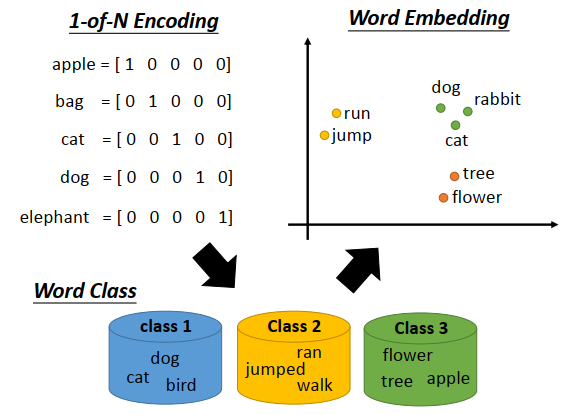
1-of-N encoding
词嵌入其实是降维的一种非常好,非常广为人知的应用。
如果要用一个向量表示一个词,最典型的做法是1-of-N encoding。每一个词用一个向量表示,向量的维度就是所有可能的词的数量,假如有10万个,那1-of-N encoding的维度就是十万维。每一个词,对应其中一维,apple就是第一维是1,其他是0,bag第二维是1,其他事0,以此类推。
用这种方式描述一个词,这个描述向量信息不丰富,不同词的词向量都是不同的,那就没办法知道词与词之间的关系,比如dog和cat都是动物这件事就没办法知道。
那怎么办呢?
有一个方法叫做建word class,就是把具有同样性质的词聚集成群,然后就用所属class来表示这这些词。这个就是降维里讲的聚类的概念。比如dog,cat,bird都是class 1,ran,jumped,walk是class 2,flower,tree,apple是class 3。不过光用class是不够的,就像光做聚类是不够的,比如class 1是动物,class 3是植物,它们都是生物,但是在word class中没法表达这件事;或者比如class 1是动物,class 2是动物可以做的动作,class 3是植物,那class 2和class 1有关系,和class 3没有关系,这在word class中也是无法表达的。
词嵌入
所以我们需要的是词嵌入,把每一个词都投影到一个高维空间上(这个高维空间比1-of-N encoding的维度要低,通常是50维、100维,从1-of-N encoding到词嵌入是降维的过程)。
上图右上方可以看到,类似语义的词更加接近。而且词嵌入的每一维,可能都有特别的含义,比如上图里的横轴维度,可能代表生物和其他东西之间的差别,纵轴维度,可能代表会动的和静止的东西之间的差别。
怎么做词嵌入?
词嵌入是一个非监督学习方法,让机器阅读大量文章,就可以让它知道每个词的嵌入特征向量应该长什么样子。
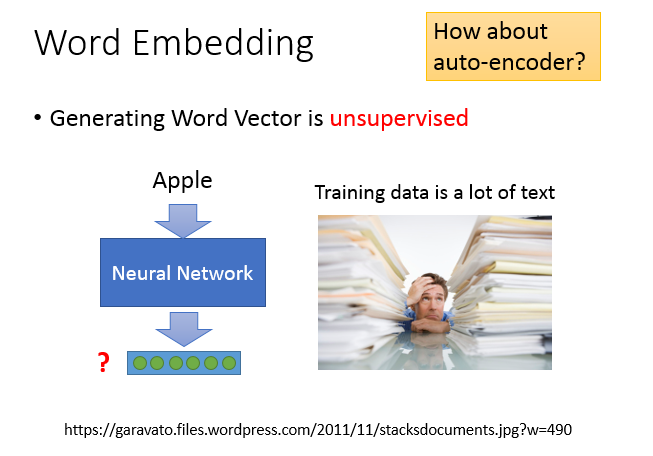
这是一个非监督的问题,我们要做的事情就是学习一个神经网络,找一个函数,input是一个词汇,output就是词汇对应的词嵌入向量。而我们的训练数据是一大堆的文字,只有input,不知道每一个词嵌入向量应该长什么样子。
对我们要找的函数来说,我们只知道输入,不知道输出,即这是一个非监督学习问题。
怎么求解这个神经网络?
之前讲过一个基于深度学习的降维方法,叫做Auto-encoder,学习一个网络,让输入等于输出,隐藏层拿出来就是降维的结果。但这里没法使用Auto-encoder,想想看对1-of-N encoding来说,每一个词汇都是独立的,那就没有办法学习出共有的特性。
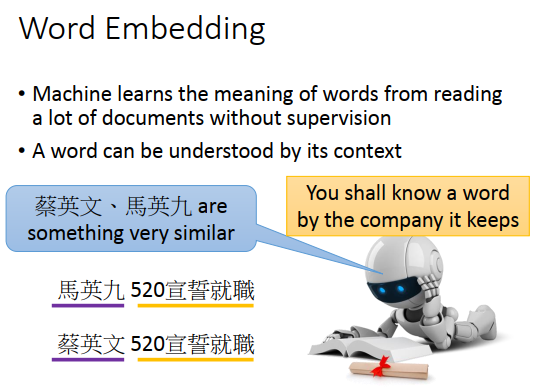
这里是这么做的,基本精神是,你要了解一个词汇的含义,需要看它的上下文。
比如有上图最下方的两段文字,对机器来说,虽然不知道马英九、蔡英文指的是什么,但是后面都接了”520宣誓就职",那机器就推论说马英九、蔡英文是某种有关系的对象,可能不知道是人,但是知道马英九、蔡英文代表了同样地位的东西。
基于计数的词嵌入

那怎么利用上下文的精神呢?
有两个不同体系的做法:
一个是基于计数的词嵌入,如果有两个词汇\(w_i,w_j\),在文章中常常同时出现,它们的词向量\(V(w_i),V(w_j)\)就会比较接近。这种方法一个代表性的例子是Glove vector。方法的原理是计算\(V(w_i),V(w_j)\)的内积,要接近于\(N_{ij}\)(\(w_i,w_j\)同时出现的次数),这个概念和矩阵分解是一样的。
基于预测的词嵌入
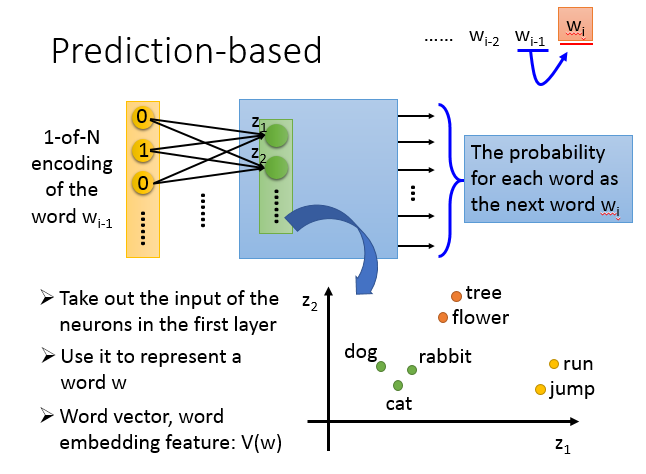
另一个是基于预测的词嵌入,学习一个神经网络,在序列中,给定前一个词汇\(w_{i-1}\),预测下一个词汇\(w_i\)是什么。我们可以把每个词汇用1-of-N encoding表示成一个特征向量,那么神经网络的input 就是\(w_{i-1}\)的1-of-N encoding向量,output是\(w_i\)为某个词汇的概率,output 维度就是所有词汇的数量,假设所有词汇是10万个,那output就有10万维,每一维代表\(w_i\)是该词汇的概率。input和output都是词典大小的向量,但是代表的意思不同。
如果神经网络是一般的深度网络结构,那input经过很多层隐藏层后,得到output。接下来我们把第一个隐藏层的input拿出来,写作\(Z=\{z_1,z_2,...\}\) ,input不同词汇的1-of-N encoding向量,\(Z\)也会不同,那么\(Z\)就可以代表一个词汇,\(Z\)就是词嵌入向量。
那么可以得到上图右下方的现象。
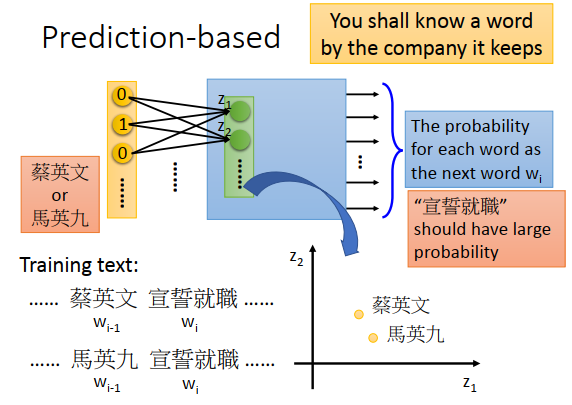
为什么用这个基于预测的方法,可以得到这样的向量,怎么体现根据上下文表达词汇的含义?
假设训练数据里有两篇文章,一篇包括“蔡英文宣誓就职”这个句子,另一篇包括“马英九宣誓就职”这个句子。在第一个句子里,“蔡英文”是\(w_{i-1}\),“宣誓就职”是\(w_i\) ,再另一个文章的句子里,“马英九”是\(w_{i-1}\),“宣誓就职”是\(w_i\) 。在训练model的时候,不管input是“蔡英文”还是“马英九”,都希望学习出来的结果是“宣誓就职”的概率比较大,即output里“宣誓就职”这一维的概率最大。
为了让不同的input在最后得到一样的output,必须先经过转换对应到接近的空间,经过隐藏层后才有同样的概率。所以当我们学习一个预测模型的时候,会自动考虑词汇上下文这件事情,把model的第一个隐藏层拿出来就可以得到我们要找的词嵌入的这种特性。
如果只用\(w_{i-1}\)去预测\(w_i\)好像太不靠谱了,就算人来预测也很难,下一个词汇的可能性太多了。
那就拓展这个问题,input变为前面的两个词汇\(w_{i-2},w_{i-1}\),output为\(w_i\)。你可以轻易的拓展到N个词汇,通常来说至少要10个词汇效果才比较好。
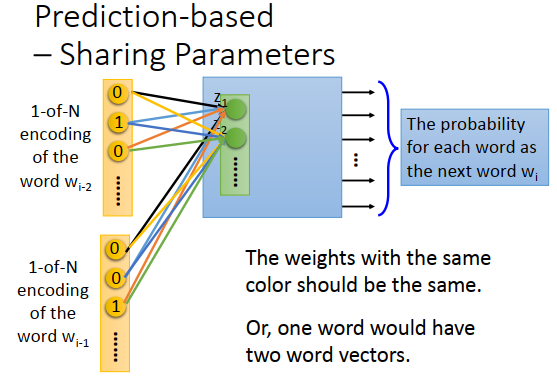
上图用2个词汇作为例子,本来一般的神经网络,就把\(w_{i-2},w_{i-1}\)的1-of-N encoding向量组合在一起变成一个长向量,然后丢到神经网络里当做input就可以了。
但是实际上做的时候,你会希望\(w_{i-2}\) 和神经元相连的权重和\(w_{i-1}\)和神经元相连的权重是一样的,看上图同样颜色的连接线。
为什么要让权重一样呢?
一个显而易见的理由是,如果我们不这么做,那把同一个词放在\(w_{i-2}\)跟\(w_{i-1}\)的位置时,通过transform之后得到的会不一样。
另外一个理由是这么做可以减少参数量,一个词汇的特征向量是10万维,就算神经元很少,那如果不共享参数的话,参数量还是太多了。
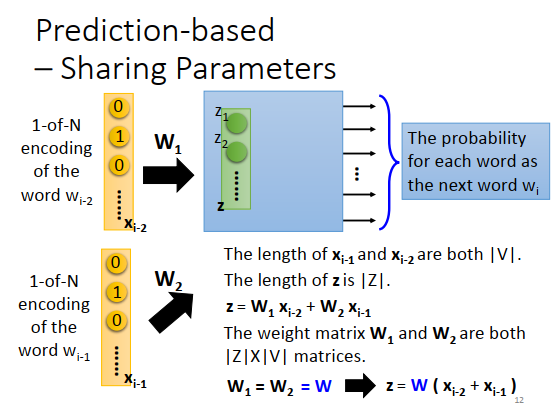
用公式表示可能更清楚一点。\(w_{i-1}\)的1-of-N encoding是\(x_{i-1}\),\(w_{i-2}\)的1-of-N encoding是\(x_{i-2}\),长度都是V的绝对值。隐藏层的input写成\(Z\),\(|Z|\)是\(Z\)的长度,\(Z=W_1x_{i-2}+W_2x_{i-1}\),\(W_1,W_2\)都是\(|Z|\times |V|\)维的权重矩阵。实际处理时我们强制让\(W_1=W_2=W\),那\(Z\)的计算公式变为\(Z=W(x_{i-2}+x_{i-1})\),先把\(x_{i-2}\)和\(x_{i-1}\)加起来,再乘上\(W\)这个transform。
把一个词汇的1-of-N encoding成上这个\(W\),就可以得到这个词汇的词嵌入向量。
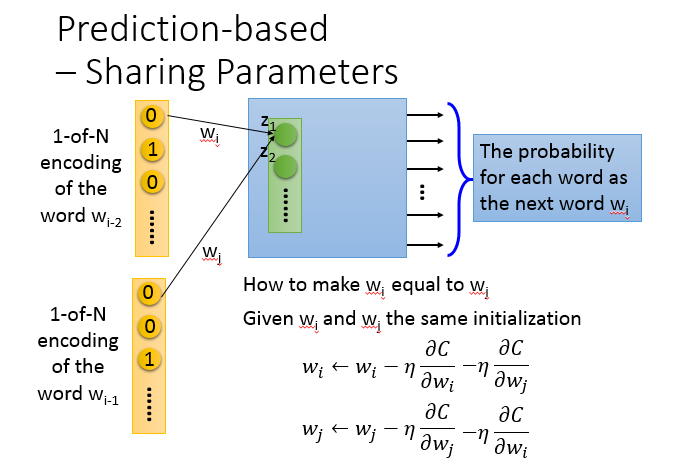
那这里有个问题,在实际操作的时候,怎么让\(W_1\)和\(W_2\)一样?
如上图所示,要让\(W_i,W_j\)一样,首先要给\(W_i,W_j\)一样的初始化,接下来计算损失函数\(C\)对\(W_i\)的偏微分,更新\(W_i\);同样计算损失函数\(C\)对\(W_j\)的偏微分,更新\(W_j\)。
如果\(C\)对\(W_i,W_j\)的偏微分不一样,那更新后的值不就不一样了吗?
我们在更新\(W_i\)的时候再减掉\(W_j\)的偏微分,更新\(W_j\)的时候再减掉\(W_i\)的偏微分,如上图右下方所示,确保\(W_i,W_j\)在更新过程中是一样的。
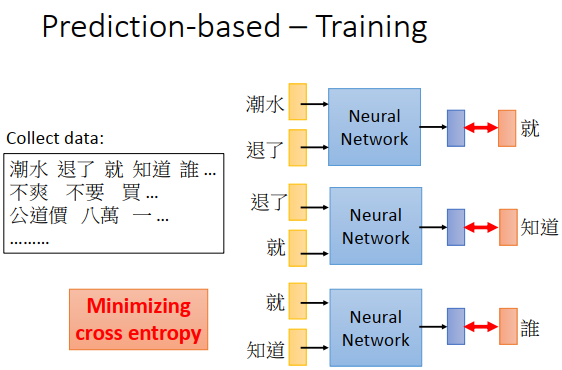
这个神经网络的训练是非监督的,只要收集一大堆文字数据,然后训练。比如上图左边的文字数据“潮水退了就只知道谁没穿裤”,在神经网络里input “潮水”和“退了”,希望output和“就”越接近越好(“就”也是一个1-of-N encoding 向量),即和“就”的1-of-N encoding 向量的交叉熵最小。然后就是input “退了”跟“就”,希望output和“知道”越接近越好,依次类推如上图右边所示。
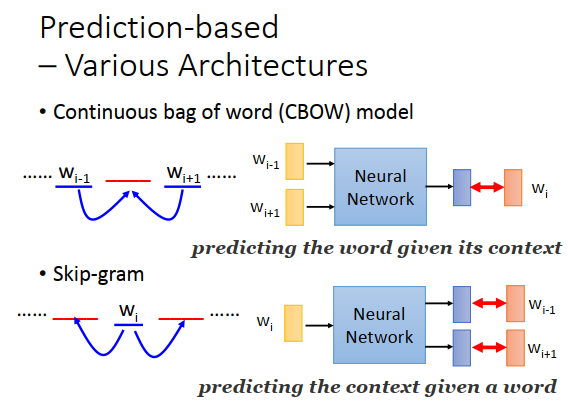
之前讲得基于预测的词嵌入是最基本的形态,还可以有各种变形。目前还不确定,在各种变形中哪一种比较好。
有一种变形叫做连续词贷(continuous bag of word model,CBOW)。之前是说拿前面的词汇去预测后面的词汇,CBOW则是拿待预测词汇的上下词汇,拿\(w_{i-1},w_{i+1}\)去预测\(w_i\)。
有一种变形叫做Skip-gram,拿\(w_i\)去预测\(w_{i-1},w_{i+1}\) 。
如果你读过词向量的文献,会发现这个神经网络不是deep的,只有一个线性的隐藏层,input 词汇后,得到词嵌入向量,再经过隐藏层得到output。
我们知道词向量可以得到一些有趣的特性。
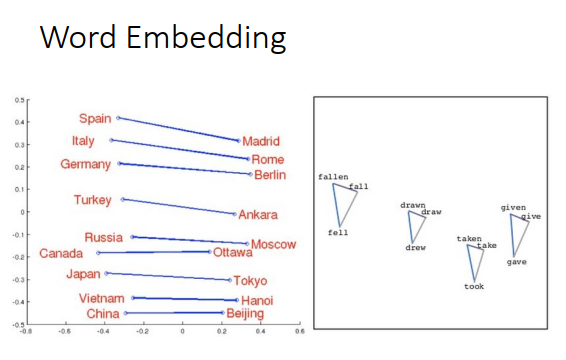
如果你把同样类型的东西的词向量放在一起,如上图左边,把Italy和它的首都Rome放在一起,把Germany和它的首都Berlin放在一起,你会发现它们之间有某种固定的关系。
或者把动词的三态放在一起,会发现同一个动词的三态有某种固定的关系(三角形)。
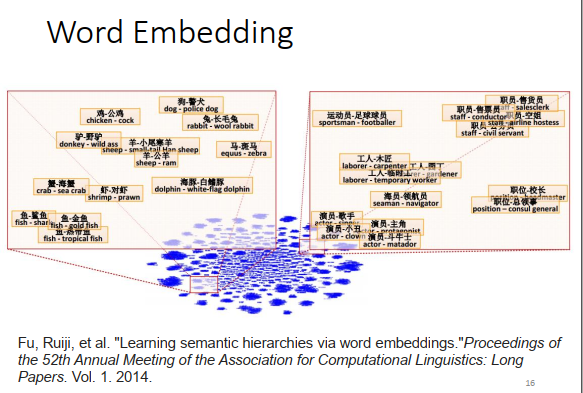
从词向量里,你可以发现词与词之间的关系。如果把词向量两两相减,然后投影到一个二维的空间上,如果位置落在上图红色框框里,会发现某个词的含义包含另一个词的含义,比如海豚-白鳍豚,演员-主角等等。如果某个词的属于另外一个词,那把它们的词向量两两相减,得到的结果会是类似的。

用词向量的概念,可以做一些简单的推论。
如果hotter的词向量-hot的词向量接近于bigger的词向量-big的词向量
或者Rome的词向量-Italy的词向量接近于Berlin的词向量-Germany的词向量。
如果有人问你,罗马之于意大利就好像柏林之于什么,那么机器就可以回答这种问题了。
因为\(V(Germany) \approx V(Berlin)-V(Rome)+V(Italy)\),得到的答案就是Germany。
多语言嵌入
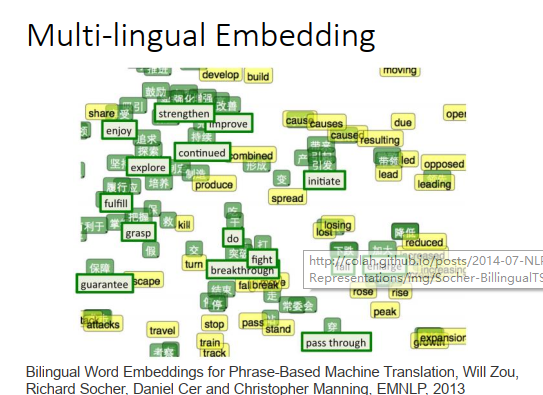
词向量可以做很多其他事情,比如可以把不同语言的词向量放在一起。如果有一个中文的语料库,英文的语料库,各自训练一组词向量,你会发现中文和英文的词向量完全没有关系。因为训练词向量的时候,凭借的是上下文的关系,所以如果语料库里面没有中文和英文的句子(词汇)混杂在一起,那机器就没法判断中文词汇和英文词汇之间的关系。
但是如果你已经事先知道某几个中文词汇和英文词汇是对应的,那先得到一组中文词向量,再得到一组英文词向量,接下来你可以再训练一个model,把中文和对应英文都投影到同一点(上图绿色点所示就是已经实现知道对应关系的词汇)。有了这个transform之后,有新的中文和新的英文词汇时,可以用同样的transform投影到同一个空间上面。比如中文“降低”和英文“reduce”落在差不多的位置。这样就可以做到类似翻译的效果。
多域嵌入
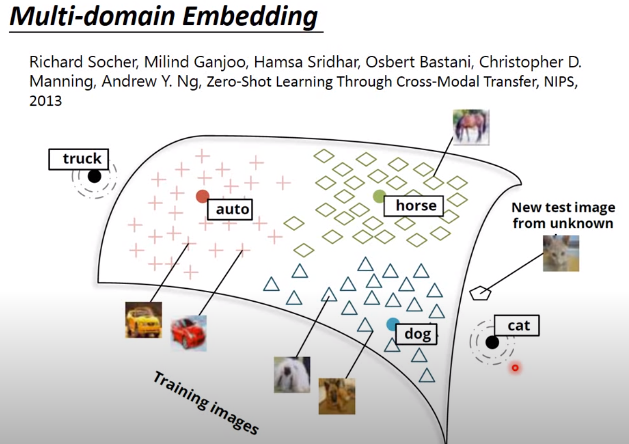
词嵌入方法不只限于文字,你可以对影像做嵌入。
比如上面的例子,已经找到一组词向量,比如dog的词向量,horse的词向量,auto的词向量,cat的词向量,如上图所示分布在空间上。接下来学习一个model,input 是一张图像,output是一个跟词向量维度相同的向量。那你会希望dog的output就散布在dog词向量周围,horse的output就散布在horse词向量周围等等。假设你已经知道某些图像属于哪一类了,你就可以把它们投影到它们对应的词向量附近。
这个有什么用?
如果有新的图像,就可以通过投影到这个空间上,可能就会在cat词向量附近,那么机器就判断为cat。一般做图像识别的时候,机器很难处理新增的没有看过的对象,比如学习model时是10个类,那这个model就只能分这10个类,如果今天有个新东西不在这10个类里面,这个model就无能为力了。但是使用词嵌入的方法,就算图像属于没有见过的类,比如上图cat这张图像,cat类不在训练集里,投影到cat词向量附近的话,机器也会判读为cat。
像dog和cat看起来是有联系,因此model虽然没有看过cat类,但是也能处理图片中相似的部分,最后的output 向量会远离dog类,接近cat类。
document embedding
除了可以做word embedding,也可以做document embedding,可以把一个document 变为一个向量。
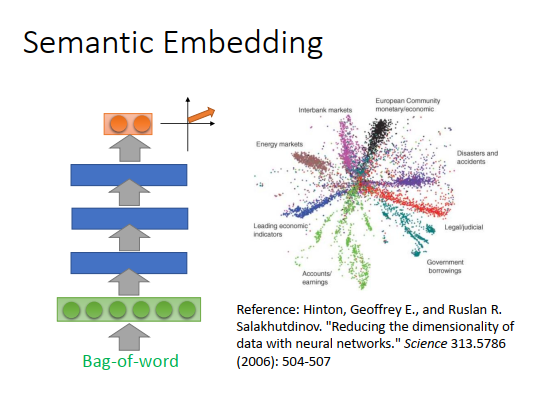
那怎么做document embedding?
最简单的方法是把一个document 变成一个word,然后用auto-encoder学习出这个文档的语义嵌入向量。但光用词描述一个文档是不够的。

我们知道词汇的顺序代表了很重要的含义。
举例如上图两个句子,具有相同的词贷,但是顺序不同,上面的句子是正面的,下面的句子是负面的,在语义上是完全不同的。所以光用词贷描述是不够的,会失去很多重要的东西。

上面是怎么做的论文。