I. Введение
1. Обзор
Cloudera Impala был введен, предусматривающим HDFS, данные Hbase высокой производительности, низкая задержка интерактивных запросов SQL.
• улей использует памяти на основе вычислений, как хранилища данных в режиме реального времени, пакетной обработки, множественные одновременно и т.д.
Улья с помощью Impala метаданных, рассчитанные полностью в памяти
• в режиме реального времени CDH является платформой для PB данных магнитуды анализа двигателя
2, особенности Impala
Причина быстрого impalak: 1,2,3,6
1, вычисляется на основе памяти, способной интерактивных запросов в режиме реального времени к данным и анализа ПБ-уровня
2, без преобразования в МР, а также данные непосредственного чтения HDFS HBase, тем самым значительно уменьшая задержку.
Импала нет MapReduce партии, но параллельно реляционная база данных, подобный двигатель распределенный запрос с использованием коммерчески доступного (планировщиком запросов, координатор запросов и запросов Exec Двигатель состоит из трех частей
3, написанные на C ++, компилятор LLVM для запуска единого
Оптимизация базового оборудования, LLVM: компилятор, относительно стабильная, высокая эффективность
4, совместимый HiveSQL
Он поддерживает некоторые базовые улей запрос, улей сложная структура не поддерживается
5, с характеристиками хранилища данных, анализ данных может быть сделан непосредственно на улье данных
6, поддержка данных Local
Данные Локализация: нет движения данных, уменьшить передачу данных
7, поддержка столбчатого хранения
может Hbase и интеграция: Потому что улей может интегрировать и Hbasez
8, поддержка JDBC / ODBC удаленного доступа
3, слабые Impala
1 большая зависимость памяти
Рассчитано только в памяти, официальный предложил 128G (64G в основном отвечают в целом) могут быть оптимизированы: краткое описание каждого узла узла (сервера) используют большой объем памяти, узел не может суммировать небольшие точки
2, C ++ написана с открытым исходным кодом?
Для Java, C ++ может не знать много о
3, полностью зависит улья
4, на практике серьезного падения по производительности раздела 1w
Периодически удалять ненужные разделы, убедитесь, что номер раздела не слишком велико
5, менее стабильны, чем улья
Благодаря полностью рассчитываются в памяти, памяти не хватает, будут проблемы, улее памяти не хватает, вы можете использовать внешнюю память
4, Impala недостатки
- Impala не предоставляет никакой поддержки для сериализации и де-сериализации.
- Impala может только читать текстовые файлы, двоичные файлы не могут быть считаны на заказ.
- Всякий раз, когда новая запись / файл добавляется в каталог данных в HDFS, таблица должна быть свежей.
Во-вторых, архитектура Impala
1, основные компоненты Impala
Statestore Daemon
- Отвечает за сбор информации распределения ресурсов в кластере каждый процесс impalad, здоровье каждого узла, информация синхронизации узла
- Ответственный за запрос планирования
Каталог Daemon
-
Улее метаданные синхронизации из базы данных метаданных, таблицы распределения информации метаданных к различным impalad
-
Он принимает все запросы от statestore
Некоторые начали, не очень импала только после версии 1.2, некоторые метаданные информации и не могут быть синхронизированы с каждым impalad, такие как улей создать таблицу, каталог Daemon не могут быть синхронизированы, вы можете запустить синхронизацию вручную в imapala.
Демон Импала (impalad) <локализованные данные , имеющие характеристики так далее DataNode>
-
Прием клиента, оттенок, цвет, или JDBC ODBC запрос, выполнение запроса и возвращается к центральному узлу координирующей
-
Daemon на дочерние узлы, ответственный за поддержание связи, отчетность statestore
Impala демон: выполняя расчеты. В связи с большой зависимостью памяти, тем лучше не ставить другие компоненты imapla узла согласия
Рассмотрим кассетные проблемы с производительностью, и вообще StateStoreDaemon Каталог Daemon на унифицированных коммуникаций узла, чтобы сделать, потому что между
2, общая структура процесса
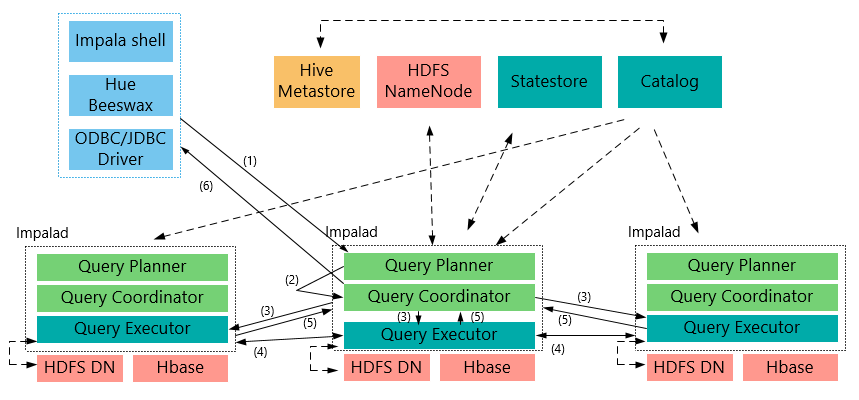
-
Клиент посылает запрос (SQL) для одного Impalad
Он будет оставаться на связи Impalad (связи) с StateStore, который определяет, может ли здоровье записи Impalad импала кластера работать с информацией NameNode метаданных данных, полученных (данные о местоположении и т.д.); Каталог понимается каждым Impalad информации таблицы данных метаданных;
-
Impalad будет решен к определенному выполнению запроса плана Planner, координатор по текущей машине является центральным координирующим узлом
По Impalad JNI, Java передается на передний конце запрос, разбор и план выполнения (Планировщик) завершается передним конец Java, и инкапсулировать план выполнения для возврата выполнения плана бережливости формата на множество этапов, каждый этап называется (фрагмент плана ) PlanFragment, каждый PlanFragment при выполнении множества экземпляров параллельного выполнения Impalad (некоторое PlanFragment быть выполнено только с помощью примера Impalad),
-
Координатор (центральный координационный узел) в соответствии со схемой исполнения Planner, Исполнитель выполнения машины, и передает в другую impalad с данными палача выполняется
-
Impalad может общаться между Исполнителем, вам могут понадобиться для решения некоторых из данных
-
Исполнитель выполнить каждый impalad после завершения, результаты возвращаются к центральному узлу координирующего
Пользователи вызвать метод GetNext (), чтобы получить результат, а если заявление вставки, результаты будут записаны обратно HDFS
Когда все входные данные истощены, выполнение прекращается (завершено).
В процессе реализации, если есть какая-либо неисправность, все выполнение терпит неудачу
-
Координатор центрального узла соберет результаты обратно клиенту
3, Impala и сходства и различия ульев

хранение данных
- Используйте то же хранилище данных пула поддерживают данные, хранящиеся в HDFS, HBase.
Метаданные:
- Оба используют те же метаданные
SQL объяснить лечение:
- Другие подобные планы выполнения генерируется лексическим анализом.
План реализации:
- Улей: зависит от реализации рамок MapReduce, план реализации делится на Map-> shuffle-> reduce-> Map-> shuffle-> уменьшить ... модель. Если запрос составлен на несколько раундов MapReduce, то будет больше писать промежуточные результаты. Поскольку характеристики кадра самой MapReduce выполняется, чрезмерный промежуточный процесс увеличивает общее время выполнения запроса.
- Impala: План осуществления выполнения полного плана реализации дерева может быть более естественным для распространения различного плана Impalad реализации для выполнения запроса, но не нравится улей, как она сочетала в конвейерном тип Map-> уменьшить модель, с тем чтобы обеспечить Impala лучше параллелизм и избежать ненужного промежуточного рода и перемешать.
数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
- Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)
调度
- Hive任务的调度依赖于Hadoop的调度策略。
- Impala的调度由自己完成,目前的调度算法会尽量满足数据的局部性,即扫描数据的进程应尽量靠近数据本身所在的物理机器。但目前调度暂时还没有考虑负载均衡的问题。从Cloudera的资料看,Impala程序的瓶颈是网络IO,目前Impala中已经存在对Impalad机器网络吞吐进行统计,但目前还没有利用统计结果进行调度。
容错
- Hive任务依赖于Hadoop框架的容错能力,可以做到很好的failover
- Impala中不存在任何容错逻辑,如果执行过程中发生故障,则直接返回错误。当一个Impalad失败时,在这个Impalad上正在运行的所有query都将失败。但由于Impalad是对等的,用户可以向其他Impalad提交query,不影响服务。当StateStore失败时,也不会影响服务,但由于Impalad已经不能再更新集群状态,如果此时有其他Impalad失败,则无法及时发现。这样调度时,如果谓一个已经失效的Impalad调度了一个任务,则整个query无法执行。
三、Impala Shell
1、Impala 外部shell
不进入Impala内部,直接执行的ImpalaShell
例如:
$ impala-shell -h -- 通过外部Shell查看Impala帮助
$ impala-shell -p select count(*) from t_stu -- 显示一个SQL语句的执行计划
下面是Impala的外部Shell的一些参数:
-h (--help) 帮助
-v (--version) 查询版本信息
-V (--verbose) 启用详细输出
--quiet 关闭详细输出
-p 显示执行计划
-i hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000, impalad shell 默认连接本机impalad
- r(--refresh_after_connect)刷新所有元数据
-q query (--query=query) 从命令行执行查询,不进入impala-shell
-d default_db (--database=default_db) 指定数据库
-B(--delimited)去格式化输出
--output_delimiter=character 指定分隔符
--print_header 打印列名
-f query_file(--query_file=query_file)执行查询文件,以分号分隔
-o filename (--output_file filename) 结果输出到指定文件
-c 查询执行失败时继续执行
-k (--kerberos) 使用kerberos安全加密方式运行impala-shell
-l 启用LDAP认证
-u 启用LDAP时,指定用户名
2、Impala内部Shell
# impala shell进入
# 普通连接
impala-shell
# impala shell命令 # 查看impala版本 select version; # 特殊数据库 # default,建立的没有指定任何数据库的新表 # _impala_builtins,用于保存所有内置函数的系统数据库 # 库操作 # 创建 create database tpc; # 展示 show databases; # 展示库名中含有指定(格式)字符串的库展示 # 进入 use tpc; # 当前所在库 select current_database(); #表操作 # 展示(默认default库的表) show tables; # 指定库的表展示 show tables in tpc; # 展示指定库中表名中含有指定字符串的表展示 show tables in tpc like 'customer*'; # 表结构 describe city; 或 desc city; # select insert create alter # 表导到另一个库中(tcp:city->d1:city) alter table city rename to d1.city # 列是否包含null值 select count(*) from city where c_email_address is null # hive中 create、drop、alter,切换到impala-shell中需要如下操作 invalidate metadata # hive中 load、insert、change表中数据(直接hdfs命令操作),切换到impala-shell中需要如下操作 refresh table_name 3、参考文章
https://www.w3cschool.cn/impala/impala_overview.html
https://blog.csdn.net/flyingsk/article/details/8590000
https://blog.csdn.net/qiyongkang520/article/details/51067803
转载自链接:https://www.jianshu.com/p/257ff24db397