Рептилия курсы:
. Рептилия основных принципов двух основных принципов запроса библиотеки .requests рептилий
1. Что такое рептилии
Гусеничный ползают данные 2. Что такое Интернет
Стек сетевого устройства, к компьютеру станции соединены с Интернетом вместе называют 3. Цель создания Интернет
Общая передача данных и данных 4. Данные , что
Например: данные о продукции ссылку электронного бизнес - платформу, информация ...
- Что такое Интернет? Обычные пользователи
Откройте браузер
→ Введите адрес
Отправка запроса на целевой хост →
→ Данные возврата ответа
→ Данные рендеринга в браузере
Гусеничный: Аналоговый браузер
Отправка запроса на целевой хост →
→ Данные возврата ответа
→ разобрать и извлечь ценные данные,
→ сохранить данные (файлы, записанные на локальные, постоянная базу данных)
- Рептилия весь процесс
1. Отправить запрос (Библиотека: запросы / селен) 2. выборки данных ответа
- Данные анализа (разбора библиотеки: beautifulSoup4)
- Сохранение данных (хранилище: Файл Сохранить / MongoDB)
Резюме: Мы можем использовать данные интернет-уподобить клад копать клад это на самом деле рептилий
Два .request запроса библиотека 1. Установка и использование
PIP3 установить запросы
Запрос Анализ процесса (аналоговый браузер)
- Baidu «1. URL запроса
HTTP : //www.baidu.com 2. Запрос пути
ПОЛУЧИТЬ
Заголовок 3. Запрос
Агент пользователя: Обработка пользователя
# Reptile трехчастная песня
1. Запрос на передачу
Def get_page (URL)
ответ = requests.get (URL) возвращает ответ
2. Разбираем данные
Импорт повторно
Def parse_index (HTML); #findall матч все
# Re.findall ( «регулярного правила соответствия», «соответствие текста» , «соответствующий режим»)
# Re.S: искать все согласования текста
Res = re.findall ()
3. Сохранение данных
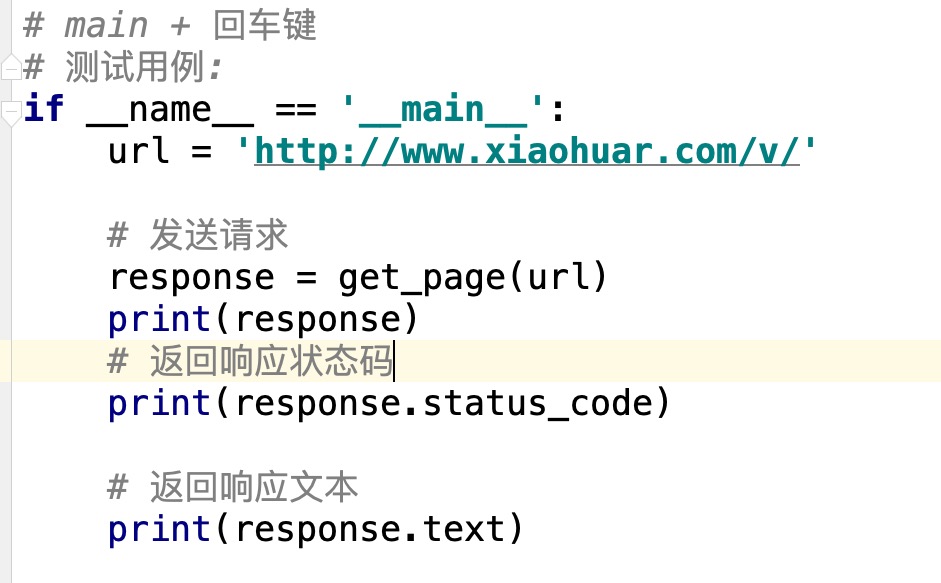
#main + ENTER if_name _ == '_ main_':
URL = ' http://www.xiaohuar.com/v /'
Fasong qingqiu
Réponse = get_page (URL)
Возвращение réponse
# Возвращает код состояния ответа Print (reponse.status_code)
Возвращает текст ответа
Печать (response.text)
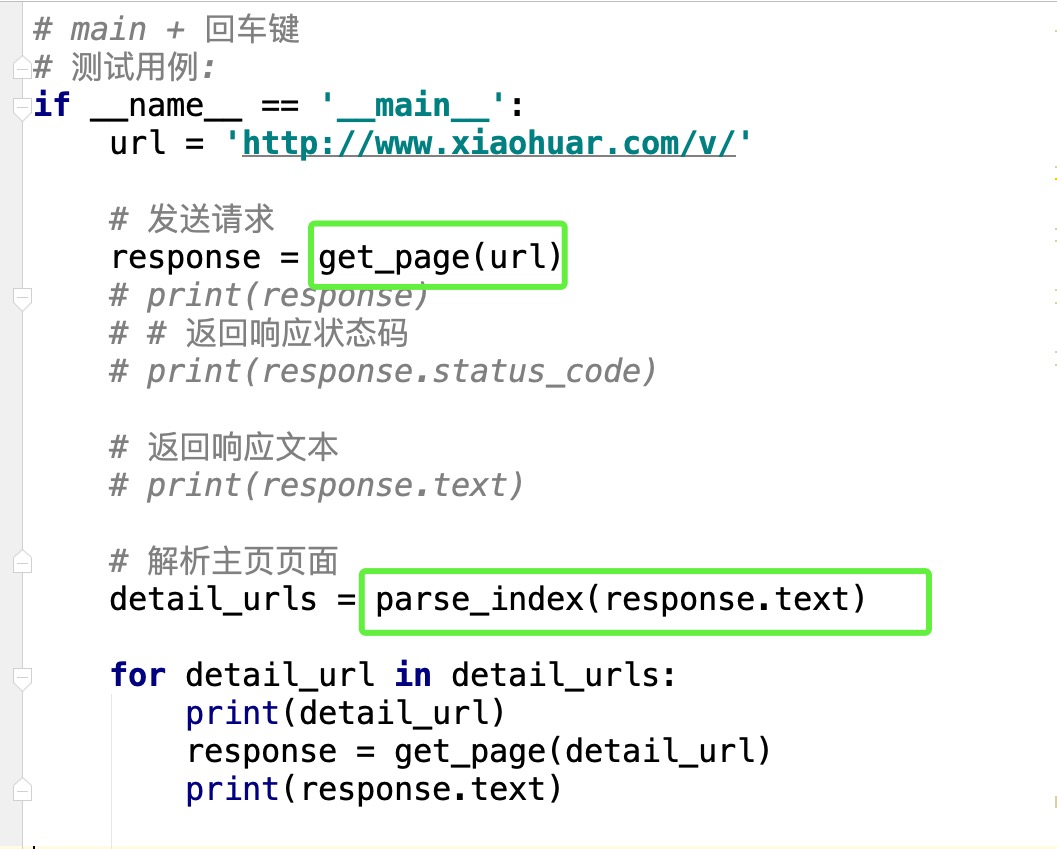
Главная страница разбор




import requests
import re
import time
import uuid
def save_video(content):
with open(f'{uuid.uuid4()}.mp4','wb') as f:
f.write(content)
print('OK!')
def get_page(url):
response = requests.get(url)
return response
def parse_index(html):
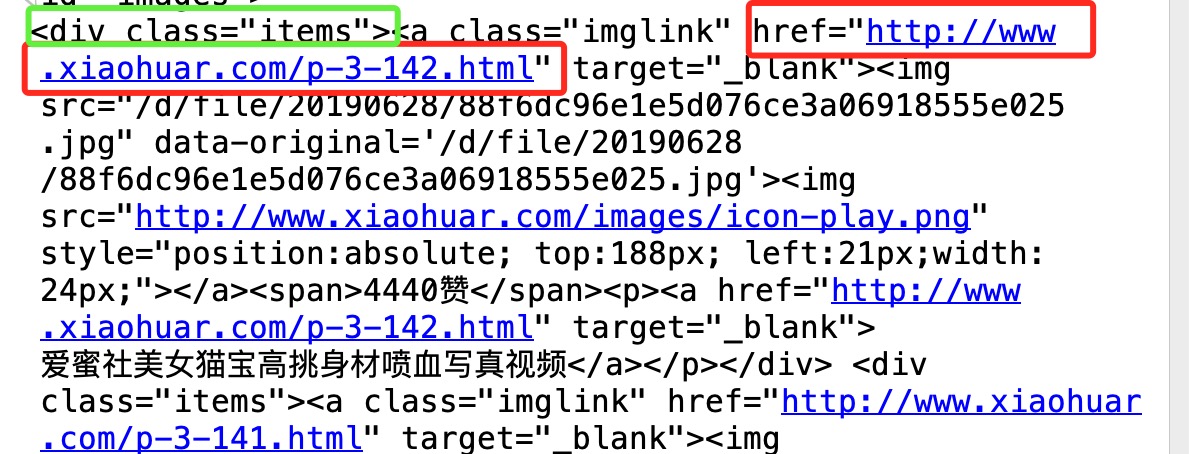
detail_urls = re.findall(
'<div class="items"><a class="imglink" href="(.*?)"',html,re.S
)
print(detail_urls)
return detail_urls
def parse_detail(html):
movie_url = re.findall('<source src="(.*?)">',html,re.S)
if movie_url:
return movie_url[0]
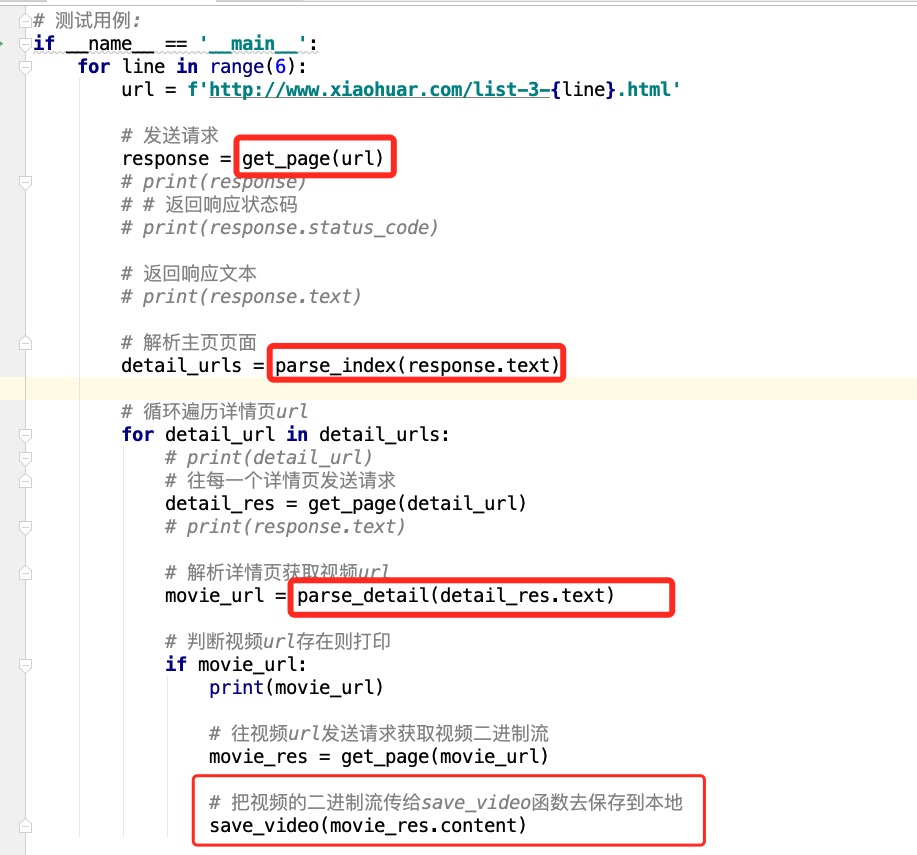
if __name__ == '__main__':
url = 'http://www.xiaohuar.com/v/'
response = get_page(url)
#print(response)
#print(response.status_code)
# print(response.text)
detail_urls = parse_index(response.text)
for detail_url in detail_urls:
#print(detail_url)
#response = get_page(detail_url)
detail_res = get_page(detail_url)
#print(response.text)
movie_url = parse_detail(detail_res.text)
if movie_url:
print(movie_url)
movie_res = get_page(movie_url)
save_video(movie_res.content)
