年轻的时候,我们爱得死去活来,可随着年岁渐长,你就会发现,爱情并不是生活的全部。
善良,努力,读书,健身,让自己变得更好才是人生最重要的事。
前言
简介:伯克利大学研究提出的使用条件对抗网络作为图像到图像转换问题的通用解决方案。图像到图像转换的问题其实也就是像素到像素(Pix2Pix)的映射问题。
Github Demo:Pix2Pix
官网:Image-to-Image Translation with Conditional Adversarial Nets
论文:Image-to-Image Translation with Conditional Adversarial Networks
前阵子很出名的DeepNude:DeepNude-an-Image-to-Image-technology
原理介绍
GAN实现原理:GAN 在结构上受博弈论中的二人零和博弈 (即二人的利益之和为零,一方的所得正是另一方的所失) 的启发,系统由一个生成器和一个判别器构成。
| 名词 |
说明 |
| GAN |
生成对抗网络,Generative adversarial networks。 |
| Generator |
生成器,尽量去学习真实的数据分布。 |
| Discriminator |
判别器,尽量正确的判别输入数据是来自真实数据还是来自生成器。 |
| 训练结束标准 |
当最终 D 的判别能力提升到一定程度,并且无法正确判别数据来源时,可以认为这个生成器 G 已经学到了真实数据的分布。 |
价值函数表达
V(G,D)=Ex∼pdata(x)logD(x)+Ez∼pz(z)log(1−D(G(z)))
| 参数 |
解析 |
|
Gmin Dmax |
零和博弈 |
|
D |
可微判别器函数 |
|
G |
可微生成器函数 |
|
E |
数学期望 |
|
x∼pdata |
x服从于真实数据
data的概率密度 |
|
z∼ pz(z) |
z服从于初始化数据的概率密度 |
|
logD(x) |
正类的对数损失函数(正类:即能判别出x属于真实分布。) |
|
log(1−D(G(z))) |
负类的对数损失函数(正类:即能判别出x属于生成分布。) |
|
Ex∼pdata(x)logD(x) |
根据正类的对数损失函数构建,取最大值则意味着令判别器
D在
x服从于
data的概率密度时能准确预测
D(x)=1,即
D(x)=1 when x∼pdata(x)。 |
|
Ez∼pz(z)log(1−D(G(z))) |
根据负类的对数损失函数构建,企图欺骗判别器的生成器。 |
零和博弈函数表达
根据上述的价值函数,可以提出零和博弈函数。
给定生成器
G,由价值函数可以推导出最优判别器的表述
DG∗为:
DG∗=argDmaxV(G,D)
其中
argmax表示取得最大值时的参数的意思。因此,
argDmaxV(G,D)指的是当
D取特定值的时
V(G,D)的最大值。
当生成器
D使得
V(G,D)达到最大值的时候,即最优的情况
D=DG∗的时候,固定
D,开始训练
G。根据
DG∗可以推导出最优生成器
G:
G∗=Gmin DmaxV(G,D)=Ex∼pdata(x)logD(x)+Ez∼pmodellog(1−D(G(z)))
- 备注:
E指的也是数学期望。
最后,我们可以将最优生成器表达为:
G∗=arg GminV(G,DG∗)
当然,这仅仅是其中的一次优化的过程。这个过程会持续很多次,直到一个临界点才终止。
临界值推导
任意可微分的函数都可以用来表示 GAN 的生成器和判别器。——《生成式对抗网络GAN的研究进展与展望》
在 GAN 原论文中,有一个思想和其它很多方法都不同,即生成器 G 不需要满足可逆条件。
在极大极小博弈的第一步中,给定生成器
G,最大化
V(D,G)得到最优判别器
D。最大化
V(D,G)评估了
PG和
Pdata的数据差异。由于原论文中价值函数可写为在
x上的积分形式,即将数学期望展开为积分形式:
V(G,D)=∫xpdata(x)logD(x)+pG(x)log(1−D(x)) dx
令
pdata(x)=a,
D(x)=y,
pG(x)=b得:
f(y)=a log y+b log(1−y)
f(x)一阶导数:
f′(x)=ya−1−yb=0
由此可得:
y=a+ba
f(x)二阶导数:
f′′(a+ba)=−(a+ba)2a−(1−a+ba)2b<0
一阶导数为0有解,且二阶导数小于0,因此
a+ba为极大值点。
因此,价值函数可以等价为:
V(G,D)=∫xymax pdata(x)log y+pG(x)log(1−y) dx
因此,最优的生成器
DG∗为:
DG∗=pdata+pGpdata=21
这个时候判别器已经不能区分数据是否真实了,基于这个观点,GAN的作者也证明了
G就是极大极小博弈的解了。
训练过程
当寻找最优的生成器
G的时候,那么给定一个判别器
D,可以将
GmaxV(G,D)看作训练生成器的损失函数
L(G),有了损失函数,我们就可以使用
SDG、
Adam等优化算法更新生成器
G的参数,梯度下降的参数优化过程为:
θG←θG−η∂θG∂L(G)
-
θ表示输入参数。
- 详细推导可以看:
Pix2Pix
日前很火的DeepNude就是基于这个原理实现的。
普通GAN原理简介
普通的GAN:
- Generator的输入Input是随机向量,输出的是图像;
- Discriminator的输入Input是图像(生成的图像、真实的图像),输出是对或者错。
在不断的博弈的过程中,就可以相互增强,直到生成的图像使得判别器真假难辨为止。
cGAN原理介绍
cGAN,即Conditional GAN:
- Generator的输入Input是图像和随机向量,输出的是图像;
- Discriminator的输入Input是图像(生成的图像、真实的图像),输出是对或者错。
在不断的博弈的过程中,就可以相互增强,直到生成的图像使得判别器真假难辨为止。
换而言之:
- 传统GAN,从随机向量
z学到图像y:
G:z→y
- cGAN,从输入图像
x和随机向量
z学到图像
y:
G:{x,z}→y
网络结构简介

生成器
G用到的是U-Net结构,输入的轮廓图
x编码再解码成真是图片,判别器
D用到的是作者自己提出来的条件判别器PatchGAN,判别器
D的作用是在轮廓图
x的条件下,对于生成的图片
G(x)判断为假,对于真实判断为真。
结构说明
由于
L1 Loss和
L2 Loss可以较好的恢复图像的低频部分,GAN Loss可以较好的恢复图像的高频部分。
LcGAN(G,D)
LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
L1 Loss
LL1(G)=Ex,y,z[∣∣y−G(x,z)∣∣1]
因此,作者采用了两者相结合的方式,目标函数可以表达为:
G∗=arg GminDmaxLcGAN(G,D)+λLL1(G)
效果如下图(梯度下降使用SGD和Adam):
![)(loss_example.png)]](https://img-blog.csdnimg.cn/20190722221020260.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L05vdHp1b25vdGRpZWQ=,size_16,color_FFFFFF,t_70)
L1 Loss和
L2 Loss
| 名称 |
损失函数 |
导数 |
|
L1 Loss |
∣f(x)−Y∣ |
±f′(x) |
|
L2 Loss |
∣f(x)−Y∣2 |
2(f(x)−Y)f′(x) |

损失函数对于色彩的影响
 可以看出,
L1对颜色的感受野比较小,因此生成的图像的颜色范围没那么丰富。
可以看出,
L1对颜色的感受野比较小,因此生成的图像的颜色范围没那么丰富。
U-Net
U-net采用了完全不同的特征融合方式:拼接,U-net采用将特征在
Channel维度拼接在一起,形成更厚的特征。

Skip-Connect
使用Skip-Connect可以解决梯度消失的问题。
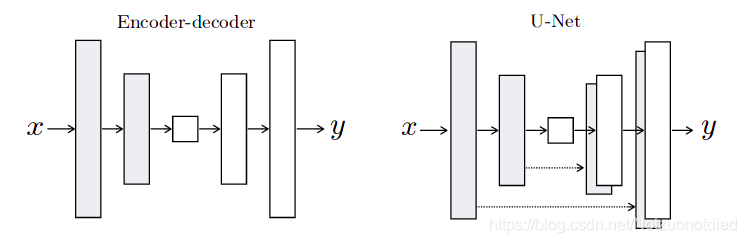
U-Net的作用

U-Net中使用了skip-connection,大大提高了生成后的图像质量。
PatchGAN
用
L1 Loss和
L2 Loss重建的图像很模糊,也就是说
L1和
L2并不能很好的恢复图像的高频部分(图像中的边缘等),但能较好地恢复图像的低频部分(图像中的色块)。为了能更好得对图像的局部做判断,作者提出PatchGAN的结构,也就是说把图像等分成Patch,分别判断每个Patch的真假,最后再取平均!作者最后说,文章提出的这个PatchGAN可以看成所以另一种形式的纹理损失或样式损失。在具体实验时,不同尺寸的Patch,最后发现70x70的尺寸比较合适。
 这里其实也可以解释为什么
arg Gmin Dmax的
arg是怎么得来的了。其实就是因为PatchGAN最后得出来的结果需要求均值。
这里其实也可以解释为什么
arg Gmin Dmax的
arg是怎么得来的了。其实就是因为PatchGAN最后得出来的结果需要求均值。
效果





展望
Pix2Pix本身也有一定的局限性,论文作者承认,这种结构其实学到的是
x到
y之间的一一对应,Pix2Pix就是对Ground Truth的重建。输入轮廓图→经过U-Net编码解码成对应的向量→解码成真实图。
这种一对一映射的应用范围十分有限,当我们输入的数据与训练集中的数据差距较大时,生成的结果很可能就没有意义,这就要求我们的数据集中要尽量涵盖各种类型。

当我们输入训练集中不存在的轮廓图时,得到以下:

我们可以看出,服装的形态还是可以保持的,但是生成图像的颜色并不能令人满意。
总结
Pix2Pix论文要点:
- cGan:替换向量输入为图像输入。
- U-Net:使用Skip-connection(残差连接)来共享贡多信息。
- PatchGAN:降低计算量提升效果。
-
L1 Loss:加入
L1损失函数提高了生成的图像的质量。
附录
本文经过参考以下文章整理出来。
GAN公式推导
PixPix
其他
