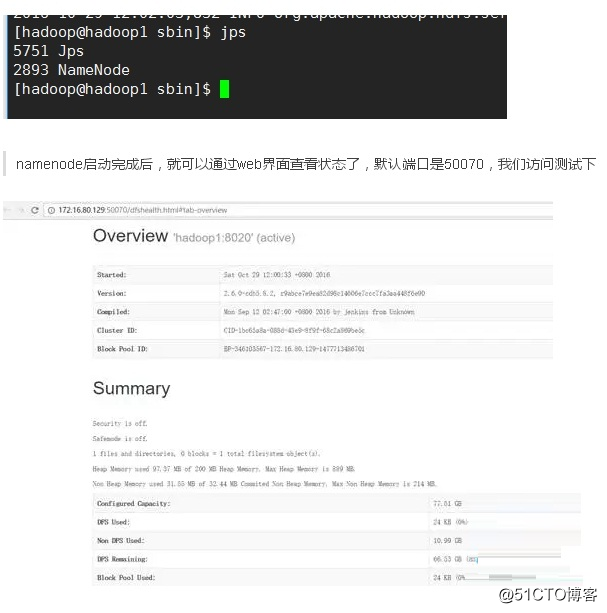
1, Hadoop экологический профиль
Hadoop является Фонд Apache, разработанный распределенной системой интеграции архитектуры, пользователь может не знать, в основных деталях распределенного случае, разработка распределенных программ, в полной мере использовать мощность кластера для высокоскоростных вычислений и хранения, надежных, эффективных, Телескопическая функции
Ядро Hadoop является ПРЯЖИ, HDFS, MapReduce, общая модульная архитектура следует
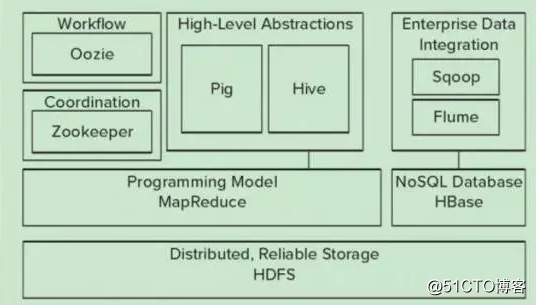
2, HDFS
ГФС документы из Google, и опубликовано в октябре 2013 года, HDFS версия клона GFS, HDFS является основой для системы управления хранением данных Hadoop, который является в высшей степени отказоустойчивой системы, которая может обнаруживать и реагировать на аппаратные сбоев
Консистенция файла HDFS упрощает модель, с помощью потокового доступа к данным, обеспечивает данные приложений доступа с высокой пропускной способностью для приложений с большими наборами данных, который обеспечивает механизм для однократной записи чтения много раз, блок данных образуют, в то время как в другом физическом кластере машины
3, MapReduce
Полученный из бумаги MapReduce Google, рассчитывается для большого количества данных, который экранирует распределенные вычислительные инфраструктуры детали, расчет карты и снизить отведенной на две части
4, HBase (колонка памяти распределенной базы данных)
Bigtable бумага от Google, встроенный в верхней части HDFS, колонки-ориентированных данных для структурированных масштабируемой, высоконадежные, высокопроизводительные колонки-ориентированной распределенной и динамический режим базы данных
5, зоопарк
Решение проблем управления данными в распределенной среде, единого имени, синхронизации состояний, управление кластером, синхронизации конфигурации
6, HIVE
Доход от Facebook, определяет подобный язык запросов SQL, SQL будет преобразован в задачи MapReduce, выполняемых в Hadoop выше
7, желоб
инструмент сбора Вход
8, пряжа распределены менеджеры ресурсов
Это следующий MapReduce поколения, в основном решить исходную плохую масштабируемость Hadoop, разнообразие вычислительной структуры не поддерживает предлагаемую архитектура следует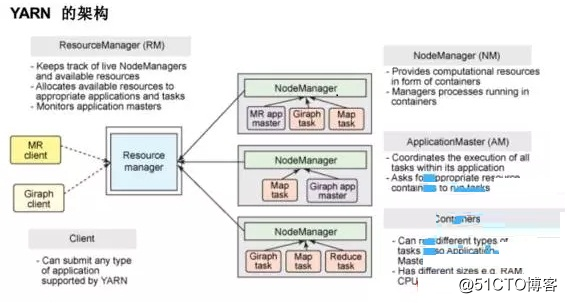
Концепция больших объемов данных и искусственного интеллекта являются неточными, в соответствии с тем, что линия, чтобы узнать, где завершение разработки, хотят учиться, хотят учиться студенты приветствуют присоединиться к Big Data обучения юбки: 606 859 705, есть много сухих грузов (ноль базовый и продвинутый боевой классический) доля для всех, так что мы знаем, наиболее полный большой внутренний высокого класса реальной практической системы процесса обучения данных. Начиная с Java и Linux, а затем постепенно глубоко в Hadoop-улей-oozie-веб-лотковый-питон-HBase-Кафка-СПАРК-Скала одиннадцать других связанных с ними знаний, чтобы поделиться!
9, искра
искра обеспечивает более быструю и универсальную платформу обработки данных, и сравнение Hadoop, искра может сделать вашу программу работы в памяти
10, Кафка
Распределенные очереди сообщений, в основном для потоковой обработки данных Активной
11, Hadoop псевдо-распределенного развертывания
На данный момент нет версии заряд Hadoop Там не три, все иностранные производители, а именно
1, Apache оригинальная версия
2, версия CDH, для домашних пользователей, подавляющее большинство выбранной версии
3, HDP версия
Здесь мы выбираем CDH версия Hadoop-2.6.0-cdh5.8.2.tar.gz, среда CentOS7.1, JDK 1.7.0_55 необходимость более
[Корень @ hadoop1 ~] # useradd Hadoop
Моя система поставляется с Java по умолчанию среды является
Добавьте следующие переменные окружения

Выполните следующие действия разрешения

Здесь пользователи Hadoop для управления различных услуг и запуском Hadoop

Посмотреть сервис начинает обстоятельства