сравнение безопасности и обсуждение 1.Get и POST
Самое основное различие между этими двумя
- запрос URL GET представил данные (строка запроса), как можно видеть в URL-параметров. передача данных параметров POST «тело запроса» не появляется в URL
- GET запросы , представленные данные имеют ограничение длины , POST запросы без ограничений.
- GET запрос возвращается содержимое может быть кэшируются браузером. И каждый представленный POST, браузер при нажатии окно подтверждения F5 будет всплывал, браузер не будет кэшировать содержимое запроса POST, чтобы вернуться.
- GET запрос данных, POST основных дополнений и удаления данных! Проще говоря, ПОЛУЧИТЬ только для чтения , POST написано.
Различные перспективы
- Я думаю , что пост, безопаснее время, потому что передача будет получить параметры отображения в URL, более вероятно , разработать некоторые «вредоносные» люди , представляющие интерес, такие как верхний появились имя пользователя и userpwd и других специальных символов, легче дать им некоторый интерес , Хотя это кодирование, когда декодирование также возможно. Сообщение невидимы друг к другу, хотя некоторые эксперты перехватывать информацию, она также должна фильтровать, а также декодирование, относительно более безопасным , чем метод GET. Конечно, нет абсолютной безопасности.
- HTTP GET протокола Указанный метод является безопасным (безопасный метод), что означает, что метод GET не изменяет сервер данных, он не будет вызывать побочные эффекты. Если это место с POST GET, GET небезопасным сказал, что ПОЛУЧИТЬ слишком обижены. Другими словами, до тех пор, пока мы выбираем правильное использование GET и POST, GET это безопасно.
- До тех пор, как мы используем их правильно, потому что данные не модифицированный метод GET не передается частью конфиденциальной информации, которая должна быть передана POST с, GET, так что нет никаких проблем безопасности, и необходимо обратить внимание на вопросы безопасности POST передачи.
- Правильное использование два, считайте, как и GET и POST правильного выбора для использования. Эти правила или нормы, как его развивать? Почему бы не отправить зашифрованную информацию и изменять данные это? POST причина заключается в том, что это не безопасно, поэтому протоколе HTTP обеспечивает для того, чтобы передавать маловажное чтение, так только потому, что он не вызывает проблемы с безопасностью. Поскольку передача данных не стоит того, чтобы другие не украсть, никакой ценности.
II. Перерисовка и свести к минимуму рефлюкс
Redraw: каждый узел дерева отображения преобразуется в реальные пиксели на экране
Возврат: вычислить положение и геометрию узел, а затем, когда макет страницы и геометрия изменение данных, нам нужно до кипения.
Так, например, следующее:
- Добавить или удалить видимый элемент DOM
- Положение элемента изменяется
- Размер элемента изменяется (в том числе полей, рамки, размер кадра, высота и ширина)
- Содержание изменение, такие как изменения текста или изображений являются различными размерами изображений заменяются.
- начала рендеринга страницы время (что, безусловно, нельзя избежать)
- Изменение размера окна браузера (так как положение и размер рефлюксная рассчитываются в зависимости от размера элемента окна просмотра)
Рефлюкс вызовет перерисовку, и не обязательно перерисовывать рефлюкс
Перестройка и сведение к минимуму перерисовывать
1. Комбинированное количество изменений в DOM и стиля, а затем утилизировать сразу
2.css3 аппаратное ускорение (ускорение GPU),
3. Пакетные изменения DOM
Когда нам нужно изменить ряд DOM, вы можете уменьшить количество перерисовки обратно через следующие шаги:
-
Элементы из потока документов
-
Его несколько ревизий
-
Элемент обратно в документ.
Первые и третьи этапы процесса могут вызвать рефлюкс, но после первого шага, все изменения в DOM не будут вызывать рефлюкс, потому что он не оказал дерево.
Есть три способа сделать DOM из потока документов:
-
Скрытые элементы, изменить приложение и повторно-дисплей
-
Используйте фрагмент документа (фрагмент документа), построенный за пределами текущего поддерева DOM, а затем копирует его обратно в документ.
-
Элемент , чтобы скопировать исходный документ из узла, модифицированного узла, а затем заменить оригинальные элементы. Конкретные примеры относятся https://blog.csdn.net/vM199zkg3Y7150u5/article/details/85042996
Три .Vuex-- режима государственного управления (магазин / состояние / Getter / Действие / Мутации / Module)
ядро Vuex
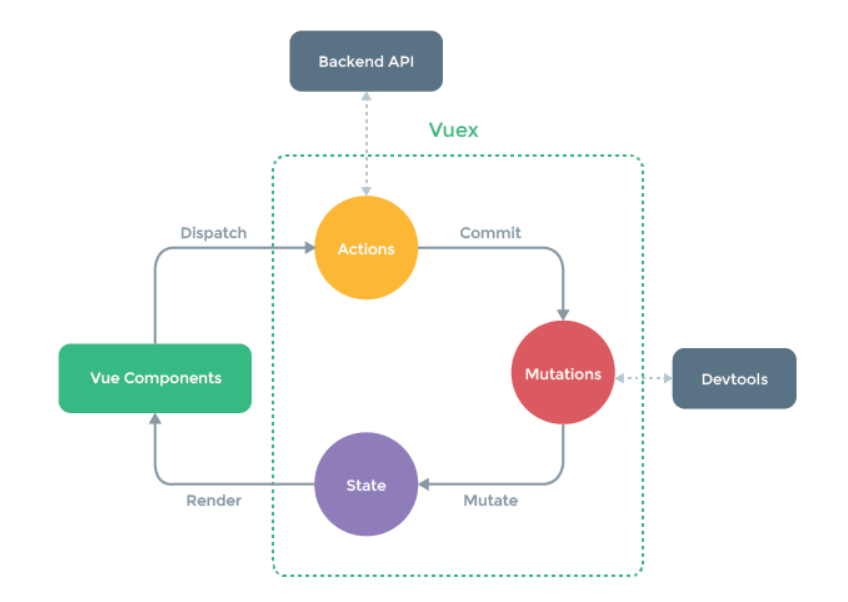
состояние: состояние Вьет дисплей в сборе
Getter: Vuex позволяет определить в магазине в «добытчика» (можно считать, чтобы вычислить магазин собственности). Как рассчитывается как свойство, возвращаемое значение геттер будет основываться на его зависимости кэшируются, и только тогда, когда она зависит от значения изменилось будет пересчитан.
Действие: Используйте $ store.dispatch в компоненте ( «ххх»), распределенные действия.
Мутация: Единственный способ изменить Vuex магазин находится в состоянии мутации представления. Vuex мутации очень похожие на: Тип события (типа) каждой мутации имеет строку и функцию обратного вызова (обработчик).
Модуль: использование единого государственного дерева, состояние всех приложений будет сосредоточено в относительно крупных объектов. Когда приложение становится очень сложным, хранить объект, вероятно, станет весьма раздутой. Чтобы решить эту проблему, Vu позволяют хранить делятся на модули (модуль). Каждый модуль имеет свои собственные состояния, мутацию, действие, добытчик, даже вложенные субы-модули - от верхней части к нижнему части разделена таким же образом, для решения вышеуказанной проблемы, Vu позволяют нам магазин разделен на модули (модуль). Каждый модуль имеет свое собственное состояние, мутацию, действие, добытчик, даже вложенные Субмодули - сверху донизу разделения таким же образом,
Код демонстрирует
https://blog.csdn.net/u011374582/article/details/82799586
IV. Учитывая [5 <6 <3,3 <2 <4] Run Результаты
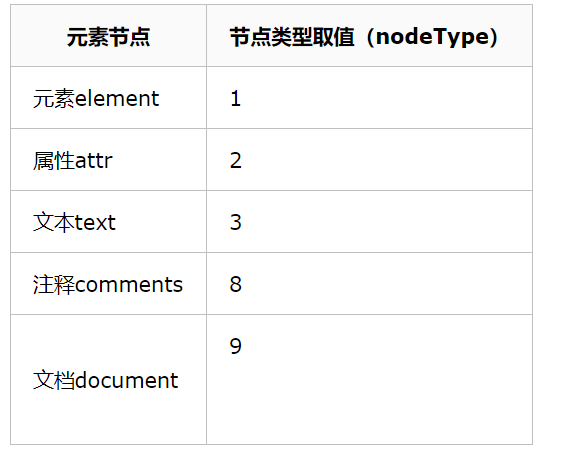
соответствующий текстовый узел Пять значения .nodeType
NODETYPE используется для получения типа текущего объекта узла.
NODETYPE свойство возвращает тип узла. Вот некоторые важные ценности NODETYPE.
Шесть программирования проблем.
1. Введите строку с наибольшим числом символов и числом появления вхождений строки.
# include <stdio.h> INT основных () { INT K = 0 , СУММА [ 100 ], D = 0 ; символ УЛ [ 100 ]; Е ( " Пожалуйста , введите строку: " ); Scanf ( " % S " , STR), для ( INT I = 0 ; STR [I] =! ' \ 0 ' ; I ++) / * каждый символ строки #### и вся строка Сравнительное ##### * / { для ( ИНТ J = 0 ;! STR [J] = ' \ 0 ' ; J ++) { ЕСЛИ (STR [J] == СТР [I]) // если тот же самый символ найден, K из Канады 1. К ++ ; } СУММА [I] = K; // значение K хранится в массиве SUM K = 0 ; // К- очищается, чтобы облегчить следующий счетчик циклов } для ( INT I = 0 ; STR [I] =! ' \ 0 ' ; I ++) // найти максимальное значение в массиве SUM { IF (SUM [ 0 ] < СУММА [I]) { СУММА [ 0 ] = СУММЫ [I]; D = I; //Скопирован в положение максимума D } } на Е ( « наибольшее число вхождений символов% с, число вхождений времени% d \ n- » , УЛ [D], SUM [D]); // Выход чаще всего возникает ., а число вхождений символов возврата 0 ; }
2. Анализ скобка соответствует строке
Чтение с клавиатуры в строку, которая содержит только () {} [], строка символов определяют, является ли каждая из скобок попарно.
Совет: стек может быть достигнуто с помощью кронштейнов должны быть парными выглядит как () [] {}, который соответствует скобки, такие как ([{])}, которая является несогласованные круглые скобки (без пробелов).
Вход Описание:
введите строку (без промежуточных пространств)
Выход Описание:
Match Output верно, в противном случае ложный выход
Ввод пробы:
(([{}]))
Выход образца:
Да
Идеи:
1. Цифры в скобках соответствуют четыре возможности:
Спаренных левый и правый кронштейны ① неправильный заказ
② левой скобку правой скобки чем
③ левого кронштейна и правый кронштейн , чем
соответствующие кронштейны правильно вокруг ④
2. Идея алгоритма:
1. последовательного сканирования арифметического выражения (выраженное в виде строки), левая скобка , когда сталкиваются с тремя типами времени для скобок в стек;
2. При сканирование с определенным типом правой скобки, то сравнивая текущее совпадение , если верхний элемент, если матч определяется продолжать де стеками;
3. если текущая вершина стека не соответствует текущей скобки сканирования, скобки на порядок неправильного спаривания, совпадение не найдено , выход;
4. если правая строка скобка символов в настоящее время какой - то тип стек пуст, чем правая скобка левая скобка, матч не удается, выход;
5. строка сканирования цикл заканчивается, когда стек не пуст (т.е., есть определенные типы стека левая скобка), то левая скобка и правая скобка чем, матч завершается неудачно;
-правильно соответствуют нормальному концу кронштейна.
#include <iostream> #include <CString> #include <стек> используя пространство имен станд; INT основных () { стека < символ > а; INT флаг = 1 , я; символ ч [ 100 ]; CIN >> ч; для (я = 0 ; I <STRLEN (ч); я ++ ) { если (ч [я] == ' { ' || ч [я] == ' ( ' || ч [я] == ' [ ' ) a.push (гл [I]); иначе { если (a.empty () == верно ) { флаг = 0 ; перерыв ; } Иначе , если ((ч [я] == ' } ' && a.top () == ' { ' ) || (гл [I] == ' ) ' && a.top () == ' ( ' ) || (ч [я] == ' ] ' && a.top () == ' [ ' )) a.pop (); = 0; перерыв ; } } } Если (флаг == 0 ) соиЬ << " ложь " ; еще соиЬ << « истинно » ; }