这是吴恩达老师深度学习工程师(网上有资源,大家可以去看看吴老师的课程,还是很有收获。),第二次课第三周的课后实例作业,可以作为初学者练手的好项目。原项目是tensorflow写的,我又用pytorch写了一遍。数据文件和完整代码都传到github上了。详情见:https://github.com/idotc/Gesture-digit-recognition
一、Problem statement: SIGNS Dataset
设计一个神经网络用来识别如下图片手势中的数字。

- Training set: 1080 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (180 pictures per number).
- Test set: 120 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (20 pictures per number).
二、实现过程
整个过程分为:数据读取与处理,神经网络的设计,训练,评测
- 数据读取与处理,这个主要是处理,训练图片需要转化成一维向量,还要把整个训练集shuffle成一个个mini_batch。对于label,需要转化成one_hot向量。
- 神经网络的设计,网络的设计影响到最后的结果,这个跟经验有很大的关系,需要多看论文,多实践。
- 训练,选择一个好的optimizer 优化器往往能事半功倍
- 评测,把训练和验证的结果loss,acc.等打印出来,及时调整策略。
三、学习过程和坑
1、np.random.seed(seed)
每次运行代码时设置相同的seed,则每次生成的随机数也相同,如果不设置seed,则每次生成的随机数都会不一样。
2、np.random.permutation(m)和np.random.shuffle(m)的区别
假设m是一个数,permutation函数都是生成一个0到m-1的乱序数组,并返回该数组。若m是一个数组,区别是shuffle是直接改变传入m的顺序,无返回值;permutation是不改变传入m的顺序,返回一个新的打乱顺序的数组。
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
3、math.floor(m)
返回一个小于或等于m的最大整数,用于mini_batch划分数组中,得到的结果不是整数时,向下取整使用。
batches = math.floor(m/mini_batch_size)
4、a = (c, d)
a为python里的元组,若为普通的一个元素时,不可以修改,为list对象时候,可以修改其中的值。
mini_batch = (mini_batch_X, mini_batch_Y)
5、one_hot函数
Y = np.eye(C)[Y.reshape(-1)].T
np.eye(C),生成一个列数为C的单位矩阵,np.eye(C)[m],在m处为1的一维向量,即转化成one_hot向量。
6、损失函数
pytorch里面提供了一个实现 torch.nn.CrossEntropyLoss(This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class),其整合了上面的步骤。这和tensorflow中的tf.nn.softmax_cross_entropy_with_logits函数的功能是一致的。必须明确一点:在pytorch中若模型使用CrossEntropyLoss这个loss函数,则不应该在最后一层再使用softmax进行激活。
`
7、torch.max(input, dim, keepdim=False, out=None)
这个用作最后的评测。torch.max)(a,0) 返回每一列中最大值的那个元素,且返回索引(返回最大元素在这一列的行索引);torch.max(a,1) 返回每一行中最大值的那个元素,且返回其索引(返回最大元素在这一行的列索引)。troch.max()[1], 只返回最大值的每个索引。torch.max()[1].data 只返回variable中的数据部分。torch.max(test_output, 1)[1].data.squeeze()序列化后用作比较结果。
BUGS:
1、RuntimeError: Variable data has to be a tensor, but got numpy.ndarray
需要将numpy矩阵转换为Tensor张量:
tensor_data = torch.from_numpy(numpy_data) #numpy_data为numpy类型
将Tensor张量转化为numpy矩阵
numpy_data = tensor_data.numpy() #tensor_data为tensor张量
2、Pytorch出现 raise NotImplementedError
网络没定义正确:def forword(self, x):
->def forward(self, x):
3、Expected object of type torch.LongTensor but found type torch.FloatTensor pytorch
在使用CrossEntropyLoss时,常会出现如题的错误。错误指出,要用longtensor而不是floattensor,于是
per_label = per_label.long()
outputs = outputs.long()
将神经网络输出和目标label都转换为longtensor,发现又会出现新问题。
如果是这种情况,我们应该检查输入的标签是0,1格式的,还是0-(C-1)这种格式的,CrossEntropyLoss只适用于0-(c-1)这种格式,如果标签设置为(0,1)格式,请用MultiLabelSoftMarginLoss,即
criterion = nn.MultiLabelSoftMarginLoss()
发现问题解决。(这个大兄弟解决的:https://blog.csdn.net/u012759006/article/details/82559334)
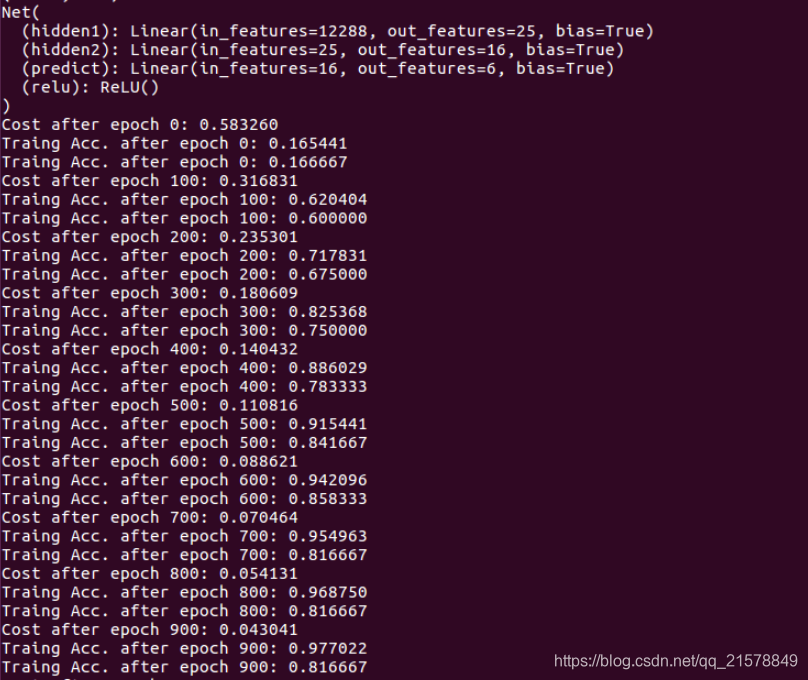
最后附上一张训练图: