Нейронные сети
«Один алгоритм обучения» гипотеза
- Эксперименты Нейрон-Перетелеграфирование
Модель Представление
определять
- Сигмовидной (логистическая) функция активации
- блок смещения
- входной слой
- выходной слой
- скрытый слой
- \ (A_i ^ {(к)} \): '' активации единичного \ (\ я) в слое \ (к \)
- \ (\ Theta ^ {(к)} \): матрица весов, контролирующих функцию отображения из слоя \ (\ J) к слою \ (к + 1 \).
подсчитывать
\ [а ^ {(к)} = (г ^ {(к)}) \]
\ [г (х) = \ гидроразрыва {1} {1 + е ^ {- х}} \]
\ [г ^ {(J + 1)} = \ Theta ^ {(к)} а ^ {(к)} \]
\ [H_ \ тета (х) = а ^ {(J + 1)} = (г ^ {( J + 1)}) \]
Стоимость Функция
\ [
J (\ Theta) = - \ гидроразрыва {1} {т} \ sum_ {= 1} ^ т \ sum_ {к = 1} ^ К \ влево [у ^ {(я)} _ к \ лог (( h_ \ Theta (х ^ {(я)})) _ к) + (1 - у ^ {(я)} _ к) \ лог (1 - (h_ \ Theta (х ^ {(я)})) _ к) \ вправо] + \]
\ [\ гидроразрыва {\ Lambda} {2m} \ sum_ {л = 1} ^ {L-1} \ sum_ {= 1} ^ {s_l} \ sum_ {J = 1} ^ {S_ {L + 1} } (\ theta_ {J, I} ^ {(л)}) ^ 2
\]
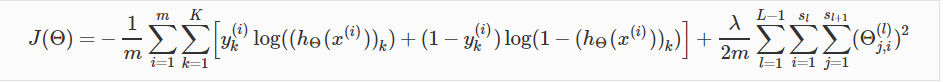

Обратного распространения Алгоритм
Алгоритм
- Гипотезы мы рассчитали все \ (а ^ {(л)} \) и \ (г ^ {(л)} \)
- множество \ (\ Delta ^ {(л)} _ {I, J} = 0 \) для всех (л, I, J)
- используя \ (у ^ {(т)} \), вычислить \ (\ Delta ^ {L} = а ^ {(Л)} - у ^ {(т)} \), где \ (у ^ {(т) } _ {k} (я) \ в {0, 1} \) указывает на то, принадлежит ли текущий пример обучения для класса к {\ (у ^ {(т)} _ {к} (к) = 1 \)}, или если оно принадлежит к другому классу = 0;
- Для скрытого слоя \ (L = L - 1 \) до 2, набор
\ [
\ дельта ^ {(л)} = (\ Theta ^ {(л)}) ^ Т \ дельта ^ {(L + 1) }. * г '(г ^ {(л)})
\] - забываю удалить \ (\ delta_0 ^ {(л)} \) путем.
delta(2:end)
\ [
\ Delta ^ {(л)} = \ Delta ^ {(л)} + \ дельта ^ {(L + 1)} (а ^ {(л)}) ^ Т
\] - градиент
\ [
\ гидроразрыва {\ парциальное} {\ парциальное \ Theta ^ {(л)} _ {I, J}} J (\ Theta) = D ^ {(л)} _ {I, J} = \ гидроразрыва { 1} {т} \ Delta ^ {(л)} _ {I, J} +
\ начинают {случаи} \ гидроразрыва {\ Lambda} {т} \ Theta ^ {(л)} _ {I, J}, & \ текст {если J $ \ GEQ $ 1} \\ 0, & \ текст {если J = 0} \ конец {случаи}
\]
Градиент Поверка
- \ [
\ Гидроразрыва {d} {d \ Theta} J (\ Theta) \ ок \ гидроразрыва {J (\ Theta + \ эпсилон) - J (\ Theta - \ эпсилон)} {2 \ эпсилон}
\] - Малое значение для \ (\ \ эпсилон), такие как \ (\ эпсилон = 10 ^ {- 4} \)
- проверьте, что gradApprox \ (\ ок \) deltalVector
4.
epsilon = 1e-4;
for i = 1 : n
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus)) / (2 * epsilon);
end;
Прокатка и разворачивание
Случайная инициализация
Theta = rand(n, m)) * (2 * INIT_EPSILON) - INIT_EPSILON;
- инициализировать \ (\ Theta ^ {(л)} _ {IJ} \ в [- \ эпсилон \ эпсилон] \)
- иначе, если мы инициализация все тета весов к нулю, все узлы будут обновлены до того же значение, когда мы неоднократно back_propagate.
- Одна из эффективных стратегий выбора \ (\ epsilon_ {INIT} \) является основывать количество единиц в сети. Хороший выбор \ (\ epsilon_ {INIT} \) является \ (\ epsilon_ {} = INIT \ гидроразрыва {\ SQRT {6}} {\ SQRT {L_ {в} + {L_ вне}}} \)
Обучение нейронной сети
- Случайным инициализации весов
Theta = rand(n, m) * (2 * epsilon) - epsilon;
- Реализация прямого распространения, чтобы получить \ (H_ \ Theta (х ^ {(я)}) \) для любого \ (х ^ {(я)} \)
- Реализовать код для вычисления функции затрат \ (J (\ Theta) \)
Реализовать обратно-проп вычислить частные производные \ (\ гидроразрыва {d (J \ Theta)} {d \ theta_ {JK} ^ {(л)}} \)
- \ (G «(г) = \ д {гидроразрыва} {дг} г (г) = г (г) (1 - (г)) \)
- \ (Сигмовидной (г) = г (г) = \ гидроразрыва {1} {1 + е ^ {-} г} \)
С помощью проверки для сравнения градиента \ (\ гидроразрыва {d (J \ Theta)} {d \ theta_ {JK} ^ {(л)}} \) вычисляется с использованием обратного распространения против используя численную оценку градиента \ (J ( \ Theta) \)
Затем отключите градиентной проверочный кодИспользование градиентного спуска или усовершенствованный метода оптимизации с обратным распространением, чтобы попытаться свести к минимуму \ (J (\ Theta) \) как функция от параметров \ (\ Theta \)