В последнее время такие вещи, как для обработки текстов чувствительной игры, для того, чтобы усилить процесс маскирования, поэтому необходимо, чтобы отфильтровать строки символов в дополнение к другим вещам, таким как числа, символы, буквы и так далее.
Во-первых, доступ к информации, и я написал функцию:
Пример: Возвращает количество символов в строке ввода:
станд :: строка StrWithOutSymbol ( Const станд :: строка & источник) { строка sourceWithOutSymbol; Int я = 0 ; в то время как (источник [I] =! 0 ) { если (источник [I] & 0x80 ) { sourceWithOutSymbol + = источник [I]; sourceWithOutSymbol + = источник [I + 1 ]; я + = 2 ; еще { я ++ ; } } возвращение
sourceWithOutSymbol ;
}
Принцип этой функции Ord ($ строка) и 0x80 судить китайские иероглифы
80, соответствующий двоичный код 1000 0000, самый старший бит равен единице, представитель формат кодирования кандзи известен как формат 10 символов занимает 2 байта, но представляют собой символ
«Окна, упрощенный китайский набор символов кодирования одновременно один байт и 2 байта для представления Когда настало время является 0x00 ~ 0x7F, один байт, 0x80 высока, чем при выраженных 2 байта "
Когда вы находите содержание байта больше , чем 0x7F, то оно должно быть (с другой байт в пестрой) символов, конечно , больше , чем 0x7F , как судить?
0x7F (1111111) за номер , который 0x80 (10000000), так что я хочу больше 0x7F, самый старший бит этого байта, безусловно , 1, нам нужно только определить , является ли старший бит равен 1 в списке.
Анализируя метод:
биты и (то же самое только 1 бит равен 1, в противном случае 0):
как: Для того, чтобы определить , является ли третье число представляет собой 4 с длиной (100) и бит, первого определения, ряд 2 1 всего 2 (10) битов с.
Аналогично определить , следует ли восьмое место с только 1 (10000000) является 0x80 бит с.
Почему здесь нет> 0x7F? PHP линия может также, в другом внутри строго типизированным язык, самые старшие бит байт, используемый для обозначения отрицательных, отрицательная, конечно, не может быть больше, чем 0x7F (наибольшее целое)
Другой пример:
код является assic 97 (1100001)
assic код является 65 (1000001)
б assic код 98 (1100010)
assic код Б 66 (1000010)
Найденный образец: письмо А.З., до тех пор , как строчные буквы, шестое место, безусловно , 1, мы можем использовать эту функцию, чтобы определить случай: на
этот раз, пока с буквами с 0x20 (100000) , чтобы разместить и суждение:
IF ( ДВ (A $) и 0x20) {
// прописные
}
Как поместить все заглавные буквы на шестое место на линии 1 в 0 :?
$ A = 'A';
$ A = CHR (ог ($ A) & (~ 0x20));
эхо $ A;
Я уверен, что тогда эта функция добавлена в проект, выберите команду Выполнить, введите китайский чек, когда! Проект отдается? ? ? ? Массивы границы? ? ? ?
Вот почему, я определить, где была обнаружена ошибка Кокосовые-Lua я использую при передаче строки в C ++ строка передается в UTF-8, чтобы закодировать, я пошел к ПИФ-8 правила кодирования найдены
правила UTF-8 кодирования: если только один байт старший бит равен 0, если это мульти-байты, первый байт от самого высокого уровня, число последовательных двоичного 1-битового значения определяет, который кодирует количество оставшихся байт 10 байт начинает. UTF-8, таблица преобразования следующим образом:
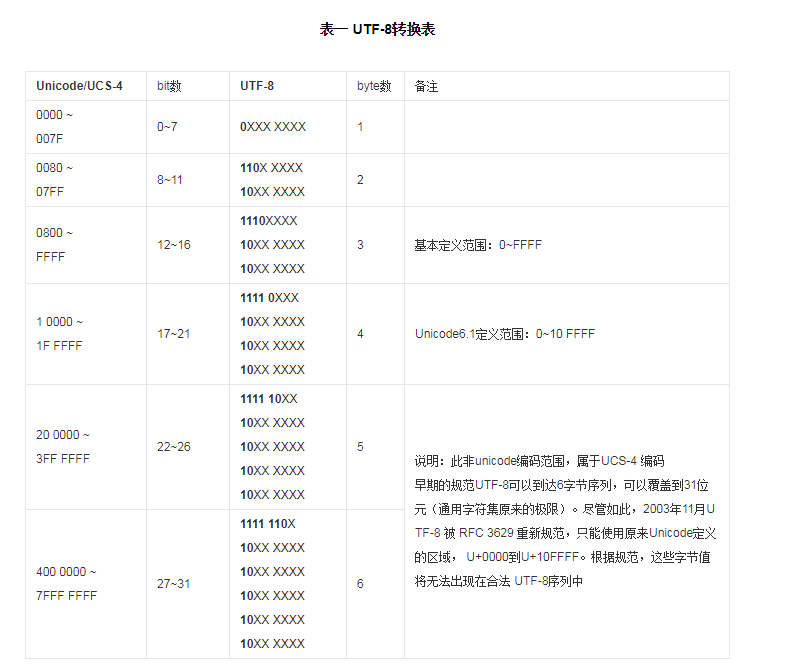
И прежде чем я работал в соответствии с кодировкой GBK, GBK два байта для каждого иероглифа только, и, если возможно, китайские UTF-8 3 байта, четыре байта, пять или даже шесть, так с функцией так же, как будет трансграничная ситуация возникает, поэтому строка кодируется с UTF-8, на необходимость дополнительной обработки, поэтому я написал новую функцию:
UTF-8, строка в кодировке в китайском скрининге функции:
станд :: строка censorStrWithOutSymbol ( Const станд :: строка & источник) { строка sourceWithOutSymbol; Int я = 0 ; в то время как (источник [I] =! 0 ) { если (источник [I] & 0x80 && источник [I] & 0x40 && источник [I] & 0x20 ) { INT ByteCount = 0 ; если (источник [I] & 0x10 ) { ByteCount = 4 ; } Иначе { ByteCount = 3 ; } Для ( Int а = 0 ; а <ByteCount; A ++ ) { sourceWithOutSymbol + = источника [I]; я ++ ; } } Еще если (источник [I] & 0x80 && источник [I] & 0x40 ) { я + = 2 ; } Еще { я+ = 1 ; } } Вернуть sourceWithOutSymbol; }
Нажмите кнопку Выполнить, успех! Удобный.