ДН-ДЕТР (CVPR 2022)
Ускорьте обучение DETR, внедрив шумоподавление запросов
Нестабильность венгерского сопоставления приводит к противоречивым целям оптимизации на раннем этапе обучения.
Для одного и того же изображения запрос будет соответствовать разным объектам в разное время.
DN-DETR добавляет шум на реальные GT: xywh, label
Технология шумоподавления используется для ускорения обучения сети, а обучение detr рассматривается как два процесса:
- изучение хороших якорей
- изучение относительных смещений
Модель
DN: шумоподавление
Шумоподавление — это всего лишь метод обучения, он не меняет структуру модели , а лишь вносит некоторые изменения во время ввода.
Внедрение декодера представлено как метка с добавленным шумом, а привязка представлена как bbox с добавленным шумом.
Для исходной соответствующей части DETR мы можем добавить метку [Неизвестно], чтобы отличить ее, а часть привязки останется такой же, как у DETR.
Индикатор определяет, находится ли встраивание в исходном 300quey или добавлен зашумленный GT.
Обучаемые привязки: для обычного запроса 300 здесь передается параметр внедрения. Если он удаляет шум GT, это значение GT с шумом.
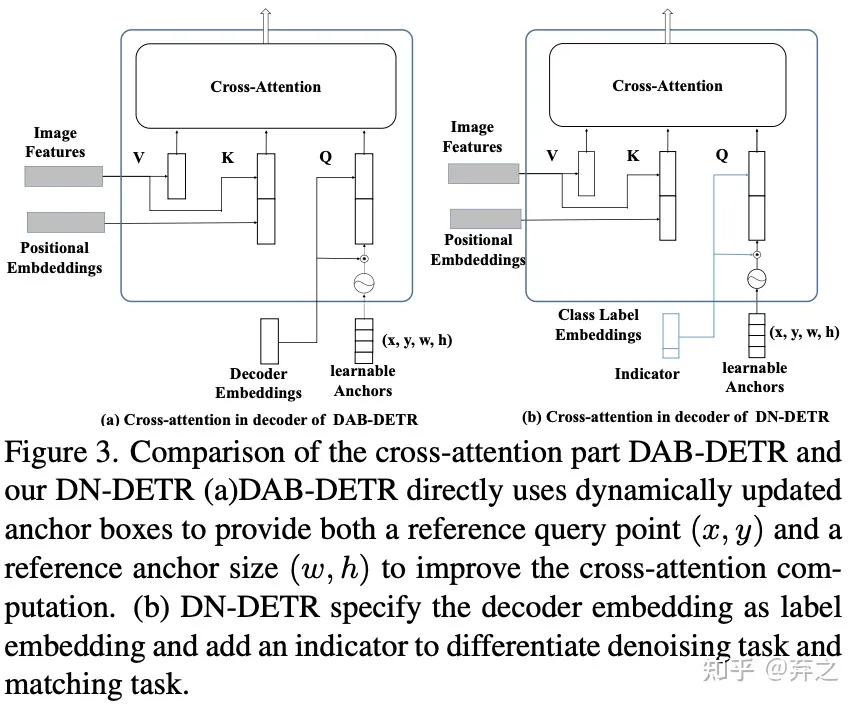
о знак равно ( D ) ( q , F ∣ А ) ( перекрестное внимание - DAB - DETR ) о = (\ mathbf {D}) (\ mathbf {q}, F \ Mid A) (перекрестное внимание-DAB-DETR) )о"="( D ) ( q ,Ф∣А ) (крест−внимание _ _ _ _ _ _ _−Д А Б−D ETR )
o: выход декодера, D: декодер, q: запрос, F: кодировщик 输出, A: маска внимания
Запрос декодера состоит из двух частей. Одна из них — соответствующая часть. Входными данными для этой части являются обучаемые якоря, которые обрабатываются так же, как DETR. То есть часть сопоставления использует сопоставление двудольного графа и учится аппроксимировать пары GT-блок-метка с соответствующими выходными данными декодера. Другая часть — это часть шумоподавления. Входными данными для этой части являются зашумленные пары GT-блок-метка, называемые в остальной части статьи объектами GT. Выходные данные части шумоподавления направлены на восстановление объекта GT
o = D ( q , Q , F ∣ A ) \mathbf{o}=D(\mathbf{q}, \mathbf{Q}, F \mid A)о"="Д ( д ,Вопрос ,Ф∣A )
o: выход декодера, D: декодер, q: GT с шумом, Q: запрос 300, F: выход кодера, A: маска внимания
шумоподавление
обратите внимание, что шумоподавление учитывается только при обучении , во время вывода часть шумоподавления удаляется, остается только соответствующая часть.
Тип шума:
-
Как присоединиться?
-
Когда это считается?
-
Для каждого изображения мы собираем все объекты GT и добавляем случайный шум как к их ограничивающим рамкам, так и к меткам классов.
-
**шум коробки:** смещение координат центра (не выходящее за диапазон исходного GT), масштабирование координат высоты и ширины (может не масштабироваться синхронно)
Потери: потеря L1, потеря GIOU (добавленный кадр шумоподавления и 300 запросов не требуют венгерского сопоставления для расчета потерь. GT, соответствующий рудному телу шумоподавления, известен (?))
-
**шум надписей**: случайные изменения в надписях,
Потеря: потеря фокуса
Маска внимания
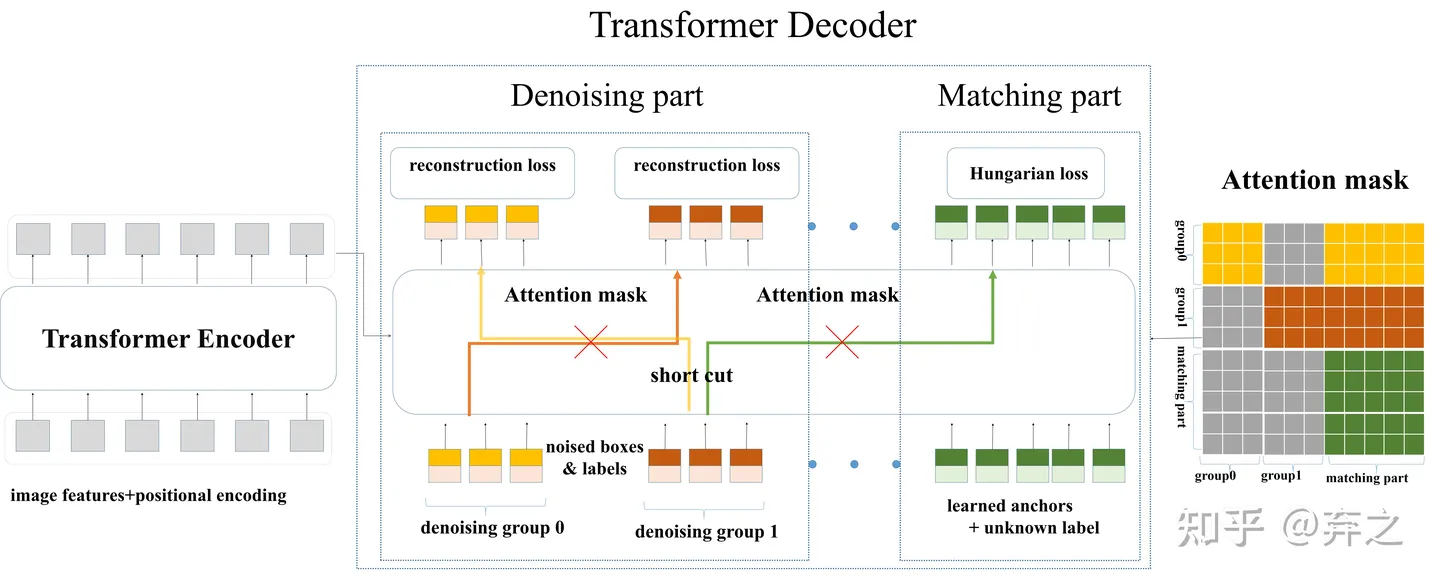
После добавления шумоподавления входные данные модели становятся такими, как показано ниже. Мы называем соответствующую часть исходного DETR «Соответствующая часть», а вновь добавленную часть шумоподавления — «Часть шумоподавления». Следует отметить, что часть шумоподавления необходимо добавлять только во время обучения. Часть шумоподавления будет удалена непосредственно во время вывода, как и в исходной модели. Следовательно, объем вычислений не будет увеличиваться во время вывода, а будет лишь небольшая сумма. данных необходимо добавить во время обучения.объем расчета
Следовательно, каждый запрос в части шумоподавления может быть представлен как qk = δ ( tm ) qk = δ(t_m)q k"="д ( тм) где tm — этоm − th m-thм−t h GT объект
q = { g 0 , g 1 , . . . . , g P − 1 } где gp — p-я группа шумоподавления gp = { q 0 p , q 1 p , . . . . , q M − 1 p } M = сумма GT в bs\begin{aligned}\mathbf{q}&=\{\mathbf{g_0},\mathbf{g_1},....,\mathbf{g_{P-1} }\ } где g_p — p-я группа шумоподавления \\\mathbf{g_p}&=\begin{Bmatrix}q_0^p,q_1^p,....,q_{M-1}^p\end{ Bmatrix}M = Сумма GT в bs\end{aligned}дгп"="{
г0,г1,.... ,гП − 1} где g _ _пнаходится ли группа p в gg group _ _ _ _ _ _ _"="{
д0п,д1п,.... ,дМ - 1п}М"="Сумма GT в б с
aij знак равно { 1 , если j < P × M и ⌊ i M ⌋ ≠ ⌊ j M ⌋ ; 1, если j < P × M и я ≥ P × M; 0, иначе. \left.a_{ij}=\left\{\begin{array}{ll}1,&\text{if }j<P\times M\text{ и }\lfloor\frac{i}{M}\ rfloor\neq\lfloor\frac{j}{M}\rfloor;\\1,&\text{if }j<P\times M\text{ и }i\ge P\times M;\\0,& \text{иначе.}\end{array}\right.\right.аij"="⎩ ⎨ ⎧1 ,1 ,0 ,если j<п×М и ⌊Мя⌋"="⌊Мдж⌋ ;если j<п×М и я≥п×М ;иначе .
Помимо добавления шума, нам необходимо добавить дополнительную маску внимания к самовниманию декодера, чтобы предотвратить утечку информации. Поскольку часть шумоподавления содержит информацию о реальном блоке и реальной метке, непосредственный просмотр соответствующей части части шумоподавления приведет к утечке информации. Таким образом, соответствующая часть не может видеть часть с шумоподавлением во время обучения и обучается так же, как исходная модель. Независимо от того, видите ли вы дополнительную часть шумоподавления или не видите соответствующую часть, это мало влияет на результаты, поскольку часть шумоподавления содержит наиболее реальные поля и метки.
Левая часть используется для реконструкции, а 300 запросов в правой части используются для сопоставления на венгерском языке.
Утечка информации:
1.соответствующая часть, чтобы увидеть группу
2.Между группами
Почему маска внимания не предотвращает группировку и сопоставление?
Встраивание меток (встраивание декодера)
Это не имеет никакого отношения к лейблу, разница в названии.
Внедрение декодера указывается как внедрение метки в модель для поддержки шумоподавления поля и шумоподавления меток.К
внедрению метки также добавляется индикатор (последнее измерение тензора плюс идентификатор). Этот индикатор равен 1, если запрос относится к части шумоподавления, и 0 в противном случае.
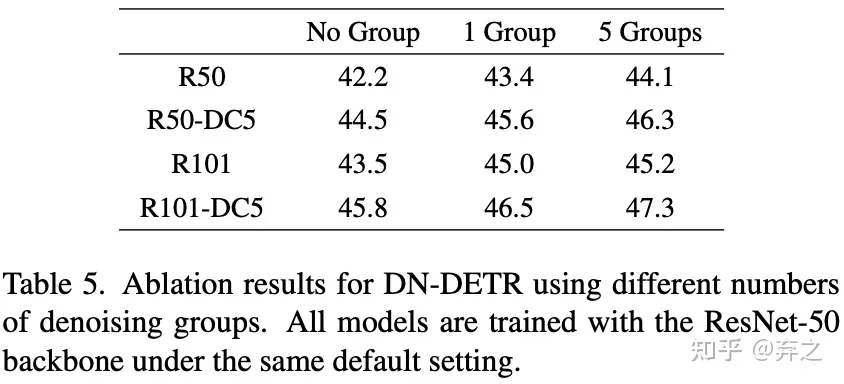
эксперимент по абляции
Без маски внимания результат очень низкий.