммированием их соответствующих весов. Затем используйте интегрированное встраивание в качестве ввода соответствующего слова в сетевой структуре предложения X и используйте его как дополнительную новую функцию для последующих задач. То же самое верно и для ответного предложения Y в нисходящей задаче QA, показанной на рисунке выше. Поскольку ELMO предоставляет форму признаков каждого слова нижестоящим, этот тип метода предварительного обучения называется «Предварительное обучение на основе признаков».
Эксперименты показывают, что задача охватывает широкий спектр, включая оценку семантических отношений предложений, задачи классификации, понимание прочитанного и другие области, что показывает, что диапазон ее применения очень широк, а ее универсальность сильна, что является очень хорошим преимуществом.
Каковы недостатки этого?
- Способность LSTM извлекать признаки намного слабее, чем у Transformer.
- Способность двухстороннего слияния элементов метода сращивания слабая.
В дополнение к методу предварительного обучения на основе слияния признаков, представленному ELMO, в НЛП существует еще одна типичная практика, которая выглядит согласующейся с полем изображения.Этот метод обычно называется «режим тонкой настройки», а GPT — это типичный пионер этого режима.
3 Трансформатор
3.1 GPT
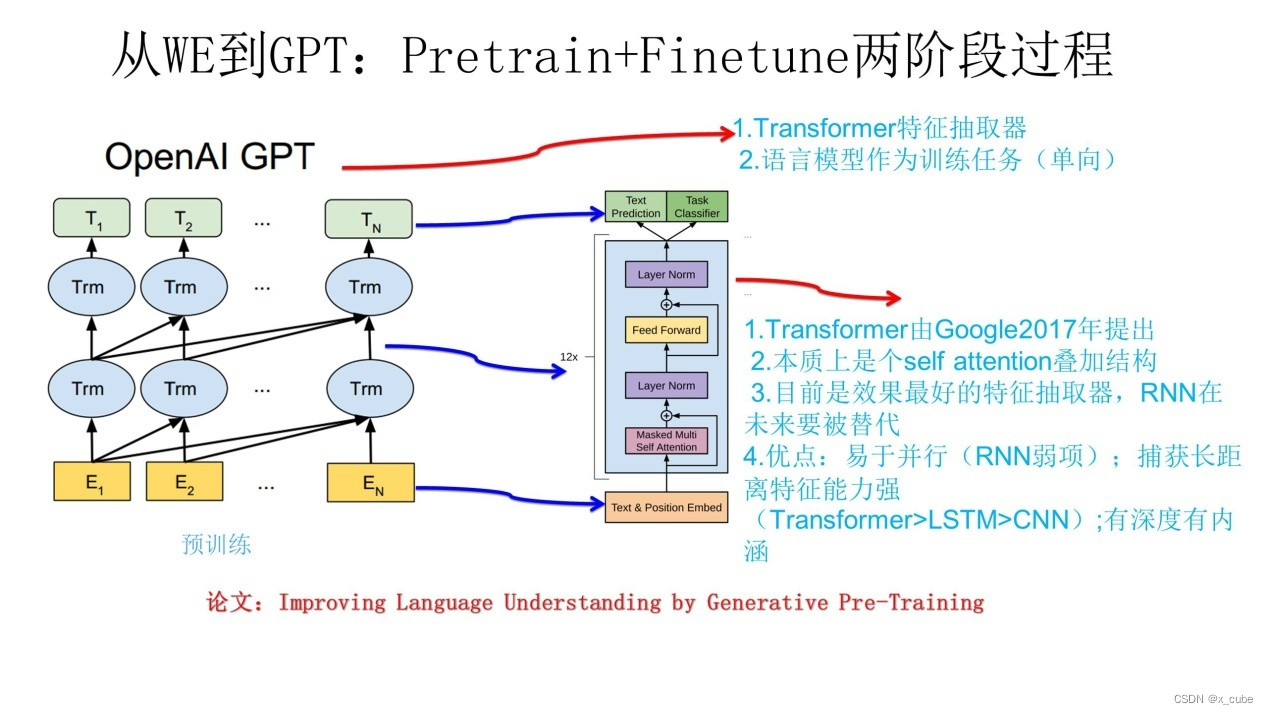
GPT — это аббревиатура от «Generative Pre-Training». Судя по названию, его значение относится к генеративному предварительному обучению. GPT также использует двухэтапный процесс,
- Первый этап заключается в использовании языковой модели для предварительного обучения.
- Второй этап решает последующие задачи в режиме тонкой настройки.
По сути он похож на ELMO, основное отличие заключается в двух моментах:
- Прежде всего, средство извлечения признаков не использует RNN, а использует Transformer.Как упоминалось выше, его способность извлечения признаков сильнее, чем RNN.Этот выбор, очевидно, очень разумен, Из-за последовательной зависимости его собственной структуры. Хотя CNN легко и быстро выполняет параллельные вычисления, у него есть естественные недостатки в захвате отношений последовательности НЛП, особенно функций на больших расстояниях. Это не невозможно, но не хорошо. Хотя есть много улучшенных моделей, не многие из них особенно успешны. Transformer также имеет хороший параллелизм и подходит для захвата объектов на большом расстоянии.
- Во-вторых, хотя предварительная подготовка GPT по-прежнему использует языковую модель в качестве целевой задачи, она использует одностороннюю языковую модель, а GPT использует только контекст перед словом для прогнозирования, игнорируя контекст. Этот выбор сейчас не очень хороший выбор, причина очень проста, он не интегрирует контекст слова, что ограничивает его действие в большем количестве сценариев применения и напрасно теряет много информации.

Для различных нисходящих задач вы можете произвольно спроектировать свою собственную сетевую структуру, но теперь вы не можете.Вы должны следовать сетевой структуре GPT и преобразовать сетевую структуру задачи, чтобы она была такой же, как сетевая структура GPT. Затем при выполнении последующих задач используйте параметры, предварительно обученные на первом этапе, для инициализации сетевой структуры GPT, чтобы лингвистические знания, полученные в ходе предварительного обучения, можно было внедрить в стоящую задачу, что очень хорошо. . Опять же, вы можете использовать поставленную задачу для обучения сети и тонкой настройки параметров сети, чтобы сделать сеть более подходящей для решения поставленной задачи.
Как мы можем преобразовать его для различных задач различных паттернов в НЛП, чтобы он был близок к сетевой структуре ТШП?
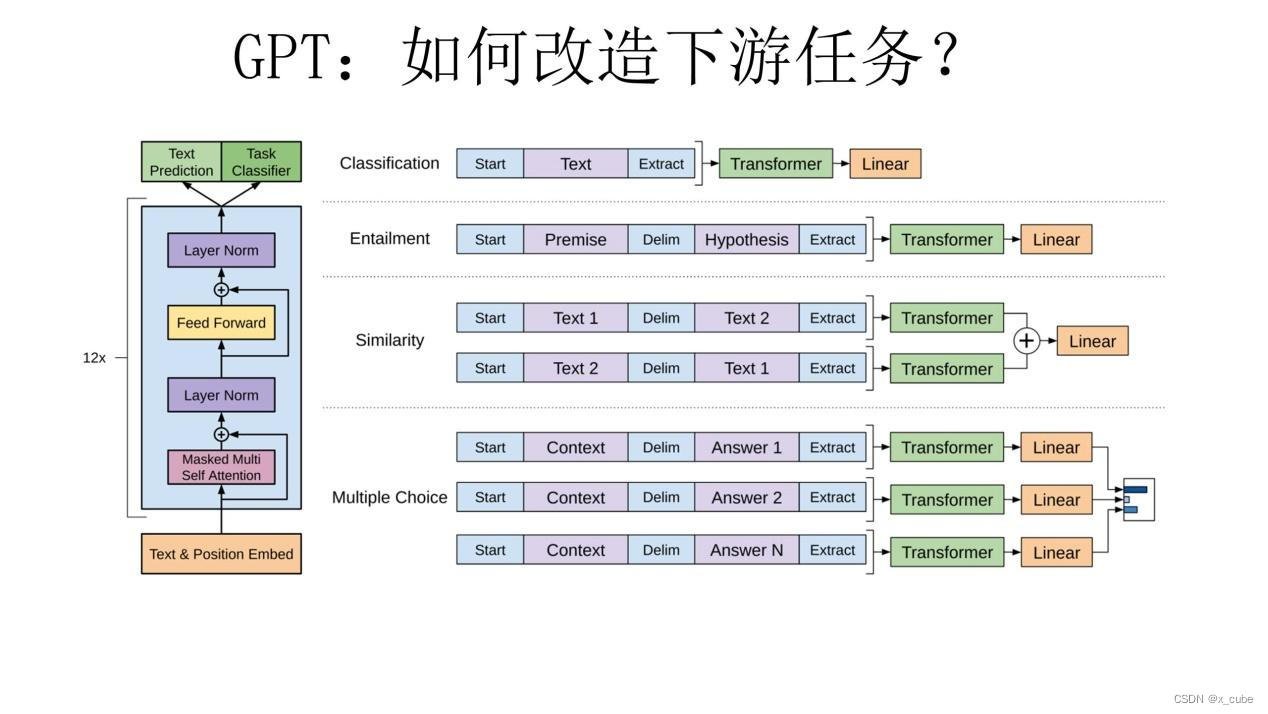
В документе GPT приведен приведенный выше чертеж конструкции преобразования, который на самом деле очень прост: для задач классификации вам не нужно много перемещаться, просто добавьте начальный и конечный символ; для задач суждения об отношениях предложений, таких как Entailment, добавьте Разделителя достаточно; для задачи оценки сходства текста просто измените порядок двух предложений и сделайте два ввода, чтобы сообщить модели, что порядок предложений не важен; для задач с множественным выбором несколько вводов, в каждом направлении Просто объединить статью и варианты ответа в качестве входных данных. Как видно из приведенного выше рисунка, это преобразование еще очень удобно, а разные задачи нужно строить только во входной части.
Эффект от GPT очень впечатляет: из 12 задач 9 добились наилучших результатов, а производительность некоторых задач значительно улучшилась.
Недостатки GPT:
- Языковые модели не являются двунаправленными
-
Способность хайпа слабая
3.2 Берт
Bert использует ту же двухэтапную модель, что и GPT: сначала выполняется предварительное обучение языковой модели, а затем используется режим тонкой настройки для решения последующих задач. Основное отличие от GPT заключается в том, что на этапе предобучения используется двусторонняя языковая модель, аналогичная ELMO.Конечно, еще один момент заключается в том, что размер данных языковой модели больше, чем у GPT. Так что о предтренировочном процессе Берта здесь говорить не приходится.
На втором этапе, этапе тонкой настройки, этот этап аналогичен GPT. Конечно, он также сталкивается с проблемой преобразования сетевой структуры подчиненных задач.Существуют некоторые различия между Bert и GPT с точки зрения преобразования задач.Вот краткое введение.

На рисунке выше приведен пример,
- Для задач связи между предложениями это очень просто, похоже на GPT, плюс начальный и конечный символы, а также разделитель между предложениями. Для вывода просто подключите слой классификации softmax к положению последнего слоя Transformer, соответствующего первому начальному символу.
- Для задач классификации, таких как GPT, необходимо добавить только начальный и конечный символы, а выходная часть и задача оценки соотношения предложений модифицируются аналогичным образом;
- Для задачи маркировки последовательности входная часть такая же, как и при классификации одного предложения, и для классификации требуется только соответствующая позиция каждого слова в последнем слое выходной части Transformer.
Отсюда видно, что среди четырех основных задач НЛП, перечисленных выше, кроме задач генерации, Берт покрывает все остальные, а трансформация очень проста и интуитивно понятна. Хотя в статье Берта это не упоминается, вы можете подумать об этом после небольшого мозгового штурма.На самом деле, для генеративных задач, таких как машинный перевод или суммирование текста, чат-роботы, вы также можете представить результаты предварительного обучения Берта с небольшой модификацией. Его нужно только присоединить к структуре S2S, часть кодера представляет собой структуру глубокого преобразователя, а часть декодера также представляет собой структуру глубокого преобразователя. Выберите различные данные предварительной подготовки в соответствии с задачей, чтобы инициализировать кодер и декодер. Это довольно интуитивный метод преобразования. Конечно, это также может быть проще, например, также можно напрямую установить скрытый слой на одной структуре Transformer для генерации вывода. В любом случае отсюда видно, что четыре основные категории задач НЛП могут быть легко преобразованы в метод, приемлемый для Берта. На самом деле это очень большое преимущество Берта, а это значит, что он может выполнять почти любую задачу НЛП ниже по течению, и он универсален, что очень сильно.

Bert на самом деле неразрывно связан с ELMO и GPT, например, если мы заменим этап предварительного обучения GPT на двунаправленную языковую модель, то мы получим Bert, а если мы заменим экстрактор признаков ELMO на Transformer, то мы также получим Bert. Итак, вы можете видеть: два наиболее важных пункта Берта заключаются в том, что экстрактор признаков использует Transformer; второй пункт — использование двунаправленной языковой модели во время предварительного обучения.
Для Transformer, как мы можем выполнять задачи двунаправленной языковой модели в этой структуре? Напрямую заменить LSTM на Transformer?
Основная идея CBOW заключается в следующем: при выполнении задач языковой модели я вырезаю слово, которое нужно предсказать, а затем предсказываю слово в соответствии с его контекстом выше-до и ниже контекста-после. Как Берт на самом деле сделал это? Берт так и сделал. Отсюда вы можете увидеть отношения наследования между методами. Автор Берта сказал, что его вдохновила задача закрыть. Поэтому у Берта на самом деле не так много инноваций с точки зрения моделей, и он больше похож на мастера важных технологий НЛП последних лет.
Итак, какие инновации есть у самого Берта в плане моделей и методов? Это модель языка в маске, указанная в статье (детали изменились) и прогнозирование следующего предложения.
Модель маскированного языка: случайным образом выберите 15% слов в корпусе и вырежьте их, то есть замените исходные слова маской [Mask], а затем попросите модель правильно предсказать слова, которые были вырезаны. Но здесь есть проблема: в процессе обучения видно много меток [маски], но этой метки не будет, когда она будет фактически использована позже, что заставит модель думать, что вывод для [маски ] знак, но см. также для фактического использования.Если он меньше этого знака, естественно, будут проблемы. Чтобы избежать этой проблемы, Берт сделал преобразование: из 15% слов, выбранных Богом для выполнения славной задачи [маски], только 80% были фактически заменены знаками [маски], а 10% были заменены случайным образом. виверры для принцев.Другим словом, 10% времени слово остается на месте без изменений. Это особый подход модели двусторонней речи в маске.
Предсказание следующего предложения: при предварительном обучении языковой модели выберите два предложения в двух ситуациях,
- Один состоит в том, чтобы выбрать два предложения, которые действительно последовательно связаны в корпусе;
- Другой заключается в том, что второе предложение выбрасывает кости из корпуса и случайным образом выбирает одно из них, которое будет написано за первым предложением.
Нам требуется, чтобы модель выполняла вышеупомянутую задачу модели маскированного языка и делала прогноз отношений предложений, чтобы судить, действительно ли второе предложение является последующим предложением первого предложения. Причина этого в том, что многие задачи НЛП представляют собой задачи на оценку отношения предложений, а обучение детализации предсказания слов не может достичь уровня отношений предложений Добавление этой задачи полезно для последующих задач оценки отношений предложений. Таким образом, можно увидеть, что его предварительная подготовка представляет собой многозадачный процесс. Это тоже нововведение Берта.
Сравнительные эксперименты могут доказать, что по сравнению с GPT двусторонняя языковая модель играет наиболее важную роль, особенно для тех задач, в которых нужно видеть следующее. Для предсказания следующего предложения влияние на общую производительность не слишком велико, и оно имеет высокую степень корреляции с конкретными задачами.
Подведем итог:
- Первый представляет собой двухэтапную модель.Первый этап представляет собой предварительную подготовку двусторонней языковой модели.Здесь обратите внимание на использование двустороннего вместо одностороннего.Второй этап использует конкретную задачу Тонкая настройка или интеграция функций;
- Во-вторых, использовать Transformer в качестве экстрактора признаков вместо RNN или CNN для извлечения признаков;
- В-третьих, двустороннюю языковую модель можно сделать методом CBOW (конечно, я думаю, что это вопрос деталей, не слишком критично, первые два фактора более критичны).
Самой большой изюминкой Берта является его хороший эффект и сильная универсальность.Почти все задачи НЛП могут быть применены к двухэтапному решению Берта, и эффект должен быть значительно улучшен. Можно предвидеть, что Transformer будет доминировать в области приложений НЛП в будущем, и этот двухэтапный метод предварительного обучения также будет доминировать в различных приложениях.
Процесс предварительного обучения, по сути, состоит в том, что он делает.По сути, предварительное обучение заключается в разработке сетевой структуры для выполнения задач языковой модели, а затем в использовании большого количества даже бесконечных неразмеченных текстов на естественном языке. Использование Большой объем лингвистических знаний извлекается и кодируется в сетевой структуре Когда данные с аннотационной информацией для решаемой задачи ограничены, эти априорные лингвистические особенности, конечно, будут иметь большое дополнительное влияние на решаемую задачу, потому что когда данные ограничены, многие лингвистические явления не могут быть охвачены, а способность к обобщению слаба.Интеграция как можно более общих лингвистических знаний, естественно, усилит способность модели к обобщению. Как ввести предварительные лингвистические знания всегда было одной из основных целей НЛП, особенно НЛП в сценариях глубокого обучения, но не было хорошего решения, и двухэтапная модель ELMO/GPT/Bert, несомненно, кажется естественной. и лаконичный способ решения этой задачи, что и является главной ценностью этих методов.
3.3 РОБЕРТа
Оригинальная модель Берта представляет собой незаконченный полуфабрикат, а RoBERTa — готовый продукт, основанный на идеях Берта. RoBERTa считается полностью обученной моделью Берта, и эта небольшая разница может значительно улучшить эффект оригинальной модели Берта. На основе оригинальной модели Берта Роберта.
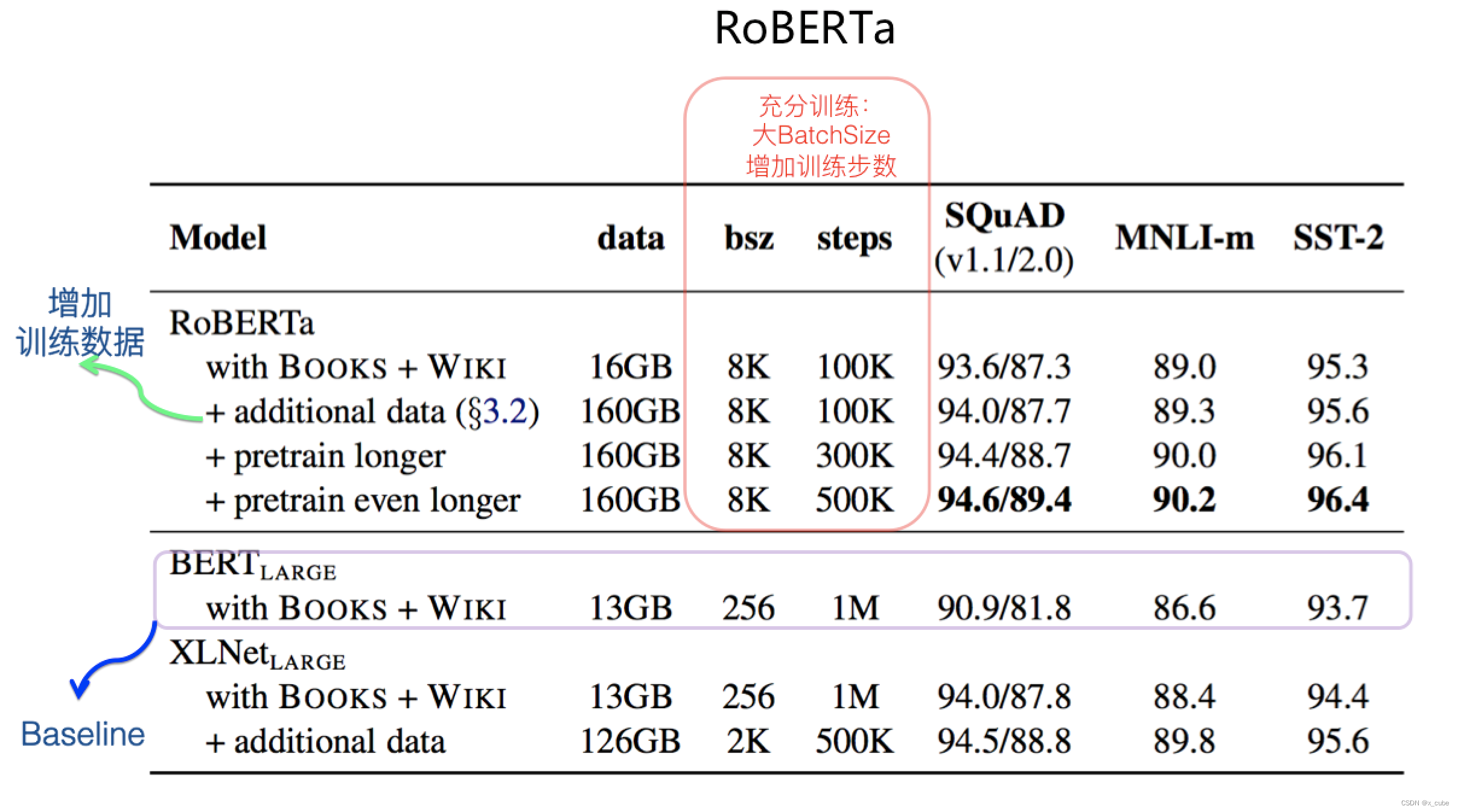
- Дальнейшее увеличение количества данных для предварительной подготовки может улучшить эффект модели;
- Увеличение времени предварительного обучения или увеличение количества шагов предварительного обучения может улучшить эффект модели;
- Резко увеличить размер партии каждой партии предварительной подготовки, что может значительно улучшить эффект модели;
- Удалите подзадачу «Предсказание следующего предложения» в задаче перед обучением, она не должна существовать; (небольшое влияние)
- Стратегия динамического маскирования вводимого текста полезна (не сильно влияет)
Почему RoBERTa является надежным эталоном для предварительно обученных моделей?
- Во-первых, хотя кажется, что RoBERTa не внесла никаких технических или модельных улучшений, она просто более полно обучила модель Берта, но ее эффект очень хороший.
- Во-вторых, для улучшенной модели, по идее, RoBERTa должен быть введен как базовый уровень сравнения, и если эффект улучшенной модели не может быть убедительно превзойден RoBERTa, то эффективность этого улучшения более или менее проблематична, если только Вы не подчеркнули, что преимущество улучшения модели не в эффекте, а в других аспектах, таких как меньше и быстрее.
- В-третьих, последующая улучшенная модель предварительной подготовки, со стратегической точки зрения, должна стоять на гигантских плечах RoBERTa в начале проектирования, то есть увеличивать Размер партии и удлинять время предварительной подготовки. на предпосылке увеличения определенного количества данных, Пусть модель будет полностью обучена. Потому что, если вы этого не сделаете, есть большая вероятность, что ваш эффект будет трудно сравнить с RoBERTa.Однако, если вы изучите модели с выдающимися эффектами, которые мы можем видеть до сих пор, вы обнаружите, что они на самом деле имеют представил ключевые элементы RoBERTa.
Большинство текущих основных моделей используют Transformer в качестве экстрактора признаков, но как использовать его для построения структуры модели с более высокой эффективностью обучения? это проблема. Так называемая высокая эффективность обучения означает, что при одинаковом размере обучающих данных он может закодировать в модель больше знаний, а это означает, что его эффективность обучения выше. Различные варианты использования Transformer будут создавать разные структуры моделей, что приведет к дифференцированной эффективности обучения разных структур. Существующие исследовательские выводы о структуре модели представят пять общих структур модели, которые обычно включают в себя методы обучения с самостоятельным наблюдением.Обычные методы обучения включают автокодирование (сокращенно AE) и авторегрессию (сокращенно AR). AE — это то, что мы часто называем двусторонней языковой моделью, в то время как AR означает одностороннюю языковую модель слева направо.
4 . Си-Эн-Эн
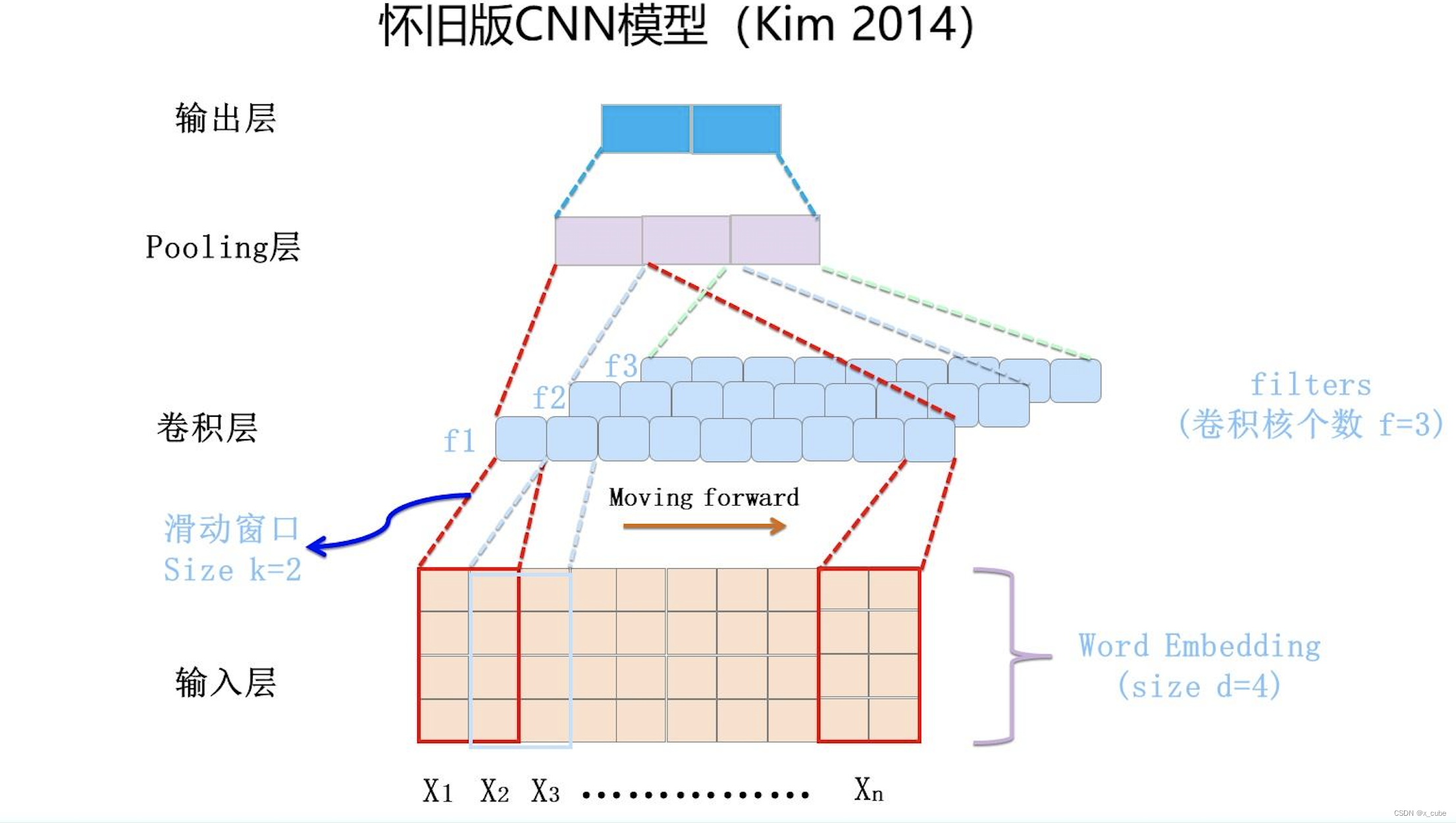
Самым ранним введением CNN в НЛП была работа, проделанная Кимом в 2014 году. См. рисунок выше для описания документа и структуры сети.
Слой свертки — это, по сути, слой извлечения признаков, и гиперпараметр F можно установить, чтобы указать, сколько ядер свертки (фильтр) содержит слой свертки. Для определенного фильтра возможно наличие d*k движущегося окна, которое перемещается назад от первого слова входной матрицы, где k — размер окна, заданный фильтром, а d — длина встраивания слов. Для окна в определенный момент посредством нелинейного преобразования нейронной сети входное значение в этом окне преобразуется в определенное значение характеристики.По мере того, как окно продолжает двигаться назад, непрерывно генерируется соответствующее значение характеристики Фильтра для сформировать фильтр Вектор признаков. Это процесс извлечения ядра свертки. Каждый фильтр в сверточном слое работает таким образом, чтобы сформировать другую последовательность признаков. Слой объединения выполняет операции уменьшения размерности объектов фильтра для формирования окончательных объектов. Как правило, полностью связанная нейронная сеть слоя подключается после слоя объединения для формирования окончательного процесса классификации.
Это рабочий механизм модели CNN, впервые примененный в области НЛП.Он используется для решения задачи классификации предложений в НЛП.Он кажется очень простым.После этого одна за другой появились усовершенствованные модели на его основе. Но CNN не так хорош, как RNN в области НЛП. Это показывает, что эта версия CNN все еще имеет много проблем.На самом деле, самая основная проблема заключается в том, что новая среда не внесла целенаправленных изменений в характеристики новой среды, поэтому она сталкивается с проблемой акклиматизации.
Вопрос: ключ лежит в скользящем окне, охватываемом ядром свертки. Функции, которые может захватить CNN, в основном отражаются в этом скользящем окне. То, что он захватывает, - это информация фрагмента k-граммы слова. Размер k определяет, сколько он может запечатлеть отдаленные черты. Многие люди улучшают это. Какова текущая основная CNN НЛП?

Обычно на глубину накладывается одномерный сверточный слой, и для помощи в оптимизации используется Skip Connection.Также могут быть введены расширенные CNN и другие методы.
Справочная статья:
ПТМ на ветру и волнах: технический прогресс предтренировочной модели за последние два года