1, L регуляризации слой нейронной сети:
(1) L2 регуляризации:

(2) Почему регуляризация, чтобы избежать чрезмерной подгонки?

Когда лямбда достаточно велико, J сведено к минимуму, так что матрица весов W будет близка к нулю, упрощенная нейронная сеть является состоянием высокого смещения:
лямбда было больше, чем вес, г = ш * а + б, г мала, чтобы функции TANH в качестве примера:

Когда г меньше ступени, функция г (г) близка к линейной. Если линейный подход каждый слой, сеть представляет собой линейную сеть, ситуация не будет соответствовать через.
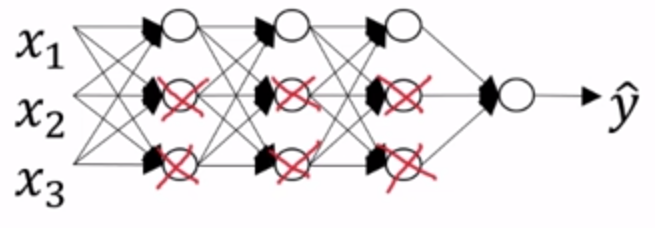
(3) отсев регуляризации (случайная инактивация):
Каждый узел нейронной сети содержит вероятность деактивация р, следующим образом:
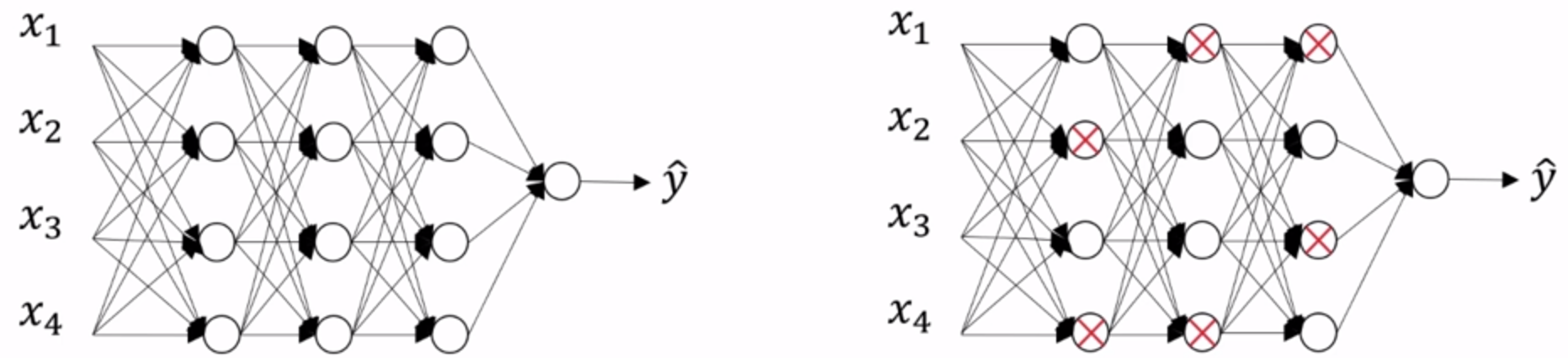
Упростить подключение, получить узел меньше, меньший масштаб сеть:
Коды являются следующими:
Для третьего слоя случайной инактивация, 0,8 keep_prob = (вероятность скрытого блока, чтобы сохранить, то есть, что исключает вероятность скрытого блока составляет 0,2), keep_prob различных слоев могут быть разными.
d3 = np.random.rand (a3.shape [0], a3.shape [1]) <keep_prob
а3 = np.multiply (а3, d3) # фильтруют инактивированный узел
а3 = а3 / keep_prob # составляют 20% от отфильтровывают, таким образом, что ожидаемое значение константы а3
(4) Другой метод регуляризации:
① расширить набор данных;
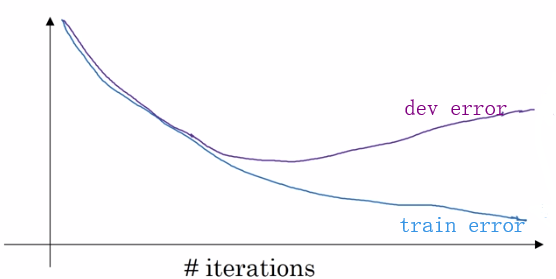
② досрочное прекращение итерации:
(5) Input регуляризации:
① с нулевым средним:
μ = 1 / м * Σx (я)
х = х - м

② дисперсии нормализации:
σ² = 1 / м * Σ (х (I) ) ²
х = х / с²
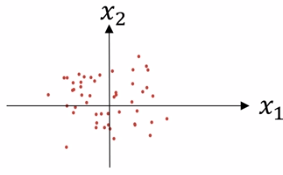
③ Почему вход регуляризация?
Non регуляризация может вызывать функции ввода изображения стоимости являются несколькими удлинены, а значения x1 до 1000, но только после 0-1. Регуляризаций входного значения x2, стоимостная функция выглядит более симметричными.
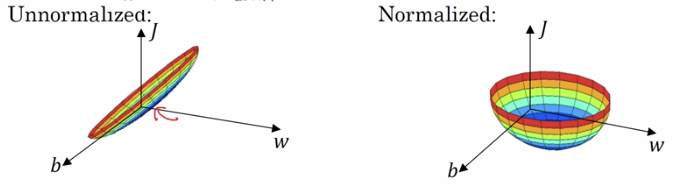
Фиг увидеть не-регуляризованный градиентный спуск является более извилистым, и регуляризованным градиент быстро уменьшается.
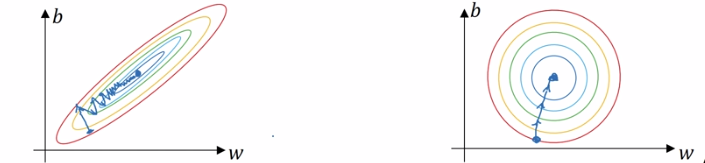
2, Исчезновение / Взрывающиеся градиенты (градиент взрыв рассеивает градиент):
(1), описанные в качестве примера:

假设:g(z) = z; b[l] = 0.
y = w[L]w[L-1]w[L-2] ... w[2]w[1]x

(2)解决方案:权重初始化
由 z = w1x1 + w2x2 + ... + wnxn
随着 n 的增大,期望的 w[l] 越小,由此设置 Var(w[l]) = 1/n 或者 2/n(效果更好),即:
w[l] = np.random.randn(shape) * np.sqrt(2/n[l-1])
3、梯度检验:
(1)梯度的数值逼近:

双边误差公式更准确,可以用来判断 g(θ) 是否实现了函数 f 的偏导.
(2)神经网络的梯度检验:
① 将 W[1],b[1],...,W[L],b[L] 从矩阵转为一个向量 θ;
② 将 dW[1],db[1],...,dW[L],db[L] 从矩阵转为一个向量 dθ;
③ J = J(θ1, θ2, ..., θi, ...)
for each i :
dθapprox[i] = (J(θ1, θ2, ..., θi + ε, ...) - J(θ1, θ2, ..., θi - ε, ...)) / (2 * ε)
check dθapprox[i] ≈ dθ[i] by calculate || dθapprox[i] - dθ[i] ||2 / (|| dθapprox[i] ||2 + || dθ[i] ||2) < 10^-7(或其他误差阈值)
(3)梯度检验注意点:
① 检测完关闭梯度检验;
② 检查是否完成了正则化;
③ 不适用于dropout;
④ 检查是否进行了随机初始化.