Hadoop кластера Настройка -05 монтажа конфигурации ПРЯЖИ
Hadoop кластера конфигурации установки Настройка HDFS -04
Hadoop Настройка кластера -03 скомпилировать и установить Hadoop
-02 для создания кластера конфигурации установки Zookeeper Hadoop
Настройка кластера Hadoop -01 подготовительные
Это запись, а затем построить кластер, начать зоопарк конфигурации установки, ее роль, чтобы сделать информацию кластера синхронизации, когда Zookeeper настроить сам по себе отдельные небольшие кластеры, кластер машин, как правило, нечетное число, больше половин тех пор, пока машины работают должным образом, то кластер Zookeeper возможность работать, работать в автоматическом режиме, чтобы избрать лидера для остальной части толкателя, поэтому минимальная конфигурация три.
Обратите внимание, что эта статья не помечена как почти все операции, то по умолчанию операционной Hadoop пользователя
1. Во-первых всех модификаций на периодической записи сценария
Копирование, удаление и назовите две машин в пределах изобр ,, оставив только первые три может быть, то название нескольких сценариев то, что изменить его, и внутреннее имя ссылки изменит.
Я могу изменить хороший https://www.lanzous.com/b849762/ Пароль: 1qq6
2. Установите зоопарк
Может быть загружен с xshell инсталляционного пакета команда Zookeeper RZ, инсталляционный пакет здесь https://www.lanzous.com/b849708/ Пароль: 8À10
[hadoop@nn1 ~]$ cd zk_op/
批量发送给三台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/upload/zookeeper-3.4.8.tar.gz /tmp/
查看是否上传成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /tmp | grep zoo*"
批量解压到各自的/usr/local/目录下
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh tar -zxf /tmp/zookeeper-3.4.8.tar.gz -C /usr/local/
再次查看是否操作成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zoo*"
批量改变/usr/local/zookeeper-3.4.8目录的用户组为hadoop:hadoop
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chown -R hadoop:hadoop /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chmod -R 770 /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper-3.4.8"
批量创建软链接(可以理解为快捷方式)
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh ln - s /usr/local/zookeeper-3.4.8/ /usr/local/zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper"
这里软链接的用户组合权限可以不用修改,默认为root或者hadoop都可以。 Изменить /usr/local/zookeeper/conf/zoo.cfg
Я могу изменить хороший https://www.lanzous.com/b849762/ Пароль: 1qq6
批量删除原有的zoo_sample.cfg文件,当然先备份为好
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh rm -f /usr/local/zookeeper/conf/zoo_sample.cfg
把我们准备好的配置文件放进去,批量。
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/zoo.cfg /usr/local/zookeeper/conf/
=================================================================================================
然后修改/usr/local/zookeeper/bin/zkEnv.sh脚本文件,添加日志文件路径
[hadoop@nn1 zk_op]$ vim /usr/local/zookeeper/bin/zkEnv.sh
ZOO_LOG_DIR=/data
把这个配置文件批量分发给其他机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /usr/local/zookeeper/bin/zkEnv.sh /usr/local/zookeeper/bin/
给5台机器创建/data目录,注意这里是给5台机器创建。用的没改过的原本批量脚本。
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh mkdir /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh chown hadoop:hadoop /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_all.sh "ls -l | grep data"Почему вдруг создано свыше 5 / данные за ним ,,, потому что HDFS и пряжи необходимы, за HDFS работает на трех машинах, так что теперь создается непосредственно.
然后回到zk_op中,给前三台机器创建id文件。用于zookeeper识别
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh touch /data/myidТогда _ являются в три машины _, прилагаемой к этому значению идентификатора документа.
Первый:
эхо "1"> / данные / MyId
Второй этап:
эхо "2"> / данные / MyId
Третий этап:
эхо "3"> / данные / MyId
3. установка Пакетные переменные окружения
在nn1上切换到root用户更改系统环境变量
[hadoop@nn1 zk_op]$ su - root
[root@nn1 ~]# vim /etc/profile
文件在末尾添加
#set Hadoop Path
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin:/usr/local/zookeeper/binЗатем партия отправляется к двум другим машинам
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /etc/profile /tmp/
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh cp -f /tmp/profile /etc/profile
批量检查一下
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh tail /etc/profile
批量source一下环境变量
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh source /etc/profile4. Пакетный старт зоопарка
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh /usr/local/zookeeper/bin/zkServer.sh start
查看一下是否启动。看看有没有相关进程
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh jpsРассмотрите процесс, как показано ниже, это показывает, что процесс начался успешно КПМ
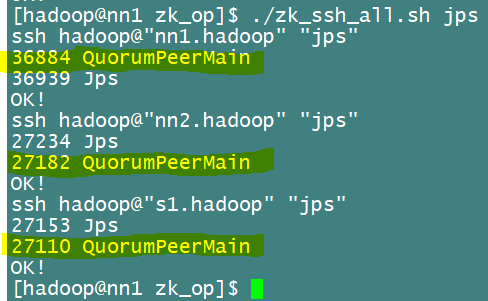
Или просто посмотреть на состояние,
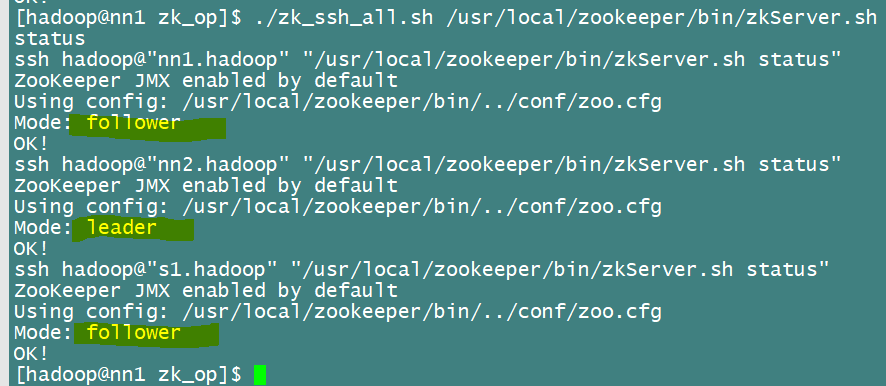
Ну, конфигурация установки зоопарка успешно завершена! ! !