引言
本文主要探讨生成模型。在图片分类任务中,我们可以让机器知道猫和狗的不同,但它没有真正了解猫和狗是什么。也许当机器能自己画出一只猫的时候,那它才是真正知道猫是什么了。
关于这个主题有3个主要的方法:
- PixelRNN
- Variational Autoencoder(VAE)
- Generative Adversarial Network(GAN)
先来了解下PixelRNN
PixelRNN
为了生成一张图片(eg,画出一只猫),每次只会一个像素点。
假设要画3 x 3的图片。
首先啥像素点都没有,那就随机给它一个颜色的像素点。
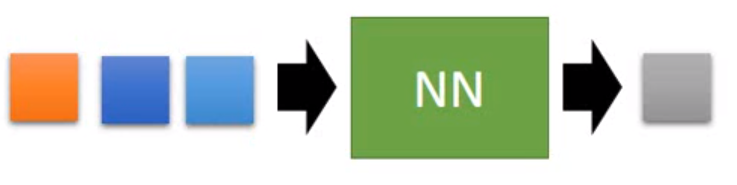
每个像素点都是一个3维的向量,R,G,B
假设是一个橙色的。

接下来就训练一个模型(神经网络模型,这里是循环神经网络,后面的文章会介绍),它的输入是刚才这个橙色的像素点,输出就是接下来要画的像素点。

假设它输出的是蓝色的像素点,就把它加到要画的图片上面。

现在图上有两个点了,那么再用同一个模型来生成下一个点,注意现在的输入是这两个点了。

假设它输出的是一个浅蓝色的点。

这里为什么可以输入两个点呢,因为RNN可以处理变长的输入。
现在图片上有三个点了,接下来就把这三个点做为输入,又可以得到一个点。
然后重复刚才的步骤,直到9点个全都生成完成。

假设最终生成的如上。PixelRNN主要做的事情就是这个。
看起来很简单,那它的表现会好吗。

这是真实世界的一只狗,假设把它的下半身挡住,让机器通过PixelRNN来生成它的下半身。

机器生成的狗图像是上面这三种。其实这表现已经很不错了。
它不仅可以用于图像上,还可以用在语音上。非常著名的例子就是wavenet,可以用来做语音合成。

红色框中的声音信号是已有的,蓝色框的都是生成的。
创造宝可梦
还是以宝可梦为例,现在我们看如何生成宝可梦。
我们可以得到792张宝可梦的小图,在让机器看完这些图片后,让它生成新的宝可梦。
原来的图像是40x40的,这里只取中间的20x20部分。

20x20的是这个样子。
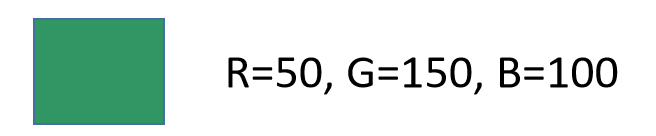
每个像素用3个数字来描述。实际上这样做生成的像素点都偏向灰色。如果想产生非常鲜明的颜色,那么RGB里面需要某个特别高,其他都接近0。
但是在训练的时候往往做不到,如果把0-255正则化到0-1之间,如果输出用Sigmoid函数的话,Sigmoid函数的值往往都在0.5左右,很难生成0这种极端的值。所以生成的颜色RGB三个都差不多,看起来每张图片都是棕色或灰色的。
所以这里做了一下处理,把每个像素点都用一个1-of-N 编码的向量来表示。
在这个1-of-N编码中,每个维度都代表一个颜色。也就是说,不让它产色RGB三个去合成一个颜色,而是直接产色一个颜色。

比如说,绿色的话,只有绿色那个维度是1,其他都是0。
但是整个向量的长度是255x255x255,可能的颜色太多了。
怎么办呢,先做聚类,把接近的颜色聚到一起。

这样最终得到167个不同的颜色。
然后做PixelRNN得到一个模型,用这个模型来让机器预测它从来没看过的图像。

只给它看上半部分,让它生成下半部分。

上面是实际的图像,下面是机器生成的图像。看起来不错,但是实际上很难评价它好不好。
接下来尝试什么都不给,让机器生成一张完整的图像。为了让它每次画的图都不一样,在输出像素点的时候,我们增加个随机因素,不让它选概率最大的。

生成的图像是上面样子的。
Variational Autoencoder
在上篇文章中我们介绍过Autoencoder(自动编码器)

来回顾一下,输入一张图片,放到编码器中得到一个编码,然后再通过解码器输出一张图片,我们希望输出的图片和原图越接近越好。
在训练好这个模型后,我们可以拿出这个解码器(Decoder),再给它一个随机的编码,它的输出就是一张完整的图片。

但这样做的话得到的结果通常不会很好。
就引出了本节的主题VAE,用它来做结果就很不错。
VAE怎么做的呢?

从Auto-encoder中拿到编码器和解码器,在编码器的地方不直接输出编码,而是输出和输入向量同维度的两个向量 。这里假设是3维的。
接下来用高斯分布来生成另外3维的向量 ,
然后通过 得到一个新的向量 。这个 才是编码code。
然后丢给解码器,希望解码器能最小化重构误差(reconstruction error)。
但是仅仅这样还不够,还需要最小化下式。

用VAE生成的图像是上面的样子。
那用VAE和PixelRNN有什么区别呢,用VAE理论上可以控制你要生成的图像。

假设我们用VAE来生成宝可梦,通过训练学好了一个vae 自动编码器后,得到一个10维的编码 。
我们再把解码器的部分拿出来,因为输出的向量也是10维,我固定其中8维,只随机生成2维的点。

我们选不同的点,和剩下的8维组成一个10维的向量当成输入,看输出的图像是什么样子。
这样我们就可以看出这个编码的每个维度分别代表什么意思,这样我们可以调整这个维度来生成我们想要的图像。

然后vae产生的图像是上面这个样子,它们都是变化了2个维度的结果。可以从这个变化看出来每个维度或许真的有些含义的。
我们可以看红框标出的那一列图像,上面好像是站着的东西,下面就变成趴着了。
下面是随机另外两个维度的例子。

从这些图片看,似乎都看的不太清除,都不像一个真正的宝可梦,但是这里还是可以找到一只比较像一点的。

看起来还是有头有尾巴的。
vaa还可以写诗,对,你没看错,吟的一首好诗。
写诗
我们把图像改成句子。

先随便拿两个句子,接下来通过这个encoder,转换成两个编码,然后画到这个二维图像中。

变成了两个点,把这两个点相连,中间等距间隔的取一些点。把这些新的点丢给Decoder,还原成句子。

大概就是这样子,其实生成的很多是一窍不通的。
为什么用VAE
我们先从直觉上来看为什么要用VAE

原来的自动编码器做的事情是把每张图片变成一个编码,假设这个编码是一维,可以在图上红线内表示。
满月和弦月的图分别得到两个编码,那假设在满月和弦月之间取一个点,再把这个点做解码,最终会得到怎样的图呢。我们期待它是满月和弦月中间的样子。
因为我们用的编码器和解码器都是NN ,都是非线性的,所以很难预测在满月和弦月之间到底是什么东西。
如果用VAE的好处是,当把满月的图变成编码后,它会在这个编码上增加噪声,在绿色箭头的范围内的编码重建后都应该还是一张满月。

弦月的图也一样。

但是你会发现,在红色光标的位置,同时希望重建为满月和弦月的图。但是只能产生一张图,在做训练的时候,需要最小化MSE,这样产生的图既像满月又像弦月,就能产生界于满月和弦月中间的图。

VAE的优势就体现出来了,我们再看下VAE的图,这个
代表的是原来的编码,
代表是加上噪声以后的编码,解码器要根据加上噪声后的编码把它重建回原来的图像。

代表噪声的方差,代表噪声有多大。这里取指数为了确保它一定是正的。
是从高斯分布中生成出来的值。 当你把
乘上
再加到
的时候,就相当于把
加上了噪声。
这个 的方差是固定的,因为是从一个确定参数的高斯分布中生成出来的。但是在乘上了 以后,它的大小就有所改变。这个 决定了噪声的大小,而这个 是从编码器产生的。
也就是说机器能自动学习这个值有多大。但是仅是这样是不够的。
因为让机器决定这个 的大小,机器可以说方差为0就好了,就等于是原来的编码,这样重构后的误差是最小的。
所以需要在这个方差上做一些限制,使得它不能太小。

是蓝色的那条线, 是红色的那条线,蓝色的线减去红色的线得到的是绿色的这条线。
它的最低点是落在 的地方,当 时,方差就是 。最后的 是正则化项。
这是直观上的理由,如果比较正式的解释要怎么做。
我们回归到我们要做的事情。
现在让机器做的事情是生成宝可梦的图的话,每张宝可梦的图都可以想成是高维空间中的一个点,

那现在要做的事情就是估计这个高维空间上的概率分布 ,注意这里的 是一个向量。
只要我们知道这个 的样子,就能生成像宝可梦样子的图。
那怎么估计这个分布的样子呢,我们可以用高斯混合模型(Gaussian Mixture Model)。

我们现在有一个很复杂的分布(上图黑线),其实它是由很多个高斯用不同的权重叠加起来的结果。蓝色的线就是高斯分布。
只要高斯分布的数量够多,就可以产生很复杂的分布。
它的式子如下
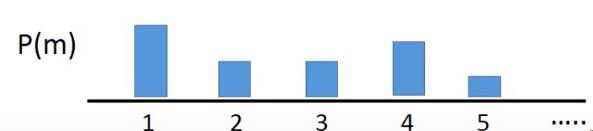
假设你要从 生成样本的时候,先决定从哪个高斯分布上生成样本,现在有很多高斯分布,每个高斯分布都有一个自己的权重。接下来根据每个权重来决定从哪个高斯上生成数据,然后再从你选择的高斯上生成数据。

那如何生成数据呢?

首先从多项分布中决定从哪个高斯分布中生成数据,
代表第几个高斯。
决定好了哪个高斯后,它会有自己的 和
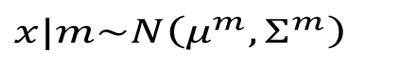
这样就可以生成一个 出来,所以 是说那个高斯的权重 乘以有了那个高斯后生成 的概率 ,然后在求和。
在高斯混合模型中有很多问题,首先你要决定高斯分布的数量,在知道了数量后,还要知道每个高斯分布的参数和权重。
现在每个 都是从某个混合模型被生成的,这个和我们做分类是一样的,每个 都是来自于某个分类。
把数据做分类其实是不够的,更好的表示方式是用分布表示(distributional representation),也就是说每个 并不是属于某个类别,而是由一个向量来描述它的各个不同的面向的特性。
VAE其实就是高斯混合模型的分布表示的版本。
怎么说呢,首先我们要产生一个向量 ,它是从高斯分布 中出来的。这个向量的每个维度代表了你要生成的东西的某种特性。

假设 是这样的。
生成了 后,根据 可以决定高斯的 。这里的 是有一个这个高斯生成的,所以它有无穷种可能。所以 也有无穷多种可能。怎么给定一个 后,得到一个 和 呢。
这里假设 都来自一个函数,把 代入产生 的函数 就能得到一个由 计算出来的 。
所以
的产生式子是这样的:


实际上在产生 的高斯分布中每个点都可能被取样到,只不过生成中间部分点的概率比较大。
当你生成了一个点后,这个点会对应一个高斯分布。现在等于有无穷多个高斯分布。
现在的问题是我们如何找到这两个函数 和
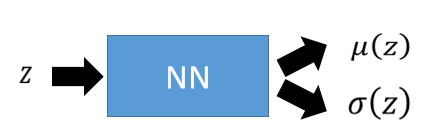
我们可以说,NN就是一个函数,这个NN输入是
,输出就是两个向量。
现在 就会变成这样子:
变成了 的概率和知道 后 的概率 对所有可能的 做积分,因为 是连续分布。

那我们要如何找到这个NN呢。
假设有了一笔 后,希望找到 和 的函数,使得下式最大。

调NN里面的参数使得
最大。
我们需要另一个分布 ,它是给定 ,决定在 上面的 ,对应VAE的编码器。
和上面的NN不同,上面的NN是给定 ,决定 的 ,对应VAE的解码器。

也就是说,我们有另外一个NN,输入 后,它会告诉你 的
回到最大化这个式子
而
因为 是一个分布,相当于一个完备事件组, 。
而
这个是根据根据条件概率公式转换过来的
接下来上下式同乘以一个
因为它们在 里面相乘,所以可以把它们转换成相加的形式:
而
就是相对熵
(衡量两个分布间的距离,大于等于0)的形式。
所以
我们把这项 记作
现在有
现在变成找 和 使得 最大。
变成了突然要多找一项。如果我们只找 这一项,来最大化 的话。这样增加 的时候,有可能会增加最大似然 ,但是你不知道 和 之间到底有什么样的关系。有可能会遇到当 上升的时候, 反而下降。

引入 可以解决这个问题。如果我们通过 来最大化 的话,首先 和 是没关系的, 只和 有关。所以不管 怎么变化, 是不变的。上图中蓝线长度是一样的,但是我们现在最大化 ,也就是要最小化 。也就是说会让 和 越来越接近。
如果固定
,一直去调整
的话,会让
一直变大,最后
会趋于0。
最后找到一个
,它和
的分布一样的话,
就会等于0,
。
这时,再增加 的话,因为最大似然 一定会比 大,所以这时可以确定 一定也会增大。这就是引入 的原因。
当你在最大化 的时候,会让 越来越小。也就是说,会让 和 越来越接近。
所以接下来要做的事情是找 和 让 越大越好,而且最后会找到 会和 很接近。
我们继续化简下

观察发现这项也是 和 的 距离表达式。

还记得吗, 这个 是个NN,给定 就能得到 的参数。
所以现在如果要最小化 (为什么是最小化,因为上式有个负号)
就是需要调 对应的这个NN,使得它产生的分布和高斯分布越近越好。
其实就是最小化

另外一项就是最大化
就是 关于分布 的期望。
相当于从 去生成数据,使得 最大。这件事情其实就是自动编码器做的事情。

把 丢到NN中,它就会生成一个 和 ( ),根据这两个参数,就得到了一个分布 ,接下来就要最大化这个分布 产生 的概率,把这个 丢到另一个NN中,产生一个均值 和方差 。一般在实际操作上,不会考虑方差,只考虑均值,只要让均值和 越接近越好。如果让这个NN输出的均值正好等于给定的输入 的话,那么这时候的 就最大。
所以其实就是自动编码器做的事情,让输入和输出越接近越好。
Conditional VAE
如果现在想让VAE产生手写数字,给它一个手写数字图片,然后它把这个数字的特性抽出来,接下来在丢进编码器的时候,可以同时给有关这个数字的特性的分布和这个数字是什么。就可以根据这个数字生成和它风格很相近的数字。

VAE的问题
VAE其实有个很严重的问题。
就是它没有真的学怎么产生一张看起来像真的图片。它所学到的事情是,它要产生一张图片和我们数据集中的某张图片越接近越好。
我们在评估它产生的图片和数据集中图片的相似度时,我们用像MSE这种方法来计算。

假设我们输出的图片和真的图片有一个像素点的差距,这个像素点在不同的位置其实会有不同的结果。VAE看这两张图片都是一样的好或不好。他没有办法产生新的图片。
所以接下来介绍另外一个方法,叫GAN(Generative Adversarial Netowrk,生成式对抗网络)
GAN
GAN是近年来复杂分布上无监督学习最具前景的方法之一。
GAN的概念有点像拟态的演化。
一种生物模拟另一种生物或模拟环境中的其他物体从而获得好处的现象叫拟态或称生物学拟态。

比如说这是一只枯叶蝶,它看起来就像一片枯叶。那它怎么会这么像枯叶呢,也许一开始它还是长得像正常的蝴蝶,但是它有类似像麻雀这种天敌,天敌会吃蝴蝶,它通常颜色来分辨蝴蝶,它知道蝴蝶不是棕色的。所以蝴蝶就演化了,变成了棕色的。

但是蝴蝶的天敌也跟着演化(进化,不进化的会饿死),它知道蝴蝶是没有叶脉的,它会吃没有叶脉的东西。
蝴蝶继续进化产生叶脉,它的天敌也会继续演化。知道最后无法分别枯叶蝶和枯叶为止。
GAN的概念是这样的,首先有第一代的生成器(Generator),它可能是随机初始的,生成的图像看上去不像真实的。

接下来有第一代的鉴别器(discriminator),它用真的图像和生成的图像做对比,调整参数,判断是否是产生的。
接下来生成器根据鉴别器来演化,它会调整参数,然后第二代的生成器产生的图像更像真的。

接下来第二代鉴别器会再次根据真实图像和生成器产生的图像来更新参数。

然后就有了第三代的生成器,它产生的图像更像真实的。第三代的生成器产生的图像可以骗过第二代的鉴别器,第二代的生成器可以骗过第一代的鉴别器。但是鉴别器也会进化,它可能可以分辨第三代产生的数字和真实的数字。
要注意的是,生成器从来没看过真正的图像是什么样的,它做的事情是要骗过看过真正图像的鉴别器。
因为生成器没有看过真正的图像,所以它可以产生出来数据集中从来没有见过的图像。
这比较像我们想要机器做的事情。
Discriminator
我们来看下分辨器是怎么训练的。
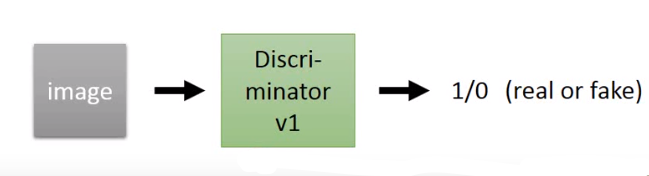
这个分辨器其实就是一个NN,它的输入是一个张图片,输出是1(真图片)或0(假图片)。
那生成器是什么呢,生成器在这里的架构和VAE的解码器一样。它也是一个NN,它的输入是从一个分部中生成出的一个向量,把这个向量丢到生成器中,就会产生一个数字样的图像。给它不同的向量可以产生不样子的图像。
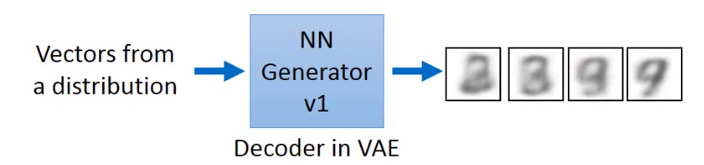
先让生成器产生一堆假的图片,然后辨别器首先将这些产生的数字图片都标记为0,把真正的数字图像都标记为1,接下来就是一个二分类问题,就是训练一个辨别器。

接下来如何训练生成器呢
Generator
现在已经有了第一代的分辨器,怎么根据第一代的分辨器,来更新第一代的生成器。
首先随机输入一个向量,生成器会产生一张图片,这张图片可能无法骗过鉴别器。
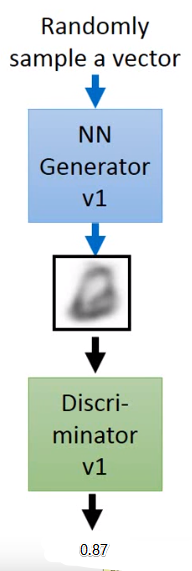
接下来调整生成器的参数,让鉴别器认为现在产生的图片是真的。就是让鉴别器输出的值越接近1越好。
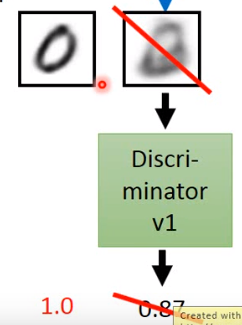
比如生成一个这样的图片就能骗过鉴别器。那么要如何做呢。
因为生成器和鉴别器都是NN,把生成器的输出,当成鉴别器的输入,然后让鉴别器产生一个标量(0~1)。
把它们看成一个整体的话,就像有个很大的神经网络,丢个随机的向量,就会产生一个数值标量。让这个输出标量接近于1是很容易的,只要做梯度下降,来更新参数就好了。
但是要注意的是,在更新这个NN的参数时,比如通过反向传播更新参数时,我们要固定鉴别器的参数,只能调整生成器的参数。
这里有个玩具例子,说的是现在有个一维的东西 ,也就是解码器的输入。

把 丢到生成器中会产生另外一个一维的东西 ,每个不同的 会得到不同的 。
就会有一个分布, 的分布就是绿色的,现在希望生成的输出越像真实数据越好,真实数据的分布是黑色的线,希望绿色的线能和黑色的线越接近越好。

如果按照GAN的概念,就是把生成的点和真实的点丢到鉴别器中,然后让鉴别器判断是真实数据的概率。鉴别器输出的就是绿色的曲线。
假设现在生成器还很弱,它生成的分布是这样的蓝色曲线。
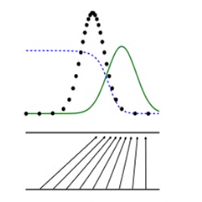
这个分辨器根据真实数据,就会判断说,如果是这样的点,那么它们比较有可能是生成的。
接下来生成器就根据辨别器的结果去调整参数,因为在上图中左边的的点更像真实数据,调整参数的结果就把它的输出往左边移。
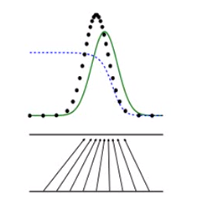
因为GAN是很难训练的,可能一次移动太多,过于偏左,因此要小心地调参数。这样绿色的分布曲线就会更加接近真正点的黑色分布曲线。
接下来分辨器会更新绿色曲线。
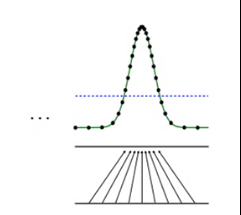
这个过程会反复进行,直到生成器产生的点分布和真实数据一样。
我们来看一个例子,下面哪个是机器产生的图片?

右边的是生成的,有21%的产生的图像能骗过人。
看起来不错是吧,实际上GAN很难去优化。因为无法衡量生成器真正的有多好。
参考
1.李宏毅机器学习
