文章:recurrent convolutional neural networks for text classification
文章链接:http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552
一、简介
RNN的优点是能够更好地捕捉上下文信息。这可能有利于捕获长文本的语义。然而,RNN是一个有偏倚的模型,在这个模型中,后面的单词比先前的单词更具优势。因此,当它被用于捕获整个文档的语义时,它可能会降低效率,因为关键组件可能出现在文档中的任何地方,而不是最后。为了解决偏置问题,我们引入了卷积神经网络(CNN),将一个不带偏见的模型引入到NLP任务中,它可以很好地确定文本中带有最大池化层的识别性短语。因此,与递归或循环神经网络相比,CNN可以更好地捕捉文本的语义。CNN的时间复杂度也是 。然而,以前对CNN的研究倾向于使用简单的卷积核,如固定窗(bert et al. 2011;Kalchbrenner和Blunsom 2013)。使用这样的内核时,很难确定窗口大小:小窗口大小可能导致一些关键信息的丢失,而大的窗口会导致巨大的参数空间(这可能很难训练)。因此,它提出了一个问题:我们能否比传统的基于窗口的神经网络学习更多的上下文信息,更准确地表示文本的语义。
为了解决上述模型的局限性,提出了一个循环卷积神经网络(RCNN),并将其应用于文本分类的任务。首先,我们应用一个双向的循环结构,与传统的基于窗口的神经网络相比,它可以大大减少噪声,从而最大程度地捕捉上下文信息。此外,该模型在学习文本表示时可以保留更大范围的词序。其次,我们使用了一个可以自动判断哪些特性在文本分类中扮演关键角色的池化层(max-pooling),以捕获文本中的关键组件。我们的模型结合了RNN的结构和最大池化层,利用了循环神经模型和卷积神经模型的优点。此外,我们的模型显示了O(n)的时间复杂度,它与文本长度的长度是线性相关的。
二、模型结构
解释一下为啥叫RCNN:一般的 CNN 网络,都是卷积层 + 池化层。这里是将卷积层换成了双向 RNN,所以结果是,双向 RNN + 池化层。
如下图是作者提出的模型框架,输入是一个文本
,它可以看成是由一系列单词
组成的。输出是一个概率分布,最大的那个位置对应文章属于的类别
。
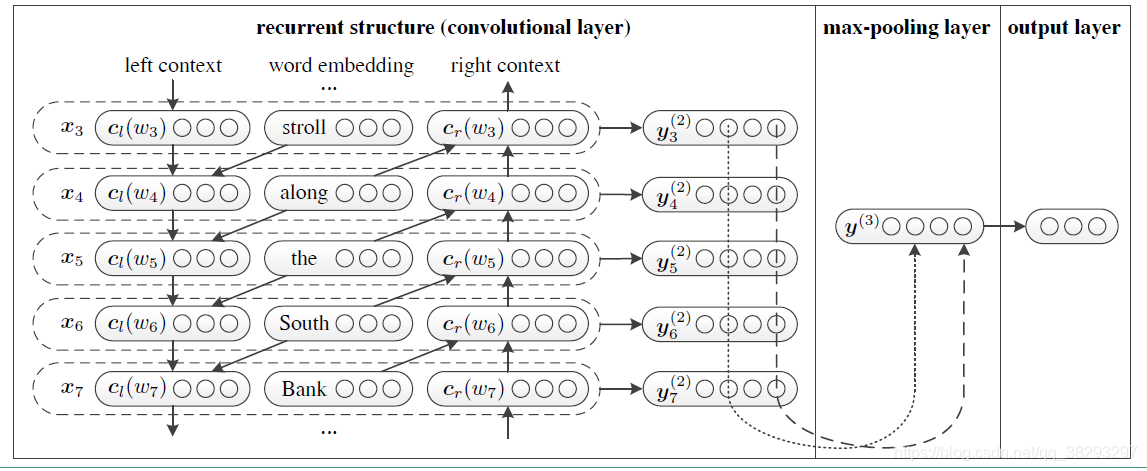
RCNN 整体的模型构建流程如下:
1)利用Bi-LSTM获得上下文的信息,类似于语言模型。
2)将Bi-LSTM获得的隐层输出和词向量拼接[fwOutput, wordEmbedding, bwOutput]。
3)将拼接后的向量非线性映射到低维。
4)向量中的每一个位置的值都取所有时序上的最大值,得到最终的特征向量,该过程类似于max-pool。
5)softmax分类。
RCNN 整体的运算过程为:
(1)根据上图从左向右看,首先将词进行词向量编码,即第一栏中间的 word embedding 层;得到 。
(2)接着将词向量输入到双向的 RNN(这里的 RNN cell 可以使用 lstm 或者 gru 或者最简单的)。得到
和
。
可以理解为使用两个 RNN,一个从左往右扫描,一个从右往左扫描。文中说,这么做的好处是,可以抓到词汇更多的上下文信息。
(3)将(1)和(2)中得出的结果拼接到一起,并输入到 激活函数,得到 。
接下来我们来仔细分析一下框架训练的过程。
1.Word Representation Learning
为了更准确地表达单词的意思,作者使用了单词本身和其上下文来表示这个词。在论文中,使用双向循环结构来实现。使用
来定义词
左边的文本,
来定义词右边文本。这里
和
是长度为
的稠密向量。从框架结构图中左边一块的箭头指向可以发现
和
的计算公式如下:
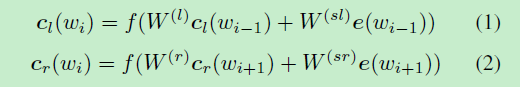
以“A sunset stroll along the South Bank affords an array of stunning vantage points”这句话为例分析,结合上图,
表示了“Bank”这个词左侧的上下文语义信息(即“……stroll along the South ”),同理,
表示了“Bank”这个词右侧的上下文语义信息(即“ affords an array ...”)。据此,我们就可以定义单词
的向量表示:
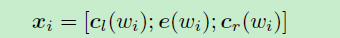
循环结构可以在文本的向前扫描时获取所有的
,在反向扫描时获取所有的
。时间复杂度为
。当我们获得了单词
的表示
后,我们将一个线性变换与
激活函数一起应用到
,并将结果传递到下一层。
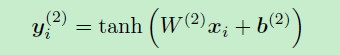
是一个潜在的语义向量,每一个语义因素都将被分析,以确定代表文本的最有用的因素。
2.Text Representation Learning
上面部分是单词的表示,那么怎么来提取文本的特征表示呢?作者在这里使用了CNN,当前面所有的单词表示y都计算出来以后,接上一个max-pooling层。这样可以得到最重要的信息。

这里的max函数是一个按元素max的函数,也就是说,前一步单词表达得到的
是一个n维向量,这一步
的第
个元素是上一步
的所有向量的第
个元素的最大值。
池化层将不同长度的文本转换为固定长度的向量。通过使用池化层,我们可以在整个文本中捕获信息。还有其他类型的池层,比如平均池层(Collobert et al. 2011)。我们这里不使用平均池,因为这里只有几个单词和它们的组合对于捕获文档的含义非常有用。在文档中,最大池化层试图找到最重要的潜在语义因素。
模型的最后一部分是输出层:
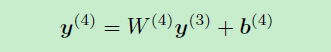
最后对y应用softmax得到概率:
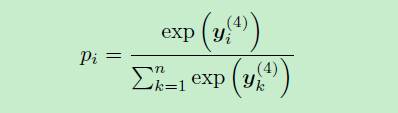
3. 代码实现
详见博客:https://www.cnblogs.com/jiangxinyang/p/10208290.html
