信用评分问题中一般使用逻辑回归作为主要的模型。过程主要包括变量分箱、变量的WOE(证据权重)变换和变量选择(IV值)、逻辑回归估算。
一个完整的评分卡流程主要包括以下几个步骤:
- 数据准备
- 数据探索性分析
- 数据预处理,包括缺失值、异常值、数据切分
- 特征分箱:
- 特征筛选:IV值
- 单变量分析(IV)和多变量分析(两两相关性)
- 模型训练
- 评分卡构建
- 评分预测
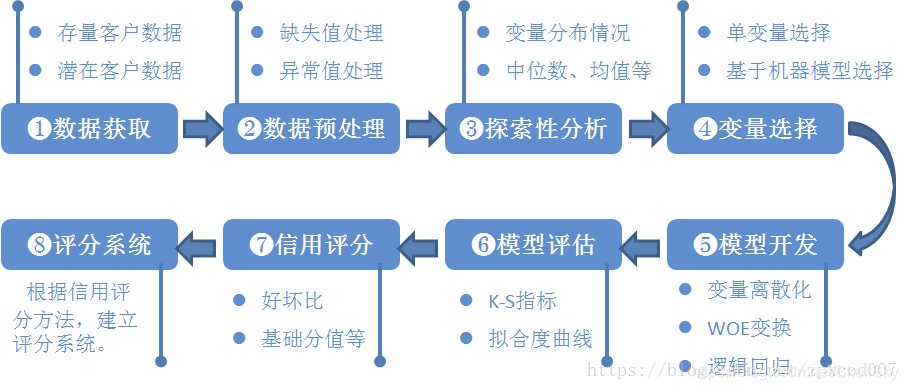
1. 数据准备
数据源主要包含行内行外两部分:行内的有客户的基础人口统计特征数据、交易历史数据、信用历史数据等;
外部数据有人行征信数据、第三方征信机构数据及社交行为数据等。
2. 数据探索
- 对获得的原始数据进行进一步的探索,观察样本的总体分布情况,正负样本是否均衡?
- 单变量分布是否满足正态分布? 变量的缺失情况? 是否有异常值?
- 变量间的共线性情况如何?评分卡模型主要是使用逻辑回归算法进行建模,要求变量间共线性尽可能低。可以采用热力图观察变量间共线性、变量规模。
- 确定数据集分割方法,划分训练集和测试集? --确定坏用户的标准?比如:逾期多久算违约
3. 数据预处理
一般包括缺失值处理,异常值处理,特征共线性
4. 评分卡最优分箱
评分卡最优分箱的具体操作参见上篇博文。分箱结束后,需要对分箱后的变量进行WOE编码。计算公式如下:
W O E i = l n ( b i b / g i g ) WOE_i = ln(\frac{b_i}{b}/\frac{g_i}{g}) WOEi=ln(bbi/ggi)
表示“当前分组中坏客户占所有坏客户的比例”和“当前分组中好客户占所有好客户的比例”的差异。WOE也可以理解为,当前分组中坏客户和好客户的比值,与所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。
WOE越大,这种差异越大,这个分组里的样本是坏客户的可能性就越大;WOE越小,差异越小,这个分组里的样本是坏客户的可能性就越小。
sklearn.reportgen.utils.weightOfEvidence
• WOE 的值越高,代表着该分组中客户是坏客户的风险越低。
5. 特征筛选:IV值计算
IV值是用来衡量某个变量对好坏客户区分能力的一个指标,IV值公式如下:
 I V = ∑ i ( b i b − g i g ) ) ∗ l n ( b i b / g i g ) ) = ∑ i ( b i b − g i g ) ∗ W O E i IV = \sum_i(\frac{b_i}{b}-\frac{g_i}{g}))*ln(\frac{b_i}{b}/\frac{g_i}{g})) = \sum_i(\frac{b_i}{b}-\frac{g_i}{g})*WOE_i IV=i∑(bbi−ggi))∗ln(bbi/ggi))=i∑(bbi−ggi)∗WOEi
关于更详细的WOE和IV可见:数据挖掘模型中的IV和WOE详解。
总体来说,IV的特点如下:
a、对于变量的一个分组,这个分组的好用户和坏用户的比例与样本整体响应和未响应的比例相差越大,IV值越大,否则,IV值越小;
b、极端情况下,当前分组的好用户和坏用户的比例和样本整体的好用户和坏用户的比例相等时,IV值为0;
c、IV值的取值范围是[0,+∞),且当当前分组中只包含好用户或者坏用户时,IV = +∞。
使用IV值有一个缺点,就是不能自动处理变量的分组中出现坏样本比例为0或100%的情况。那么,这种情况下,应该怎么做呢?建议如下:
(1)如果可能,直接把这个分组做成一个规则,作为模型的前置条件或补充条件;
(2)重新对变量进行离散化或分组,使每个分组的坏样本比例都不为0且不为100%,尤其是当一个分组个体数很小时(比如小于100个),强烈建议这样做,因为本身把一个分组个体数弄得很小就不是太合理。
(3)如果上面两种方法都无法使用,建议人工把该分组的坏样本数和好样本数量进行一定的调整。如果坏样本数原本为0,可以人工调整为1;如果好样本数原本为0,可以人工调整为1.
IV值判断变量预测能力的标准(一般选取大于0.02的)
| IV值 | 预测能力 |
|---|---|
| < 0.02 | unpredictive |
| 0.02 to 0.1 | weak |
| 0.1 to 0.3 | medium |
| 0.3 to 0.5 | strong |
| >0.5 | suspicious |
6. 单变量分析和多变量分析,均基于WOE编码后的值
- 选择IV高于0.02的变量
- 比较两两线性相关性,如果相关系数的绝对值高于阈值,剔除IV较低的一个
- 亦可使用机器学习的特征选择方法(RF、Xgboost)
7. 训练模型
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式,详情参见信用评分模型详解(上)之 评分卡模型。
引入WOE转换的目的并不是提高模型效果,只是为了剔除一些不该被纳入模型的变量,因为它们要么无法提升模型效果,要么与模型的相关性过高
其实建立标准信用评分卡也可以不采用WOE转换。这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
模型训练时,
-
要求:
(1)变量显著
(2)系数为负 -
每次迭代中,剔除最不显著的变量,直到
(1) 剩余所有变量均显著
(2) 没有特征可选 -
亦可尝试L1或L2约束
8. 模型评估
可以利用KS和AUC等评估指标(亦可使用混淆矩阵)
- KS值越大,表示模型能够将正、负客户区分开的程度越大。
- 通常来讲,KS>0.2即表示模型有较好的预测准确性。
- KS绘制方式与ROC曲线略有相同,都要计算TPR和FPR。但是TPR和FPR都要做纵轴,横轴为把样本分成多少份。
步骤:
(1)按照分类模型返回的概率降序排列
(2)把0-1之间等分N份,等分点为阈值,计算TPR、FPR
(3)对TPR、FPR描点画图即可
KS值即为Max(TPR-FPR)
9. 评分卡建卡
在建立标准评分卡之前,还需要设定几个评分卡参数:基础分值、 PDO(比率翻倍的分值)和好坏比。详情参见信用评分模型详解(上)之 评分卡模型。
这里, 我们取600分为基础分值b,取20为PDO (每高20分好坏比翻一倍),好坏比O取20。

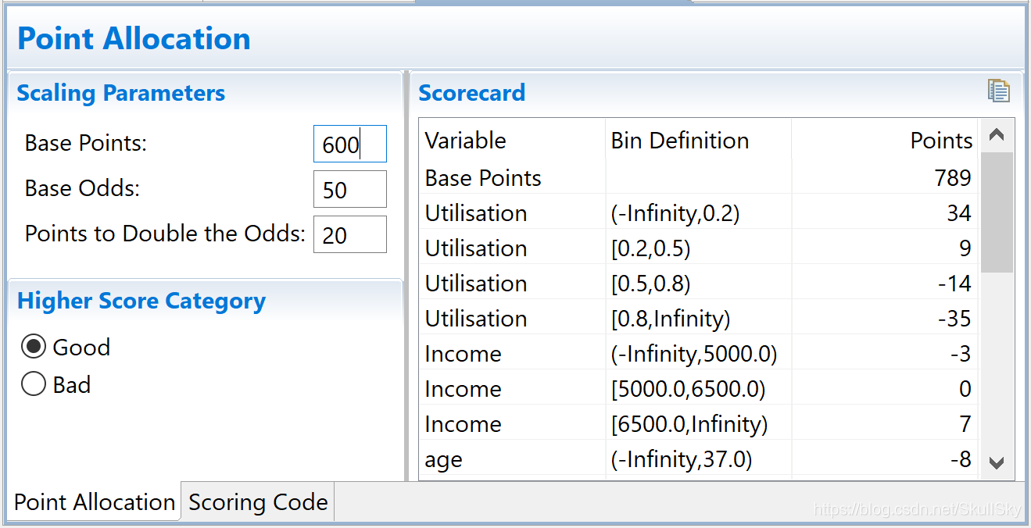
10. 评分预测
对测试集进行预测和转化为信用评分。可直接采用如下公式计算分值:
S c o r e = A ± B ∗ l o g ( O d d s ) Score = A \pm B*log(Odds) Score=A±B∗log(Odds)