Функция 1. SIGMOD
Функция формула фиг и ниже график
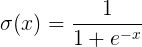

В SIGMOD функции мы можем видеть, выход находится в (0,1) Этот открытый интервал, который очень интересно, вы можете думать о вероятности, но, строго говоря, не как вероятность. Функция SIGMOD раз более популярным, можно подумать о скорости разряда нейронов в средней части склона, где относительно большие чувствительные нейроны с обеих сторон очень пологого склона, где нейроны зоны торможения.
Конечно, мода когда-либо популярная, указывая, что есть некоторая функция сам по себе является дефектной.
1) Когда вход немного в сторону от начала координат, градиент функции становится очень малой, практически равна нулю. Во время обратного распространения нейронной сети, мы соответствующие веса ш рассчитывается по правилу дифференцирования цепи дифференциала. Когда обратное распространение через функцию SIGMOD, дифференциал на цепи на очень, очень мало, и, кроме того, также может пройти через ряд SIGMOD функции, в конечном итоге приводит к весу ш почти без воздействия на функции потерь, что не способствует оптимальному весу, это проблема называется градиенты насыщенности, он также может быть вызван градиент диффузии.
2) не функция выводит 0 в качестве центра, это приведет к сокращению веса обновления эффективности. Для этого дефекта, в котором курс Стэнфордского имеет подробное объяснение.
3) функция SIGMOD экспоненцирование должна быть выполнена, это для относительно медленных компьютеров.
2.tanh функция
TANH кривой следующая функция и формула
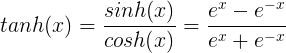
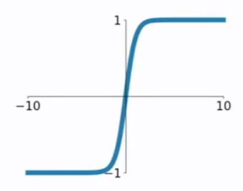
TANH является функция гиперболического тангенса, функция кривой TANH и SIGMOD функция относительно похожи, давайте сравним его и посмотреть. Во-первых, это то же самое, эти две функции в большом или малом входе, на выходе будет почти гладкая, градиент очень мал, не способствует обновлению веса; другой выходной секции, секция выход TANH (-1, между 1), и вся функция 0-ориентированной, эта особенность SIGMOD лучше.
Общая бинарная классификация, скрытая функция слоя функция выход TANH слой SIGMOD. Но они не являются неизменными, что является функцией активации конкретного использования, или в соответствии с конкретными вопросами к конкретному анализу, или полагаться на отладку.
функция 3.ReLU
РЕЛУ кривой следующая функция и формула
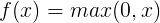
РЕЛУ (выпрямленный Линейный блок) является функцией от функции активации больше огня, чем в SIGMOD функции и TANH функций, он имеет следующие преимущества:
1) Если вход является положительным, насыщенный градиент без проблем.
2) вычислить гораздо быстрее. РЕЛУ линейная функция только, либо вперед или назад распространение распространения и Тань, чем SIGMOD гораздо быстрее. (SIGMOD и TANH Для расчета скорости вычисления индекса будет медленнее)
Конечно, есть и недостатки:
1) Если вход отрицательный, когда РЕЛУ полностью активируется, предполагая, что когда-то вступил в негатив, РЕЛУ умрет. Такой процесс распространения вперед, но и не является проблемой, и некоторые области чувствительны, некоторые нечувствительным. Тем не менее, в процессе обратного распространения, отрицательный вход, градиент будет полностью до 0, а функция SIGMOD, функция TANH имеет те же проблемы.
2) мы находим функцию вывода РЕЛУ либо 0, либо положительное число, то есть, не функция РЕЛУ является 0-ориентированных функций.
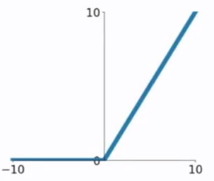
функция 4.ELU
ЭЛУ следующие функции формулу и график на фиг.
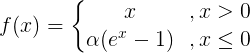
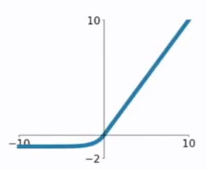
функция модификации ЭЛУ является функцией для РЕЛУ по сравнению с функцией РЕЛУ, когда входной отрицательный, существует определенный выход, и этот выход часть также обладают некоторой способностью анти-помех. Это устраняет проблему РЕЛУ мертвое, но все еще насыщенные и проблемы расчета индекса градиента.
функция 5.PReLU
PReLU следующие функции формулу и график на фиг.
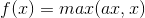

PReLU также для улучшенной версии РЕЛУ, в отрицательной области, PReLU есть небольшой наклон, который также позволит избежать проблемы РЕЛУ мертвых. По сравнению с ГЛП, PReLU является линейной операцией в отрицательной области, наклон может быть небольшим, но не стремится к 0, что можно считать определенным преимуществом этого.
Мы видим PReLU формулу, параметр а, который, как правило, выборку между 0 и 1 и в целом по-прежнему относительно мала, например, 0,0 несколько. При α = 0,01, мы называем PReLU, как Дырявый РЕЛУ, можно рассматривать как особый случай PReLU его.
В целом, эти функции активации имеет свои преимущества и недостатки, ни один из которых не сказать, показывает, что это хорошая функция активации, все хорошее и плохое должны получить свои собственные эксперименты.
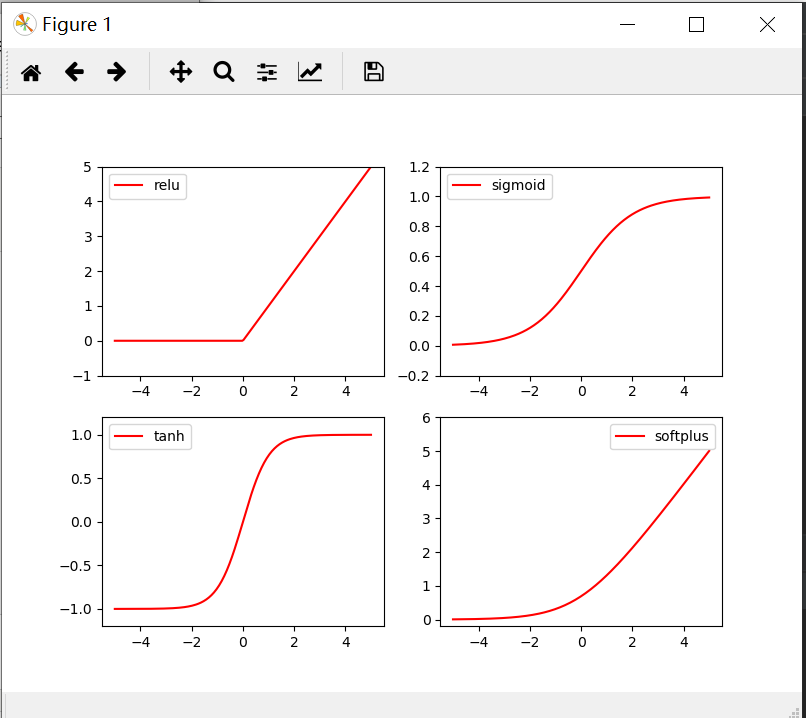
Возбуждение Код функции показано ниже
import torch from torch.autograd import Variable import matplotlib.pyplot as plt import torch.nn.functional as F x= torch.linspace(-5,5,200) x= Variable(x) x_np=x.data.numpy() y_relu = torch.relu(x).data.numpy() y_sigmoid =torch.sigmoid(x).data.numpy() y_tanh = torch.tanh(x).data.numpy() y_softplus = F.softplus(x).data.numpy() plt.figure(1,figsize=(8,6)) plt.subplot(221) plt.plot(x_np,y_relu,c='red',label='relu') plt.ylim(-1,5) plt.legend(loc='best') plt.subplot(222) plt.plot(x_np,y_sigmoid,c='red',label='sigmoid') plt.ylim(-0.2,1.2) plt.legend(loc='best') plt.subplot(223) plt.plot(x_np,y_tanh,c='red',label='tanh') plt.ylim(-1.2,1.2) plt.legend(loc='best') plt.subplot(224) plt.plot(x_np,y_softplus,c='red',label='softplus') plt.ylim(-0.2,6) plt.legend(loc='best') plt.show()