Описание темы
Черный список небезопасных веб-страниц содержат 10000000000 черный список, URL каждой страницы занимает до 64B. Теперь мы хотим внедрить систему веб-фильтрации, которая может определить, является ли страница в черный список, пожалуйста, разработать систему, основанную на URL страницы.
притязание
1. Система позволяет определять частоту ошибок одной десятитысячной или менее.
2. Не используйте дополнительное пространство более 30GB.
Реализация идей
Если все базы данных URL черный список или сохранить в хэш-таблицу, вы можете запросить для каждого URL, но каждый URL есть 64В, число 10 миллиардов требуется, по крайней мере, 640GB пространства, не отвечают требованиям 2 ,
Если интервьюер сталкивается страницы черной списка системы, фильтрация спама, URL рептилии приговорена система веса и другие вопросы, но и увидеть систему терпеть определенную степень частоты ошибок, но более жесткие требования к пространству, то он, возможно, пожелает взять интервью у интервьюера которые имеют знания фильтра Блума.
Он имеет длину м битового массива типа, то есть каждая ячейка в массиве только немного, как мы знаем, только каждый бит 0 и 1 состояния.
Далее предположим, что в общей сложности к хэш-функций, эти функции выходного поля S равны или больше т, и хэш-функции достаточно хорошо, полностью независимы друг от друга. Тогда также вычисляется результат для того же входного объекта (предполагается, что строка упоминается как URL), через к хеш-функций независимо друг от друга, это может быть тем же самым, может быть различным, но независимо друг от друга. Каждый результат вычисляется по модулю (% м) до м, то соответствующее положение устанавливается в 1 в битовом массиве.
Поэтому при проверке сцены, как проверить, является ли объект определенного объекта ввода перед ним? Предположим , что объект является, хотят , чтобы проверить , если он до объекта ввода, поставить значение к вычисляется по к хеш - функции, то значение по модулю K (% м), получена в [0, м- 1] к на диапазон значений. Далее BITMAP видели в этих местах не все , как один . Если нет 1 , что указывает на определенное не в этой коллекции.
Как рассчитать размер фильтра Блума, и скорость просчета
Число выборок в черный список 10000000000, упоминается как н-, а не частоту ошибок больше, чем 0,01%, называют р; 64B является размер каждого образца, эта информация не влияет на размер фильтра Блума, и только выбранный хэш-функция, как правило, хэш-функция может принимать входной объект 64В, поэтому использовать фильтр Блума также является преимуществом без размера немощи одного образца, он не влияет на размер фильтра Bloom.
Следовательно, п = 100 млрд, р = 0,01%, то Блум размер фильтра м определяется следующим уравнением:

Рассчитывается по формуле т = 19.19n, округленное до 20n, необходимость 200000000000 бит, т.е. 25GB.
Количество хэш-функций определяется по следующей формуле:
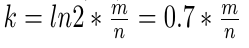
Количество хэш-функции вычисляется для к = 14 тыс.
BitMap 25GB, а затем повторно хэш-функция 14 реализован отдельно, может быть получена в соответствии с фильтром Блума, как описано выше.
Поскольку мы выбрали округление размера фильтра Блума процесса определения, он также определяется Блум фильтр реальной частоты ошибок по следующему уравнению:
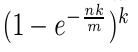
Реальная ошибка была рассчитана по формуле 0,006%, что 0,01% ниже, чем частота ошибок, сама хэш-функция не занимает много места, поэтому использование пространства является размером Bitmap (т.е. 25GB), память сервера может быть достичь этого уровня, все требования стандарта.