Справочная информация:
В большинстве случаев, мы столкнулись, была частота ограничений доступа. Если вы посещаете слишком быстро, сайт будет думать, что вы не одиноки. Вам нужен хороший набор пороговую частоту этого случая, или же они могут травмировать. Если мы TOEFL тест, или купить билет на поезд в 12306 выше, вы должны иметь такой опыт, а иногда, даже если вы на самом деле рука работает на странице, но, как вы подводите мышь слишком быстро, она подскажет вам : «... рабочая частота слишком быстро.»
В таких страницах, самый прямой путь, чтобы ограничить время доступа. Например один раз каждые 5 секунд, чтобы получить доступ к странице. Однако, если вы столкнулись с небольшим умным сайтом, он обнаруживает свое время доступа, этот человек посетил десятки страниц, но каждый визит всего пяти секунд, как бы людям такого точный интервал время? Конечно рептилии, был запечатан принимается как само собой разумеющееся! Таким образом, вы можете получить доступ к временному интервалу устанавливаются случайным значение, например, случайное число секунд между 0-10.
Конечно, если вы столкнулись с частотой ограничения доступа к сайтам, мы используем Selenium для доступа становится более выгодным, потому что эта вещь Селен открыть страницу сами займут некоторое время, поэтому у нас есть благословение в маскировке, его низкая эффективность, но давайте шунтирование анти механизм рептилий частота проверок. И Селен может также помочь нам, чтобы сделать веб-страницу JavaScript, устраняя хлопоты ручного анализа JavaScript смысла исходного кода.
Вот измененная частота посещения нескольких сцен, которые я часто использую для справки:
1, запрос автономных рептилий:
После того, как приведенный выше код может быть помещен запрос REQUEST

2, Scrapy автономные распределенного сканирования рептилии или scrapy_redis

Здесь временной интервал установки запроса для объяснения других параметров, я обновлю на новый пост, пожалуйста, с нетерпением ждем
Кроме того, различие не ясно scapy и scrapy_redis друзей, место быть здесь
https: //
3, есть случай, можно пренебречь
Некоторые сайты, такие как тот, который я столкнулся до этого сайта (ГВП), сервер будет ограничивать вашу частоту доступа, но не печать IP, страница будет отображаться на 403 (сервер отказано в доступе), иногда отображать 200 (запрос был успешно ), то доказать (при условии, что вы установили для верхней информации запроса), таких как механизм анти-набора высоты, но ограничивает частоту запросов, но не влияет на нормальную коллекцию, конечно, такие случаи редки, поэтому мы научиться писать адресные рептилии.
4, некоторые серверы для повышения производительности, реакция идет медленно (Время ожидания ответа приведет к требованию прекращения)
Этот сценарий обычно происходит во многих небольших сайтах, такие как (DYW), после того, как мы просили параметры расположены, они нашли, причины производительности сервера, программа сбора продолжала сообщать о 404 страниц, это происходит , мы можем только длительное время ожидания ответа длительность, как показано ниже:

5, прокси - IP или распределенным рептилии:
При необходимости, он не может получить доступ с помощью метода установки интервала частот, чтобы обойти проверку эффективности страницы искателя.
Доступ к IP прокси может решить эту проблему. Если доступ к 100 страницам с 100 агентов IP, на сайт может создать свой род 100 людей, каждый человек посетил иллюзию одного. Естественно, что это не будет ограничивать ваш визит.
Proxy IP часто возникает неустойчивость. Вы просто нашли «свободный агент», там будет много сайтов, каждый сайт даст вам много прокси-IP, но на самом деле, на самом деле не так много доступны прокси IP. Вы должны поддерживать пул доступных прокси IP, но свободным агентом IP, может быть тест, когда вы можете использовать, но через несколько минут становится неэффективным. Бесплатный прокси-сервер IP уже много времени, но и испытание, что вы везение.
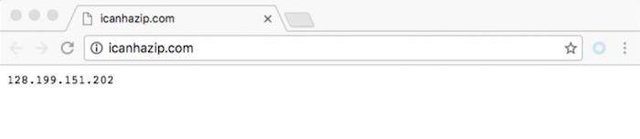
Http://icanhazip.com/ вы можете использовать этот сайт, чтобы определить ваш прокси-сервер IP настроен на успех. Когда вы используете браузер для прямого доступа к этому сайту, он возвращает свой IP-адрес. Как показано ниже:
По запросам, можно настроить прокси-сервер для доступа к сайту, запросы метода GET, есть параметр прокси, данные, которые он получает словарь в словаре, мы можем установить прокси-сервер.
Вы можете увидеть больше информации о настройке прокси-запросов в официальном китайском документе: Http: //docs.python-requests.org/zh_CN/latest/user/advanced.html#proxies
Я выбираю первый тип HTTP-прокси, чтобы сделать тест для вас, бегите результаты, как показано ниже:
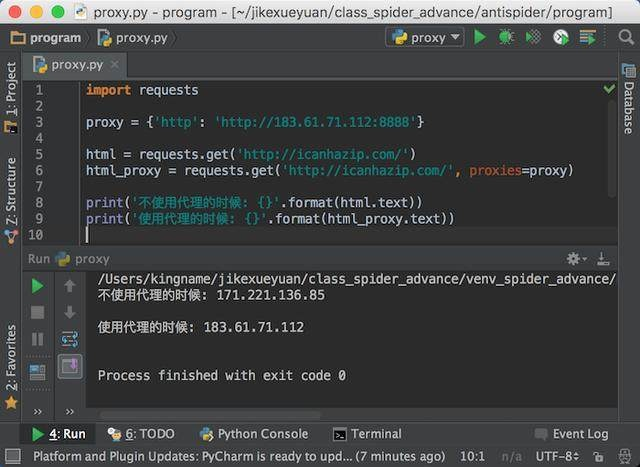
Как видно из диаграммы, мы успешно прошли прокси IP для доступа к сайту.
我们还可以使用分布式爬虫。分布式爬虫会部署在多台服务器上,每个服务器上的爬虫统一从一个地方拿网址。这样平均下来每个服务器访问网站的频率也就降低了。由于服务器是掌握在我们手上的,因此实现的爬虫会更加的稳定和高效。这也是我们这个课程最后要实现的目标。
那么分布式的爬虫,动态代理IP是在settings.py中设置的,如下图:

然后在这里调用

最终是在middlewares.py中生效
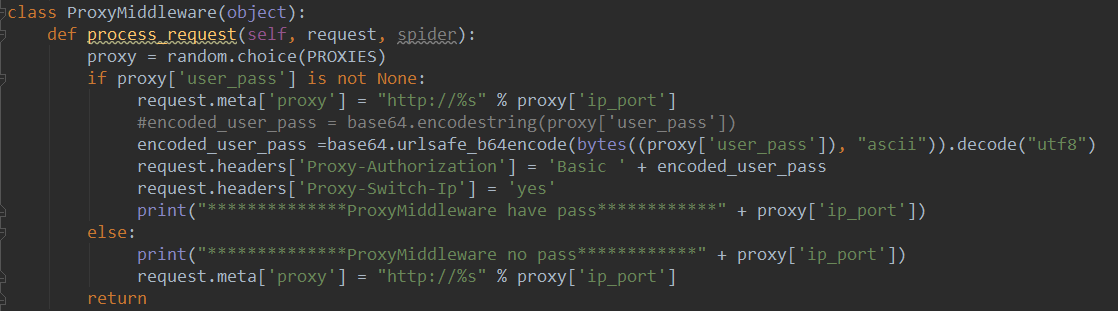
有一些网站,他们每个相同类型的页面的源代码格式都不一样,我们必需要针对每一个页面写XPath或者正则表达式,这种情况就比较棘手了。如果我们需要的内容只是文本,那还好说,直接把所有HTML标签去掉就可以了。可是如果我们还需要里面的链接等等内容,那就只有做苦力一页一页的去看了。