匹配数据的图像转换
Pix2Pix在图像到图像的转换这个领域中有很好的应用,它能够面向所有匹配图像数据集的训练和生成。
匹配数据集是指在训练集中两个互相转换的领域之间有很明确的一一对应数据。比如下面的三个例子:

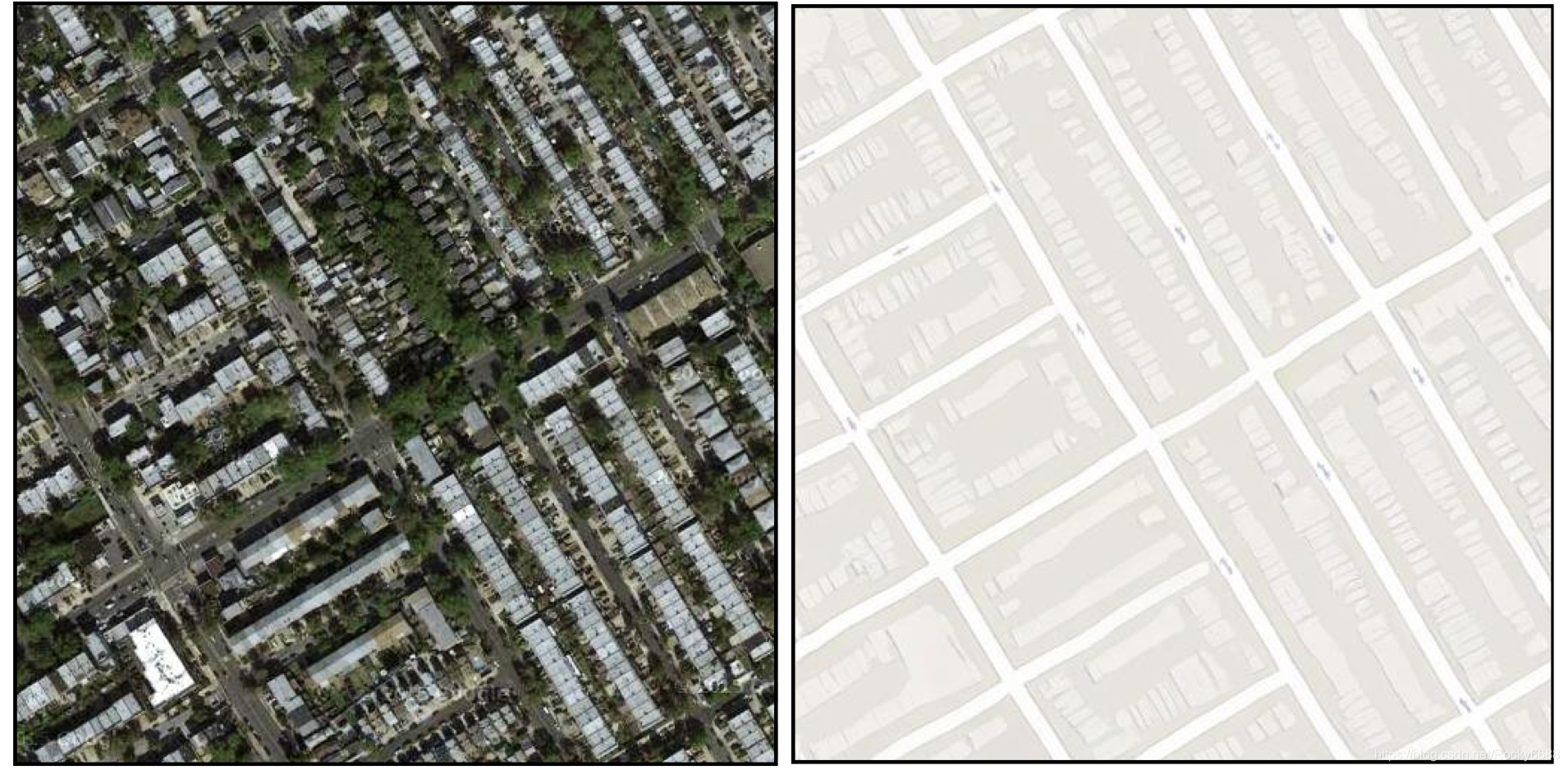

在工程实践中研究者需要自己收集这些匹配数据,但有时同时采集两个不同领域的匹配数据是非常麻烦的,通常采用的方案是从更完整的数据中还原简单数据。
有了匹配数据集的存在,深度学习领域的研究者已经尝试使用卷积神经网路来解决这类“图像翻译问题”,但是最终的图像转换会非常模糊,因为卷积神经网络会试图让最终的输出接近所有相类似的结果。而以生成对抗网络为基础的Pix2Pix可以很好地避免这一问题。
Pix2Pix的理论基础
Pix2Pix采用了CGAN的思想,将输入的图像作为生成对抗网络的条件。在网络结构的设计上,Pix2Pix基本参考了DCGAN的结构,使用了卷积层、BN层以及ReLU激活函数。
CGAN相关知识
DCGAN相关知识

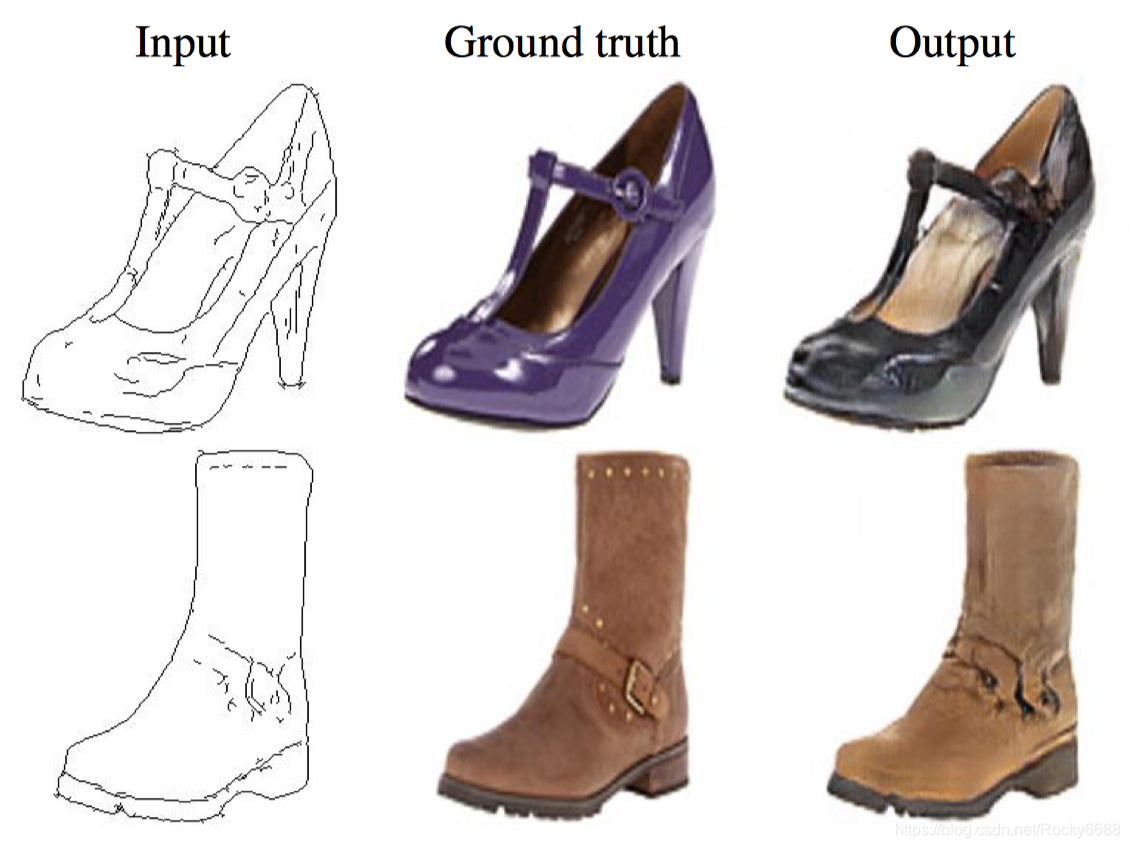
如上图所示,手绘鞋子和真实鞋子图像是一组配对数据,生成器通过作为条件的手绘数据生成了左图中的鞋子,然后我们将两者放入两者放入判别器中,判别器应该判断为假,而当我们将真实的配对数据输入时,判别器应该判断为真。
Pix2Pix的目标函数
Pix2Pix的目标函数由两部分组成,分别是CGAN的目标函数和L1损失函数。
CGAN目标函数:
上式中 表示真是配对数据输入图像x与输出图像y对于判别器D的结果,而 则是x经过生成器产生的图像 对于判别器判断的结果。
L1损失函数:
Pix2Pix最终的目标函数为:
其中 为超参数,可以根据情况调节,当 时表示不采用L1损失函数。
下图是不同目标函数状态下的测试结果:

可以看出L1 + CGAN的组合是最接近理想状态的。
PatchGAN的思想
我们可以总结出L1损失函数用于生成图像的大致结构、轮廓等,也可以说是图像的低频部分。而CGAN则主要用于生成细节,是图像的高频部分。
Pix2Pix认为既然GAN仅用于高频部分的生成,那么在训练过程中也没有必要把整个图像都拿出来做训练,仅需把图像的一部分作为判别器的接受区域即可,这也就是PatchGAN的思想。由于参数更少,PatchGAN可以使得训练过程变得更加高效,同时也可以针对更大的图像数据集进行训练。
下图为不同Patch进行测试的结果,其中1 * 1像素称为PixelGAN,全图像素称为ImageGAN。

可以看出70 * 70的PatchGAN取得了最好的成绩。
生成器结构设计
在生成器结构设计上,最简单的想法是下图左边的编/解码器网络,通过左侧的不断下采样到达中间的隐含编码层,然后再通过右侧的上采样来还原图像。这样的结构似乎少利用一些匹配图像数据中已有的信息。为了可以利用这样的信息,我们也可以使用下图右边的U-Net结构。它与自动编码器网络不同的是,左侧和右侧的网络追安添加了很多跳跃连接,可以将部分有用的重复信息直接共享到生成器中。
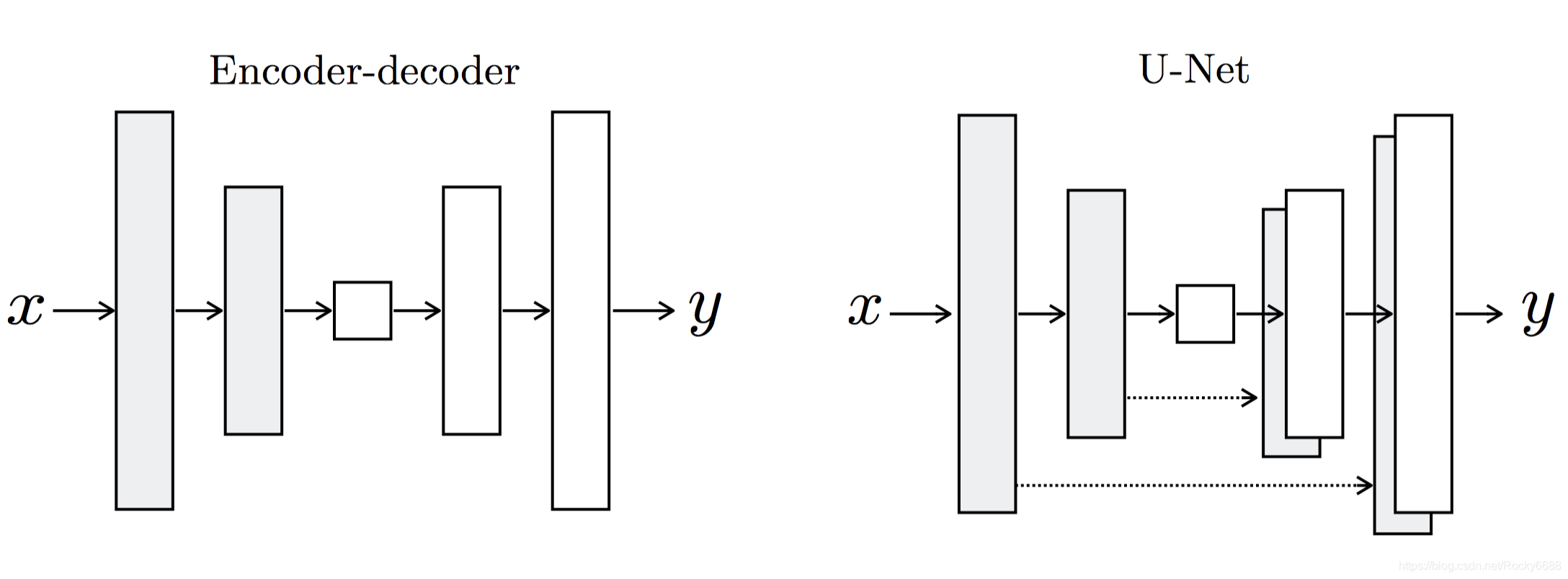
下图比较了不同网络之间的差别,使用U-Net的L1+CGAN的方案表现最优

一些例子