- 原文: Структуры данных верхнего вы должны знать для вашего следующего кодирования интервью
- Переводчик: Fundebug
В этой статье, парафраз, принадлежит автору

В 1976 году швейцарский ученый написал книгу «Алгоритмы + структуры данных = Программы» . А именно: Структуры Алгоритмы + Данные = Программы. 40 лет спустя, это уравнение остается в силе.
Много код лицо вопросов требуют от кандидатов глубокого понимания структуры данных, приходите ли вы из университета информатики и программирования учебных заведений, независимо от того, сколько лет вы опыт программирования. Иногда сталкиваться с вопросами, непосредственно упомянутые структуры данных, такие как «Дайте мне реализацию бинарного дерева», но иногда не столь очевидны, такие как «статистические данные о количестве каждого автора, чтобы написать книгу.»
Что такое структура данных?
Структура данных хранится в компьютере, данные организованы. Для конкретных структур данных (например, массивов), некоторые очень высокая эффективность работы (чтения элемента массива), низкая эффективность некоторых операций (удалить элемент массива). Цель программиста заключается в выборе оптимальной структуры данных для текущей задачи.
Зачем нам нужна структура данных?
Данные является основным элементом программы, и, следовательно, значение структуры данных очевидно. Независимо от того, какую программу вы пишете, что вам нужно будет иметь дело с данными, например, заработной платы сотрудников, цены на акции, список покупок или телефонной книги. В соответствии с различными сценариями, данные должны храниться определенным образом, мы имеем различные структуры данных для удовлетворения наших потребностей.
8 видов общих структур данных
- массив
- стек
- очередь
- список
- карта
- дерево
- Приставка дерево
- Хэш таблица
1. Массив
Array (Array), вероятно, самые простые и наиболее часто используемые структуры данных. Другие структуры данных, такие как стеки и очереди получены путем массивом.
На приведенном ниже рисунке показана матрица, которая состоит из четырех элементов:
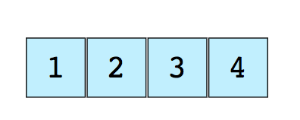
Положение каждого элемента массива с помощью цифрового числа называется индекс или индекс (индекс). Индекс первого элемента массива 0 в большинстве языков программирования.
Размерность различия, существует два разных массивов:
- Одномерный массив (как показано выше)
- Многомерный массив (массив элементов массива)
Основная операция массива
- Вставка - для вставки элемента в индексе
- Get - прочитать индекс элемента
- Для удаления элемента с индексом - Удалить
- Размер - Получить длину массива
Общий массив кода лица вопросы
- Найдите второй наименьший элемент массива
- Не найдя повторения первого элемента массива
- Слияние двух отсортированных массивов
- Перестановка плюсовой массива и отрицательные
2. Стек
Снято, то есть, Ctrl + Z, один из наших наиболее распространенных операций, большинство приложений будут поддерживать эту функцию. Вы знаете, как это добиться? Ответ таков: предыдущее состояние приложения (предельное число), сохраненные в памяти, самое последнее состояние в первой. На данный момент, мы должны стек (стек) для достижения этой функции.
Элементы стека с использованием LIFO (последний First Out), т.е. LIFO.
Фигура нижней стек имеет три элемента 3 в верхней части, так что сначала удаляют:
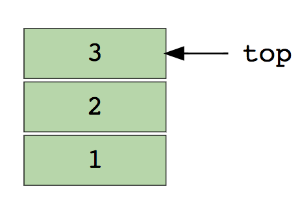
Основная операция стека
- Push - вершина стека вставных элементов
- Поп - вернуться к началу элементов стека, и удалить его
- IsEmpty - запрос пуст ли стек
- Top - возврат к верхней части элементов стека, не удаляются
Общие вопросы стек код для лица
- Выражение Постфикс с использованием стека вычислений
- Использование стека в стек элементы отсортированного
- Проверьте строка соответствует правильные скобки
3. Очередь
Очередь (Очередь) похожа на стек, являются линейными структурами для хранения данных. Разница заключается в том, что, используя режим работы LIFO стека, при использовании очереди FIFO, т.е. FIFO (первый в First Out).
На следующем рисунке показана очередь, самый верхний элемент 1, сначала удаляется:
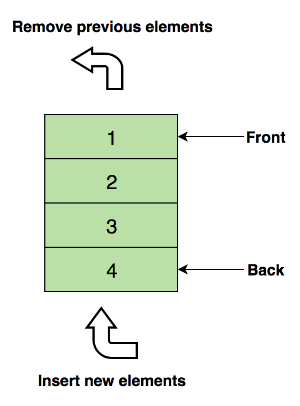
Основная операция очереди
- Епдиеий - элемент вставлен в конце очереди
- Dequeue - первый элемент очереди, чтобы удалить
- IsEmpty - очереди запросов пусты
- Top - возвращает первый элемент очереди
Код общей очереди вопросов лица
- Использование очереди реализации стека
- K элементы до обращенной очереди
- Преобразуется в 1 с использованием очереди н двоичного
4. список
Список (Linked List) также линейная структура, она очень похожа на массив, но их распределение памяти, внутренняя структура и вставка или операция удаления не то же самое.
Список Сеть состоит из ряда узлов, каждый узел хранит данные, и указатель на следующий узел. Начало списка указатель на первый узел, если список пуст, указатель головы пустой или нуль.
Списки могут быть использованы для реализации файловой системы, хэш-таблицы и смежностей таблицы.
На приведенном ниже рисунке показан связанный список, который имеет три узла:

Список разделен на два вида:
- 单向链表
- 双向链表
链表的基本操作
- InsertAtEnd — 在链表结尾插入元素
- InsertAtHead — 在链表开头插入元素
- Delete — 删除链表的指定元素
- DeleteAtHead — 删除链表第一个元素
- Search — 在链表中查询指定元素
- isEmpty — 查询链表是否为空
常见的队列代码面试题
5. 图
图(graph)由多个节点(vertex)构成,节点之间阔以互相连接组成一个网络。(x, y)表示一条边(edge),它表示节点 x 与 y 相连。边可能会有权值(weight/cost)。
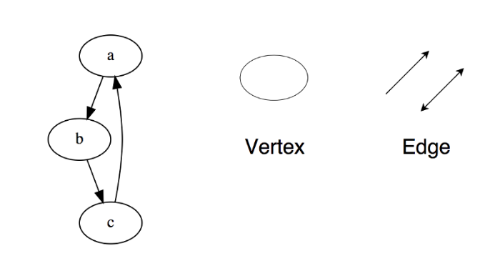
图分为两种:
- 无向图
- 有向图
在编程语言中,图有可能有以下两种形式表示:
- 邻接矩阵(Adjacency Matrix)
- 邻接表(Adjacency List)
遍历图有两周算法
- 广度优先搜索(Breadth First Search)
- 深度优先搜索(Depth First Search)
常见的图代码面试题
6. 树
树(Tree)是一个分层的数据结构,由节点和连接节点的边组成。树是一种特殊的图,它与图最大的区别是没有循环。
树被广泛应用在人工智能和一些复杂算法中,用来提供高效的存储结构。
下图是一个简单的树以及与树相关的术语:
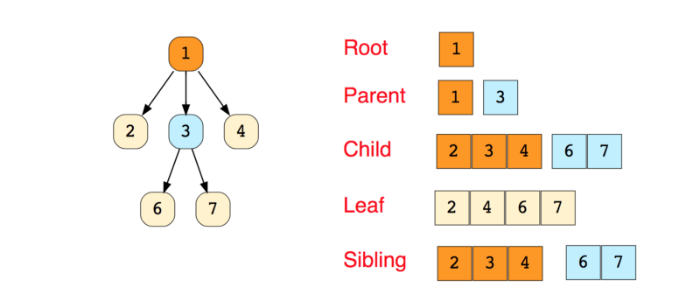
树有很多分类:
- N 叉树(N-ary Tree)
- 平衡树(Balanced Tree)
- 二叉树(Binary Tree)
- 二叉查找树(Binary Search Tree)
- 平衡二叉树(AVL Tree)
- 红黑树(Red Black Tree)
- 2-3 树(2–3 Tree)
其中,二叉树和二叉查找树是最常用的树。
常见的树代码面试题
7. 前缀树
前缀树(Prefix Trees 或者 Trie)与树类似,用于处理字符串相关的问题时非常高效。它可以实现快速检索,常用于字典中的单词查询,搜索引擎的自动补全甚至 IP 路由。
下图展示了“top”, “thus”和“their”三个单词在前缀树中如何存储的:
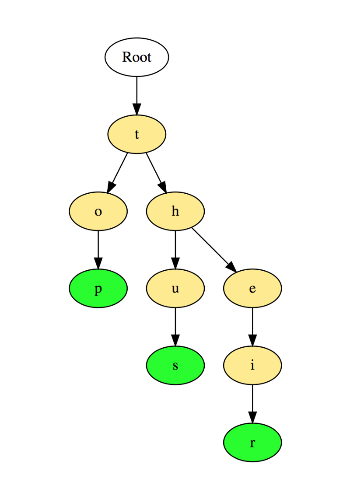
单词是按照字母从上往下存储,“p”, “s”和“r”节点分别表示“top”, “thus”和“their”的单词结尾。
常见的树代码面试题
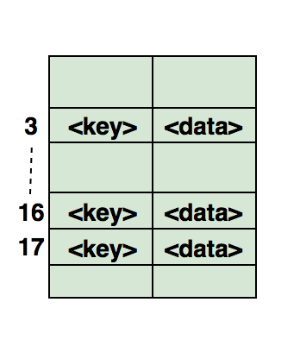
8. 哈希表
哈希(Hash)将某个对象变换为唯一标识符,该标识符通常用一个短的随机字母和数字组成的字符串来代表。哈希可以用来实现各种数据结构,其中最常用的就是哈希表(hash table)。
哈希表通常由数组实现。
哈希表的性能取决于 3 个指标:
- 哈希函数
- 哈希表的大小
- 哈希冲突处理方式
下图展示了有数组实现的哈希表,数组的下标即为哈希值,由哈希函数计算,作为哈希表的键(key),而数组中保存的数据即为值(value):