计算机组成原理学习笔记——数的转换和数的存储
其他
2020-04-01 12:45:12
阅读次数: 0
一、数的转换
- 以 C/C++ 为程序设计语言,探究有符号数与无符号数之间的转换有什么影响?有符号数的不同数据类型、不同字长的转换又有什么影响?
1、无符号转有符号
- 将一个数从无符号数强制转换成有符号数,结果会如何?
- 先看个程序段:
int main()
{
short x = -4321;
unsigned short y = (unsigned short)x;
printf("x=%d, y=%u\n", x, y);
return 0;
}
- 其运行结果:
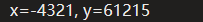
- 这是为什么呢?原因很简单,有符号数转无符号数时,计算机会把原来用于表示符号的那位也当成数值位进行计算,如下:

- X 采用补码表现形式。可以看出强制类型转换只是简单地在保持位值不变的同时改变解释的方式。所以从有符号转为无符号,通常无符号的值会比有符号数的绝对值大很多。那么反过来呢?有无符号转有符号呢?
unsigned short x = 65535;
short y = (short)x;
printf("x=%u, y=%d\n", x, y);
- 结果是:65535 和 -1,
- short 数据类型占两个字节,也就是 16 位,所以无符号数最大的数就是 65535,也就是最高位的值为 1,其余位都是 0.
- 而变成有符号数时,最高位要做为符号位,符号位为 1 表示负数,而其他位为 0,所以结果便是 -1.如果让最高位不为 1,而是为 0,也就是无符号数取小于 等于 32767 的数,例如 32765,输出结果一样。
- 考虑到有符号数的 short 型数据的表示范围:-32768~32767 便清楚了,只要无符号数值为整数时小于 32767 那么结果便一样,而负数取 32768 到 65535 就是 -32768 到-1;然后就是 0 无论有没有符号都一样。
2、不同字长之间的转换
- 同样以相关程序入手:
int x = 165537, u = -34991;
short y = (short)x, v = (short)u;
printf("x=%d, y=%d\n", x, y);
printf("u=%d, v=%d\n", u, v);
- 运行结果是
x=165537, y=-31071 u=-34991, v=30545.
- 先把各个变量的值以十六进制表示:
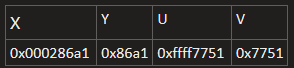
- 可以很直观的看到,当大字长向小字长转换时,系统会直接按短字长的位数将高字长的多余的位直接截断,显然这是一种保持位值的做法。如果是相反情况呢?也就是从小字长转换为大字长,情况如何呢?
short x = -4321;
int y = x;
unsigned short u = (unsigned short)x;
unsigned int v = u;
printf("x=%d, y=%d\n", x, y);
printf("u=%u, v=%u\n", u, v);
- 同样的道理将变量的值以十六进制表示
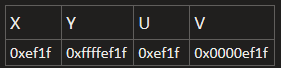
- 从短字长到长字长时,在让相应的低位的值保持相等的同时,高位部分拓展为原数字的符号位,这在之前的符号拓展中说过。字符类型的数据,如 char 转 int 型,直接在高位补零即可。
二、数的存储
- 在存储数据时,数据从高位到低位可以按从左到右排列,也可以按从右到左排列。因此,无法用最左或最右来表征数据的最高位或最低位,通常用最低有效字节(LSB)和最高有效字节(MSB)来分别表示数的低位和高位。
- 例如,32 为计算机中,int 型变量 I 的机器数为 01234567H,则其最低有效字节 LSB=67H,最高有效字节 MSB=01H。
1、“大端方式”和“小端方式”
- 现代计算机基本采用字节编址,即每个地址编号中存放 1 字节。多字节数据存放在连续的字节序列中,根据数据中各字节在连续字节序列中排列顺序的不同,有两种排列方式:大端方式(big endian)和小端方式(little endian)。
- 大端方式按从最高有效字节到最低有效字节的顺序存储数据,也就是最高有效字节放在前面。
- 小端方式按从最低有效字节到最高有效字节的顺序存储数据,也就是最低有效字节放在前面。
- 看下图:

- 第一个表就是大端模式,第二个表就是小端模式。
2、“边界对齐”方式
- 存储字长 32 位,可按字节、半字和字寻址,数据若以边界对齐方式存放,半字地址是 2 的倍数,字地址是 4 的整数倍,也就是无论所取得数是字节、半字或字,均可以一次访存取出。当所存储得数据不满足上述要求,通过填充空白字节使其符合要求。虽然浪费空间,但是提高取指和取数的速度。
- 当数据不按边界对齐存储,可以充分利用空间,但是半字长或字长的指令可能需要存放在两个存储字中,此时需要两次访存,并且对高低字节的位置进行调整、连接之后才能得到所要的指令或数据,从而影响指令的执行效率。

上一篇
下一篇
发布了184 篇原创文章 ·
获赞 24 ·
访问量 2万+
转载自blog.csdn.net/qq_42896653/article/details/104557633
