信用评分卡数据建模
信用评分卡模型简介
按业务使用阶段:
- A卡贷前审核使用申请评分卡模型(Application Score) 主要用于协助信用审核人员将重心放在界于评分边缘的进件上.
- B卡贷中监控使用行为评分卡(Behavior Score)属于动态行为风险的预测,相对复杂,模型种类也多.
- C卡贷后催收评分模型(Collection Score) 多用在案件前期的催收.
以上三类信用评分卡主要应用于预测贷款人的还款概率.
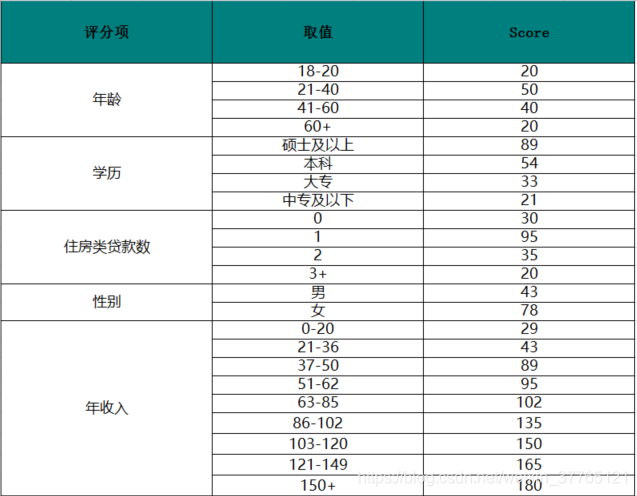
其中表(1-1)为常规的A卡(申请评分卡)样例, 左边字段为评分卡的评分项,通常说的变量, 中间为评分项分布区间, 右边为当前评分项落在对应区间的得分.
表(1-1)
变量筛选
先从单变量评分计算过程开始.首先要计算WOE与IV,假如有历史存量客户数据近6个月提取10万笔作为建模样本,并抽取5000笔进行数据分组,以年收入为分析因子,5000笔数据尽量满足以下条件
附欧洲持卡人于2013年9月通过信用卡进行的交易的原始数据15万笔下载:https://download.csdn.net/download/weixin_37765121/10780612
- 分组数据占比率不低于5%
- 好坏比例在区间 3:1-5:1
- 组间差异大,组内差异小
好(Good)坏(Bad)界线划分业务场景而定,通常会以M3之前结清的标为Good,M3之后标为Bad.实际应用中Bad数量达不到比例范围时,也有对应的拒绝推论处理方式来解决样本数.样本数据准备好后,可以选择某个变量进行分组,并计算各组好坏占比.实际应用是样本数据可能存在异常值与缺失值的问题,常规分两种处理方式 - 1:删除含有缺失值的个案
- 2:可能值插补缺失值
为了建模的有效性,选择可能值插补缺失值比较常见,毕竟现在这类数据处理工具比较多,如可采用Python 编写随机森林对缺失值预测填充函数,对于缺失值处理方式还是专门的课题.实际应用中缺失值填充方法依据情况进行多论探讨,并对填充值的有效性进行不断验证.
附上缺失值预测填充脚本
# 用随机森林对缺失值预测填充函数
def set_missing(df):
# 把已有的数值型特征取出来
process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]]
# 分成已知该特征和未知该特征两部分
known = process_df[process_df.MonthlyIncome.notnull()].as_matrix()
unknown = process_df[process_df.MonthlyIncome.isnull()].as_matrix()
# X为特征属性值
X = known[:, 1:]
# y为结果标签值
y = known[:, 0]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
# 用得到的模型进行未知特征值预测
predicted = rfr.predict(unknown[:, 1:]).round(0)
print(predicted)
# 用得到的预测结果填补原缺失数据
df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome'] = predicted
return df
继续正题,如表(1-2) 5000样本中数据中已经对年收入变量进行分组并计算出对应的WOE(证据权重)值和IV值,其中WOE 计算逻辑为正常件占比除以违约件占比的自然数对数.
表(1-2)
如果违约件数高于正常件时 WOE 值为负数, 绝对值也越大,代表当前分组中的Good与Bad客户区隔程度越高,分组的合理性这个时候应看各组间WOE值差距是否拉开,并呈现由小到大的趋势如表(1-2)基础符合以由小到大.那就可以进行下一步骤的计算IV值.IV值的分布情况决定变量预测能力,IV值计算逻辑是正常件占比减违约件占比乘以证据权重值,各组的IV汇总后得到当前变理的IV值为0.309.

WOE 和 IV计算公式如下:
N表示正常进件占比,P为违约进件占比,n为数据分组数.

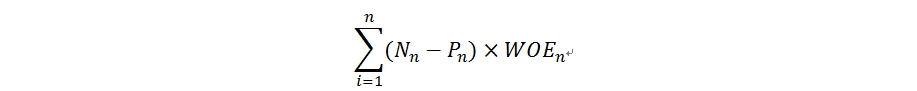
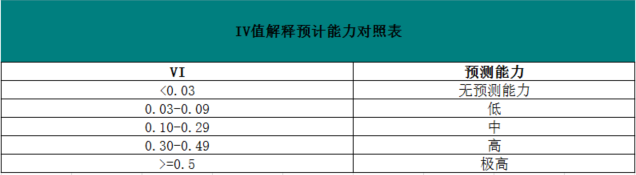
以本例来看IV 值在0.30与0.49区间,说明年收入的预测能力相对强.通常为了提高IV值还需要对分组进行合并,对WOE值相近的组进行合并,重新计算IV值,也可使用顺向进入法,反向排除法和逐步回归法等等,目的是为了能选择出最佳的组别.组别在这步骤确定后,对最终的评分卡对应的变量的评分区间划分就在数据箱确定好了.实际应用类似职业类别,性别,学历已经是天然的组了,不需要作复杂的组别划分计算.
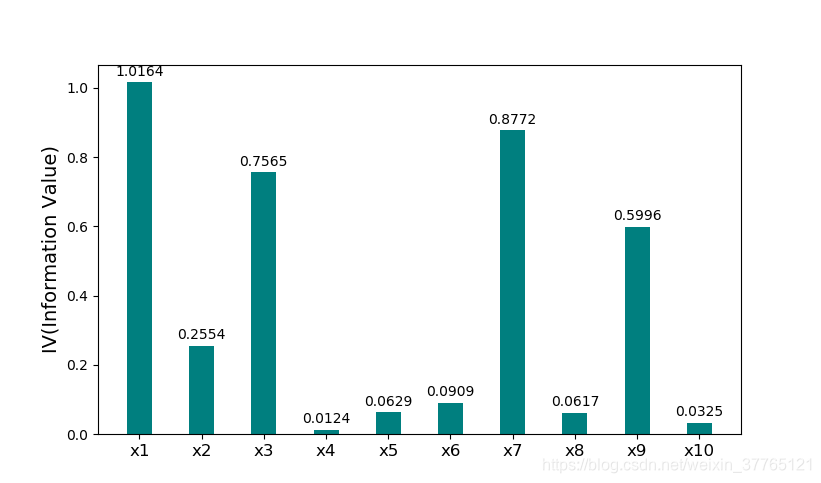
实际应用中如果用Excel计算IV过程比较费力,一般都需要借助工具,比如Python 脚本简单实现所选变量IV计算如图(2-1).
#自定义分箱函数
def self_bin(Y,X,cat):
good=Y.sum()
bad=Y.count()-good
d1=pd.DataFrame({'X':X,'Y':Y,'Bucket':pd.cut(X,cat)})
d2=d1.groupby('Bucket', as_index = True)
d3 = pd.DataFrame(d2.X.min(), columns=['min'])
d3['min'] = d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe'] = np.log((d3['rate'] / (1 - d3['rate'])) / (good / bad))
d3['goodattribute'] = d3['sum'] / good
d3['badattribute'] = (d3['total'] - d3['sum']) / bad
iv = ((d3['goodattribute'] - d3['badattribute']) * d3['woe']).sum()
#d4 = (d3.sort_index(by='min'))
d4 = (d3.sort_values(by='min'))
print("=" * 60)
print(d4)
woe = list(d4['woe'].round(3))
return d4, iv,woe
可能参考表(1-3)IV值解释能力表对照表,
表(1-3)
计算单项评分值
从统计学角度看理论上最佳的信用评分卡是可以完全区分好坏客户,但实际应用坏客户占比通常偏底,难以凸显风险因子的特征.在抽取样本时会刻意拉高到坏客户占比,好坏比率约为3:1-5:1.开发样本与测试样本一般三七开,70%用于模型建立,30%用于模型形成后验证. 接下来通过逻辑回归计算各变量的回归系数并转换为最终的评分值.
公式为: Score = ln(Odds)xScale+Location
(其中Odds 为好坏比)
- (1) 设定Odds = 1:1 时的分数为600分
- (2) 设定Odds 每增加1倍时相对增加20分
- (3) 最终转换分数公式为 Score = ln(Odds)x(20/ln(2))+600
当然实际应用不会这么简单会复杂很多,先不提需专业统计学技术,就拿获取数据这项来聊,尤其近几年的兴起的p2p 小贷公司,产品迭代快,数据少,还缺失.又如刷数据,打混了数据生命周期,被混在数据样本中难以识别.
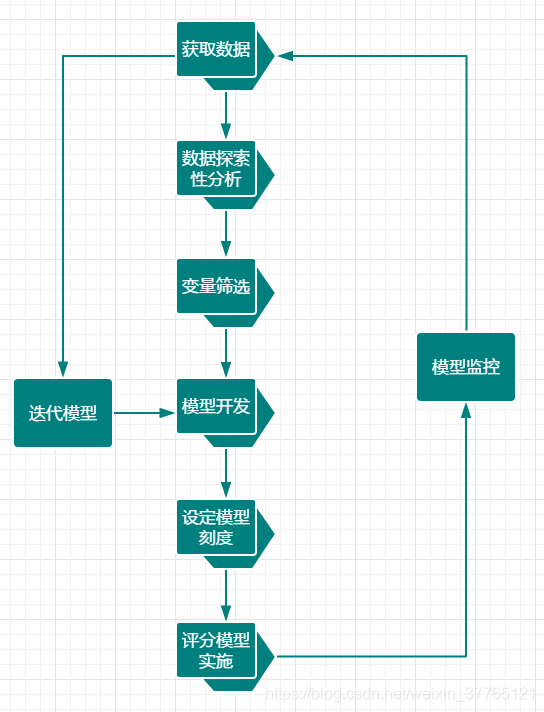
总体来讲商业数据信用建模是会立为一个项目来开展评分模型的建立,其阶段复杂,干系部门比较多,需各部门提供支援,基本会如图(2-2)的过程.
图(2-2)