Сегодня мало для всех , чтобы разделить Python3 решить проблему файла текстового кодирующий читать по- китайски, имеет хорошую эталонное значение, мы хотим помочь. Приезжайте и посмотрите вместе следовать Xiaobian
описание проблемы
Попытка написать Wordcloud с Python, были кодирования проблемы.
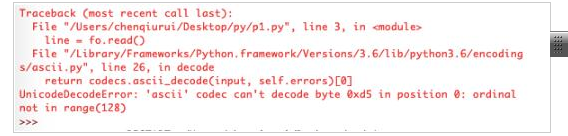
Некоторые говорят , что Интернет блог светит после Tian Tian изменения к изменению, в результате превращается в «UnicodeDecodeError:„UTF-8“ кодек не может декодировать байт ...» ошибка.
Fiddle день ах, TXT (здесь мое сердце имеет много уроков для выражения). И, наконец, просто написать самый простой для чтения файла, или даже ошибки. Так что не считается TXT кодирования проблемы, так как текстовый файл для чтения на Mac новый обычный текстовый файл, а не момент, чтобы увидеть, где найти код, наконец, копируется в систему Windows, см кодировку текстовый файл, оказавшийся ASCII, а не мой любимый UTF-8, Mac ты предал мое доверие к вам много ах! [Эпсилон] (┬┬﹏┬┬) 3
Решения
Формат кодирования в текстовый файл может быть изменен на UTF-8
Кроме того, при открытии файла, чтобы добавить третий параметр, кодирующим = «utf8» (без бара).
with open('./test3.txt','r',encoding='utf8') as fin:
for line in fin.readlines():
line = line.strip('\n')
Прикрепленный ниже исходного слова облако первого успешного отображения (см другие в Интернете, отмечает в деталях)
import jieba
import jieba.analyse
from matplotlib import pyplot as plt
from scipy.misc import imread
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
# 1.读取数据
with open("./test.txt","r",encoding="utf8") as f:
text = f.read()
# 2.基于 TextRank 算法的关键词抽取,top50
keywords = jieba.analyse.textrank(text, topK=50, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
file = ",".join(keywords)
# 指定中文字体,不然中文显示框框
font = r'./HYQiHei-25J.ttf'
print(file)
# 指定背景图,随意
image = imread('cake.jpg')
wc = WordCloud(
font_path=font,
background_color='white',#背景色
mask=image,#背景图
stopwords=STOPWORDS,#设置停用词
max_words=100,#设置最大文字数
max_font_size=100,#设置最大字体
width=800,
height=1000,
)
#生成词云
image_colors = ImageColorGenerator(image)
wc.generate(file)
# 使用matplotlib,显示词云图
plt.imshow(wc) #显示词云图
plt.axis('off') #关闭坐标轴
plt.show()
# 保存图片
wc.to_file('news.png')
Мы рекомендуем питон обучение сайтов , чтобы увидеть , как обучение пожилых людей ! Из базового сценария питона, рептилий, Джанго, сортировочные элементы данных интеллектуального анализа данных, программирование методов, а также для борьбы с нуля, каждому дается любовь обучения питона маленького партнера! Python ветеран день должен объяснить временные технологии, чтобы поделиться некоторыми из способов узнать и нужно обратить внимание на мелкие детали, нажмите на Присоединяйтесь к нам питон обучаемым собрать
над этой проблемой Python3 чтением китайского текстового файла закодирован небольшой серия для каждого человека на акцию то все содержимое, мы надеемся дать вам ссылку, я надеюсь , что вы будете поддерживать скрипт дома
