信用风险计量体系包括主体评级模型和债项评级两部分。主体评级和债项评级均有一系列评级模型组成,其中主体评级模型可用“四张卡”来表示,分别是A卡、B卡、C卡和F卡;债项评级模型通常按照主体的融资用途,分为企业融资模型、现金流融资模型和项目融资模型等。 我们主要讨论主体评级模型的开发过程。
一、项目流程
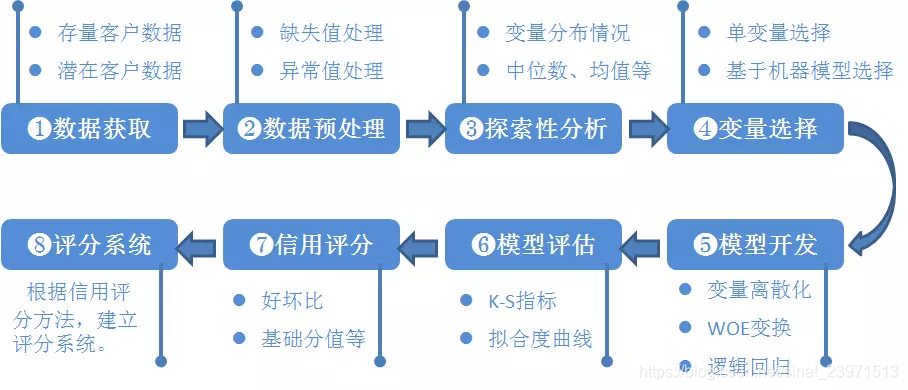
典型的信用评分模型如图1-1所示。信用风险评级模型的主要开发流程如下:
(1) 数据获取,包括获取存量客户及潜在客户的数据。存量客户是指已经在证券公司开展相关融资类业务的客户,包括个人客户和机构客户;潜在客户是指未来拟在证券公司开展相关融资类业务的客户,主要包括机构客户,这也是解决证券业样本较少的常用方法,这些潜在机构客户包括上市公司、公开发行债券的发债主体、新三板上市公司、区域股权交易中心挂牌公司、非标融资机构等。
(2) 数据预处理,主要工作包括数据清洗、缺失值处理、异常值处理,主要是为了将获取的原始数据转化为可用作模型开发的格式化数据。
(3) 探索性数据分析,该步骤主要是获取样本总体的大概情况,描述样本总体情况的指标主要有直方图、箱形图等。
(4) 变量选择,该步骤主要是通过统计学的方法,筛选出对违约状态影响最显著的指标。主要有单变量特征选择方法和基于机器学习模型的方法 。
(5) 模型开发,该步骤主要包括变量分段、变量的WOE(证据权重)变换和逻辑回归估算三部分。
(6) 模型评估,该步骤主要是评估模型的区分能力、预测能力、稳定性,并形成模型评估报告,得出模型是否可以使用的结论。
(7) 信用评分,根据逻辑回归的系数和WOE等确定信用评分的方法。将Logistic模型转换为标准评分的形式。
(8) 建立评分系统,根据信用评分方法,建立自动信用评分系统。
PS:有些时候为了便于命名,相应的变量用标号代替
二、数据获取
数据来自Kaggle的Give Me Some Credit,有15万条的样本数据,下图可以看到这份数据的大致情况。
数据属于个人消费类贷款,只考虑信用评分最终实施时能够使用到的数据应从如下一些方面获取数据:
– 基本属性:包括了借款人当时的年龄。
– 偿债能力:包括了借款人的月收入、负债比率。
– 信用往来:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90
天或高于90天逾期的次数。
– 财产状况:包括了开放式信贷和贷款数量、不动产贷款或额度数量。
– 贷款属性:暂无。
– 其他因素:包括了借款人的家属数量(不包括本人在内)。
– 时间窗口:自变量的观察窗口为过去两年,因变量表现窗口为未来两年。

三、数据预处理
在对数据处理之前,需要对数据的缺失值和异常值情况进行了解。Python内有describe()函数,可以了解数据集的缺失值、均值和中位数等。
#载入数据
data = pd.read_csv('cs-training.csv')
#数据集确实和分布情况
data.describe().to_csv('DataDescribe.csv')
数据集的详细情况:

从上图可知,变量MonthlyIncome和NumberOfDependents存在缺失,变量MonthlyIncome共有缺失值29731个,NumberOfDependents有3924个缺失值。
3.1 缺失值处理
这种情况在现实问题中非常普遍,这会导致一些不能处理缺失值的分析方法无法应用,因此,在信用风险评级模型开发的第一步我们就要进行缺失值处理。缺失值处理的方法,包括如下几种。
(1) 直接删除含有缺失值的样本。
(2) 根据样本之间的相似性填补缺失值。
(3) 根据变量之间的相关关系填补缺失值。
变量MonthlyIncome缺失率比较大,所以我们根据变量之间的相关关系填补缺失值,我们采用随机森林法:
# 用随机森林对缺失值预测填充函数
def set_missing(df):
# 把已有的数值型特征取出来
process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]]
# 分成已知该特征和未知该特征两部分
known = process_df[process_df.MonthlyIncome.notnull()].as_matrix()
unknown = process_df[process_df.MonthlyIncome.isnull()].as_matrix()
# X为特征属性值
X = known[:, 1:]
# y为结果标签值
y = known[:, 0]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0,
n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
# 用得到的模型进行未知特征值预测
predicted = rfr.predict(unknown[:, 1:]).round(0)
print(predicted)
# 用得到的预测结果填补原缺失数据
df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome'] = predicted
return df
NumberOfDependents变量缺失值比较少,直接删除,对总体模型不会造成太大影响。对缺失值处理完之后,删除重复项。
data=set_missing(data)#用随机森林填补比较多的缺失值
data=data.dropna()#删除比较少的缺失值
data = data.drop_duplicates()#删除重复项
data.to_csv('MissingData.csv',index=False)
3.2 异常值处理
缺失值处理完毕后,我们还需要进行异常值处理。异常值是指明显偏离大多数抽样数据的数值,比如个人客户的年龄为0时,通常认为该值为异常值。找出样本总体中的异常值,通常采用离群值检测的方法。
首先,我们发现变量age中存在0,显然是异常值,直接剔除:
# 年龄等于0的异常值进行剔除
data = data[data['age'] > 0]
对于变量NumberOfTime30-59DaysPastDueNotWorse、NumberOfTimes90DaysLate、NumberOfTime60-89DaysPastDueNotWorse这三个变量,由下面的箱线图图3-2可以看出,均存在异常值,且由unique函数可以得知均存在96、98两个异常值,因此予以剔除。同时会发现剔除其中一个变量的96、98值,其他变量的96、98两个值也会相应被剔除。
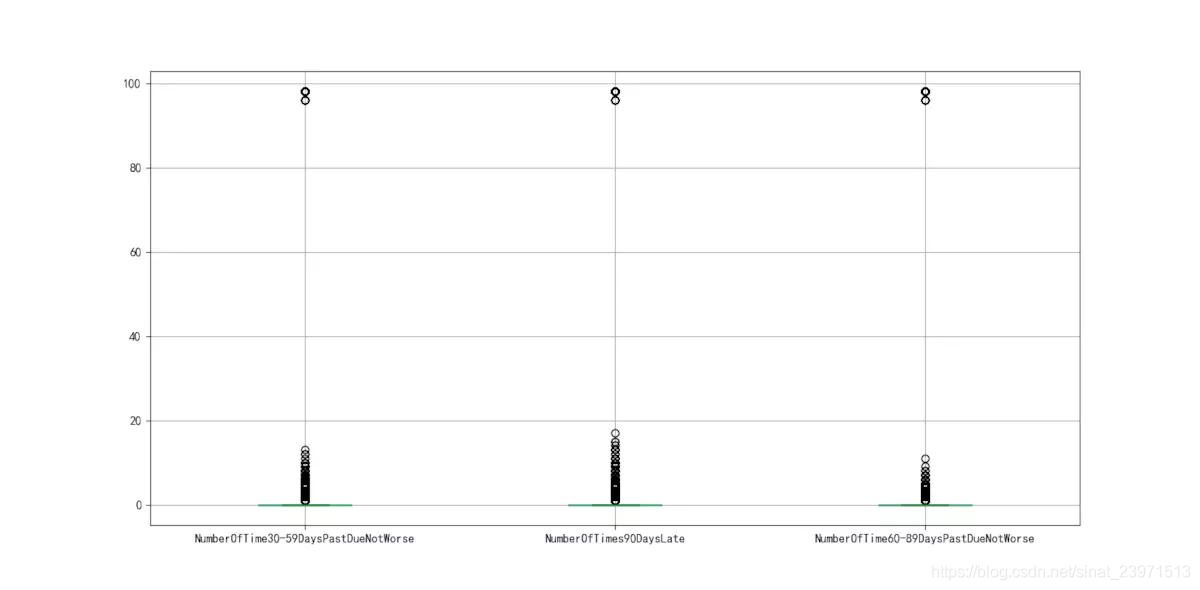
剔除变量NumberOfTime30-59DaysPastDueNotWorse、NumberOfTimes90DaysLate、NumberOfTime60-89DaysPastDueNotWorse的异常值。另外,数据集中好客户为0,违约客户为1,考虑到正常的理解,能正常履约并支付利息的客户为1,所以我们将其取反。
#剔除异常值
data = data[data['NumberOfTime30-59DaysPastDueNotWorse'] < 90]
#变量SeriousDlqin2yrs取反
data['SeriousDlqin2yrs']=1-data['SeriousDlqin2yrs']
3.3 数据切分
为了验证模型的拟合效果,我们需要对数据集进行切分,分成训练集和测试集。
from sklearn.cross_validation import train_test_split
Y = data['SeriousDlqin2yrs']
X = data.ix[:, 1:]
#测试集占比30%
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
# print(Y_train)
train = pd.concat([Y_train, X_train], axis=1)
test = pd.concat([Y_test, X_test], axis=1)
clasTest = test.groupby('SeriousDlqin2yrs')['SeriousDlqin2yrs'].count()
train.to_csv('TrainData.csv',index=False)
test.to_csv('TestData.csv',index=False)
