基于深度图手势识别Pose-REN讲解

原文:Pose Guided Structured Region Ensemble Network for Cascaded Hand Pose
Estimation
收录:2017
Abstract
基于单深度图的姿态估计是计算机视觉和人机交互中的一个重要课题。尽管近年来卷积神经网络使得这一领域有了很大的发展,但准确的手部姿态估计仍然是一个具有挑战性的问题。本文提出Pose- REN网络来提高手部姿态估计的性能。提出的这个方法 在初始姿态估计的指导下,从卷积神经网络的特征图中提取区域,来生成更优、更有代表性的手部姿态估计特征,然后 根据手部关节的拓扑结构,利用树状的全连接对提取的特征区域进行层次集成,该网络直接回归手姿态的精确估计,并利用 迭代级联方法 得到最终的手姿态。
※论文核心思想:
- 提出了一种新的特征提取方法;
- 提出了一种基于手的拓扑结构来融合不同关节特征的分层方法。
1. Introduction
准确的三维手姿态估计是人机交互和虚拟现实中最重要的技术之一,因为它可以提供与对象交互和执行动作的基本信息。多亏深度相机的出现,例如Microsoft Kinect、Intel Realsense Camera等,使得单深度的姿态估计近年来引起了广泛的研究兴趣,然而,由于存在 严重的自遮挡、手部关节高度复杂、深度图像质量低、视点变化大、手指自相似 等问题,手部姿态估计是一个极具挑战性的问题。
(手部姿态估计难在哪些地方?为何是一个挑战任务?)
利用CNN进行手部姿态估计,取得了很大的进步。之前基于CNN的方法要么预测每一个关节的概率图 (热图 heatmaps),并从热图中估计手的姿态,要么使用反馈回路和空间注意机制等复杂的设计,然而,这些表现远远不能令人满意。最近,Guo等人提出了一种区域集成网络(REN),该网络(基于单一网络,直接回归手部关节的三维位置)极大地提高了手部姿态估计的性能。
(之前基于CNN方法:①通过热图来估计手势;②使用反馈回路等复杂设计。但是这些方法的表现不如REN)
REN将最后卷积层的特征图分成几个空间块,并被之后的FC整合到一块,然而,REN使用统一的网格来提取特征区域,对所有的特征都进行同等的处理,这并不能充分获得特征图的空间信息以及具有高度代表性的特征。
( ①REN不足之处;②讲述REN网络大致流程 )
在迭代求精的过程中,REN则是以先前估计的位姿作为输入,并在每次迭代中预测更准确的结果。
- 在先前预测的手部姿态的指导下 ,提出了一种新的特征提取方法,得到最优的和有代表性的手姿态估计特征。
- 受到递归神经网络的启发 ,又提出了一种基于手的拓扑结构来融合不同关节特征的分层方法。 来自同一手指关节的特征被整合在第一层,来自所有手指的特征被融合在后面的层来预测最终的手部姿势。
在第2节里,回顾了与REN高度相关的先前的工作。在第3节中,详细介绍了REN网络。第4节提供了对公共数据集和消融研究的评价。第五部分是本文的简要结论。
2. Related Work
回顾相关工作:
- 最近的基于深度的手部姿态估计算法;
- 由于REN基本上是建立在级联的框架上,因此介绍用于手姿态估计的级联方法;
- 由于用到层次结构连接,因此回顾关于神经网络层次结构的相关工作。
2.1. Depth-based Hand Pose Estimation
① Generative methods(生成方法) 对自封闭区域或缺失区域具有较强的鲁棒性,并能保证输出合理的手部姿态,然而,会需要一个复杂和耗时的优化过程,并且很可能陷入局部操作时间的陷阱。
② Discriminative methods(判别方法) 直接从标记的训练数据中学习到预测器。预测器可以预测每个手关节的概率图(heatmap),也可以直接预测手关节的三维坐标,因此不需要任何复杂的手工模型,完全是数据驱动的,速度快,适用于实时应用。
③ Hybrid methods(混合方法) 结合判别法和生成法来获得更好的手部姿态估计性能,some work在通过判别法获得初始手部模型后,再采用生成法,但是混合方法仍然需要预先定义手部模型的属性,比如骨骼的长度。
REN基本上属于判别法的范畴,不依赖于任何预定义的手模型,直接使用一个级联的框架来预判手部位姿的三维位置,而不需要任何后处理过程。
2.2. Cascaded Method
同类的网络需要训练多个模型进行细化,并独立预测手关节的不同部位,而REN只需迭代一个模型来改进手姿态的估计。Oberweger等人提出了一种用于手部姿态估计的反馈环框架,判别方法用来生成一个初始手部模型,然后使用广义CNN从初始手姿态生成深度图像,然后使用更新网络通过比较合成深度图像和输入深度图像改进手姿态。
2.3. Hierarchical Structure of Neural Network
- Du等人提出了一种多层次的循环神经网络(RNN)来实现基于骨骼的人体动作识别,整个骨架被分成五部分,并被送入RNN的不同分支,骨架的不同部分按层次结构融合,生成更高层次的表示。
- Madadi等人[40]提出了一种树状CNN结构,该结构在不同的分支上回归局部位姿,并在最后一层融合所有的特征。
上述方法则是不同部分位姿的特征是独立学习的,而REN 在所有关节的卷积层中共享特征,并从特征图中分层融合不同的区域来获得最终手部姿态估计。
3. REN

- A simple CNN (用 Init-CNN 来表示) 预测一个初始的手部姿态 pose0(用来作为级联结构的初始化);
- 所提出的框架结构以先前估计的手姿态 poset-1 和 深度图 作为输入,深度图送进CNN中来生成特征图,根据输入的手势 poset-1 ,来从特征图中提取特征区域;
- 利用结构连接对不同关节的特征进行层次集成,回归细化后的手部位姿 poset 。
具体:给定一个深度图 D ,以及3D坐标集合
(总共J个关节点),通过使用习得的回归模型 R 来改进 t 阶段的手部姿势:

3.1. Pose Guided Region Extraction
- 步骤一:用CNN生成特征图;
使用CNN并且利用残差连接生成特征图(CNN 由6层卷积和2个残差连接组成,每个卷积层后面都有ReLU激活函数,每两个卷积层后面跟着最大池化层);
- 步骤二:将真实坐标转换到像素坐标;
用 F 来表示最后一个卷积层的feature map,前一阶段手部姿态估计的3D坐标为 ,将 Pt-1 作为 F 的指导来提取特征区域。特别注意的是:首先得使用深度相机的固有参数将真实世界的坐标投影到图像像素坐标中,如下式所示:
- 步骤三:在前阶段手部姿态指导下,用矩形来提取特征图;
使用一个矩形窗口裁剪这个关节的特征区域,矩形窗口 中的 是左上角坐标,通过下式得到:
而式子中的 αw、αh:
式中的 wF、hF、wD、hD 分别是特征图 F、深度图 D 的宽和高。
- 总结上述步骤用一个函数 crop() 来表示对第i个关节点裁剪:
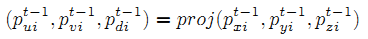
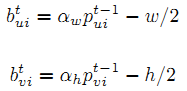
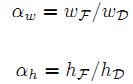
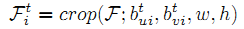

最左边图像则是最后卷积层输出的特征图,由于通道数很多,这里只选择一个channel来描述如何根据关节点指导来切割特征图;其中绿点和红点表示先前估计的手部姿势的两个关节点(掌心关节和中指的掌指关节)。
3.2. Structured Region Ensemble

上述步骤则是得到切割后的特征区域,融合这些特征区域的一种直观的方法是将每个区域分别与 FC 连接,然后将这些层融合,从而回归到REN所采用的最终手势。即先将来自同一手指关节(包括手掌关节)的特征融合。然后再去融合不同手指的特征,回归最后的手部姿势。
假设 为切割后的特征区域集合,M 是特征区域总数,通过 FC 后则是:
上面说的 j 和 M 分别是索引、特征区域总数,但想用别的符号来表示,针对单个手指来制定,第 i 根手指特征区域集合 , Mi 则是第 i 根手指总关节数。这样是为了便于将同一手指特征融合,用 concate 实现融合,fc 全连接(2048维,后面跟着ReLU和dropout,rate=0.5):
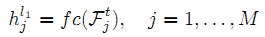
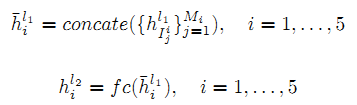

3.3. Training
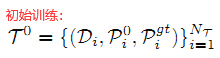
上式中:NT 是训练样本数,Di 是深度图,
是初始手部姿态,
是相应手部姿态GT (ground truth)。
在 t 阶段时,利用 t-1 阶段的训练集 Tt-1 来训练回归模型 Rt,可以得到训练集中每个样本的细化手姿态:
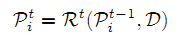
再把细化样本
添加到训练集中得到增强训练集 Tt:
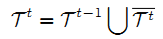
下一轮获得回归模型 Rt+1,直到获得回归模型 RT。
- 采用随机梯度下降法(SGD),批量大小为128,动量为0.9;
- 采用0.0005的权重衰减;
- 学习速率设置为0.001,每隔25个epoch除以10;
- 每个阶段对模型进行100个epoch的训练。
