概述
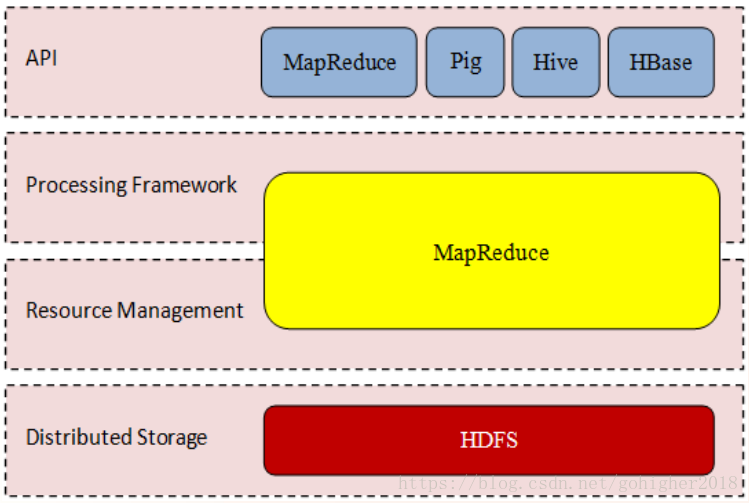
Hadoop的两个核心组成部分:1)分布式文件系统-HDFS;2)分布式数据处理架构-MapReduce。MR功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库。
1)HDFS
HDFS没有改变,仅有删除原有的再加新的,有时间戳。
在一版本中,一个集群中仅有一个NameNode。一个集群中仅有一个SecondaryNameNode定期(checkpoint)保存NameNode数据,即SecondaryNameNode中存储的是上一次checkpoint之后的NameNode。checkpoint node默认在主节点,也可以放到其他节点上,但还是归主节点管理。对于单点NameNode坏了的话,可以通过SecondaryNameNode来恢复上一次checkpoint时候的数据,或者是写NameNode的时候就往第三方上写一份,用于备份恢复。
在二版本中,NameNode节点可以有备NameNode,也可以没有。
2)MapReduce 占用20%-30%磁盘空间
Map:将任务分解为多个子任务执行
Reduce:将这些子任务的处理结果进行汇总
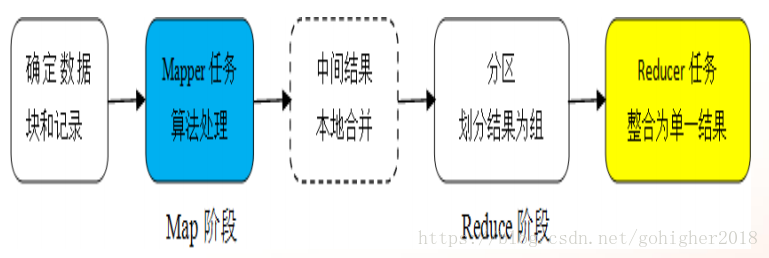
中间结果存储在磁盘中,而spark的中间结果存储在内存中,因此,spark更快
Apache Hadoop&CDH:
Hadoop1对应CDH3
Hadoop2对应CDH4
Hadoop1架构
Hadoop1集群中的节点类型分为,
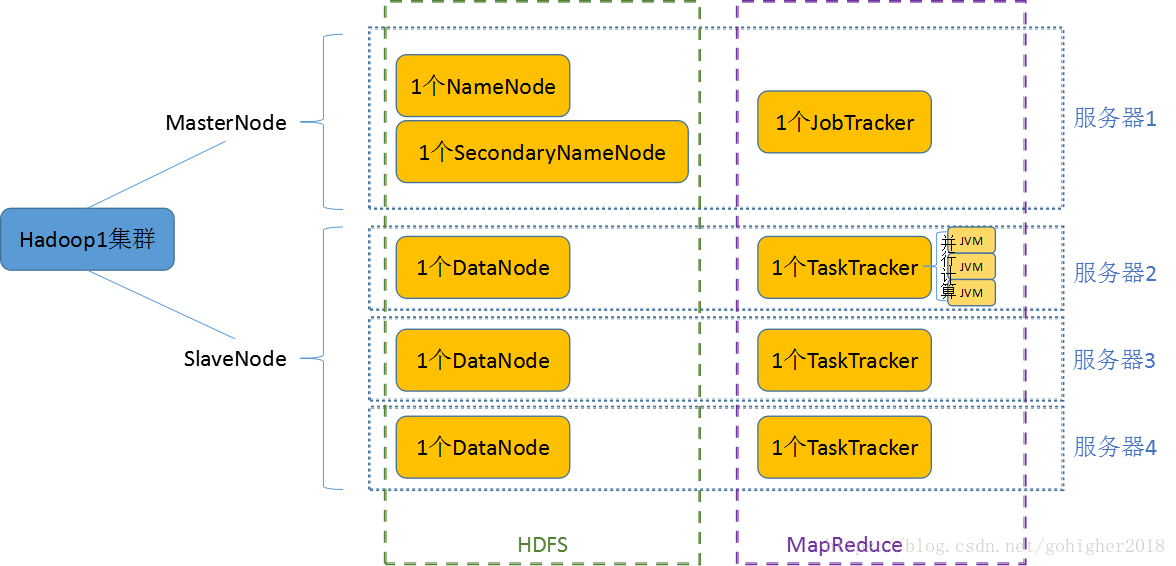
1)HDFS:
NameNode记录元数据(记录文件如何分割成数据块,以及存储数据块的数据节点的信息;对内存和I/O进行集中管理)
DataNode负责将HDFS数据块读写到本地文件系统
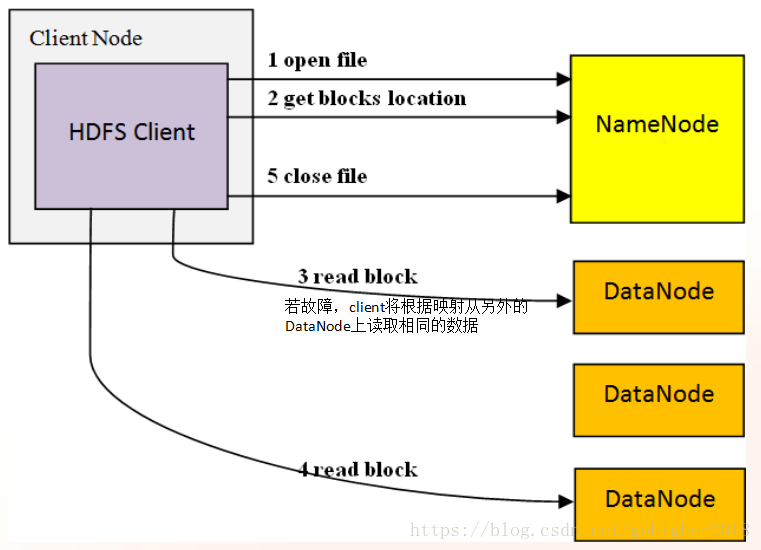
当client端有读写请求时,NameNode会告诉client去哪个DataNode进行操作,client会直接与这个DataNode进行读写访问
2)MR:
JobTracker负责为所执行任务(Map任务和Reduce任务)分配指定的节点主机,监控所允许的任务并进行重启。
TaskTracker需要与JobTracker进行定时心跳,若JobTracker不能准时获取TaskTracker的信息,则认为该TaskTracker节点坏了,JobTracker会将任务重新分配给其他从节点
client端和JobTracker通信,不直接和TaskTracker连接
1、HDFS结构
1.1 NameNode
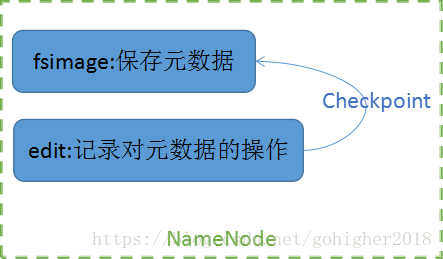
在checkpoint的时候,edit文件内容会合并到fsimage中。在Hadoop1中,SecondaryNameNode负责checkpoint工作。checkpoint的具体过程如下:
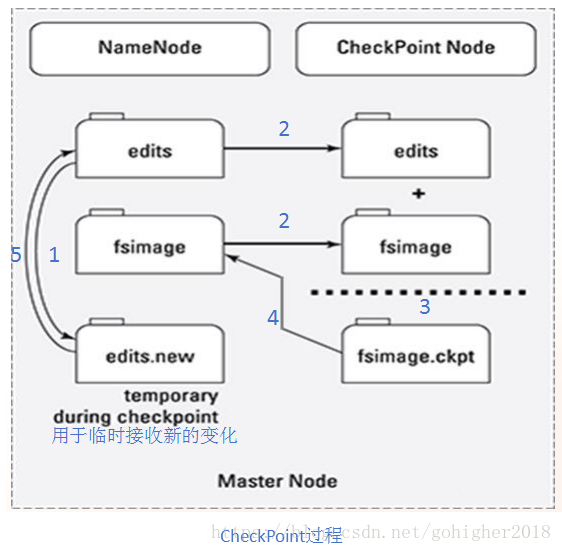
fsimage和edits文件都是经过序列化的,在NameNode启动的时候,它会将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
edits预写入式的日志,并且会接受执行成功或失败的结果。edits只记录对于元数据的改变的操作,读操作不记录。
1.2 DataNode
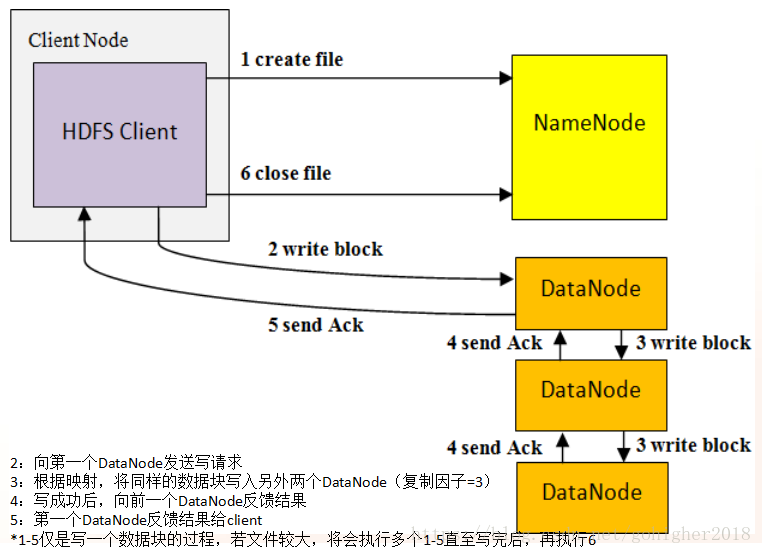
HDFS机制将每个文件分割成一个或多个大小相等的数据块(Block,默认64M),每个Block会存储在一个或多个DataNode上,默认复制因子为3。如果某个节点坏了,NameNode发现数据块的拷贝数低于设定值,会增加数据块;当节点恢复,NameNode发现数据块的拷贝数高于设定值,会删除多余的。
1.3 读HDFS操作
1.4 写HDFS操作
同步写,必须等3、4成功,才算写成功
2、MR结构


对于第4点,HDFS以数据块形式存储数据,不关心数据块的内容。这样如果Map处理的数据记录跨越了两个数据块,如何处理?为此,HDFS引入了Input Split概念,以对数据块中的数据进行逻辑表示。如下:
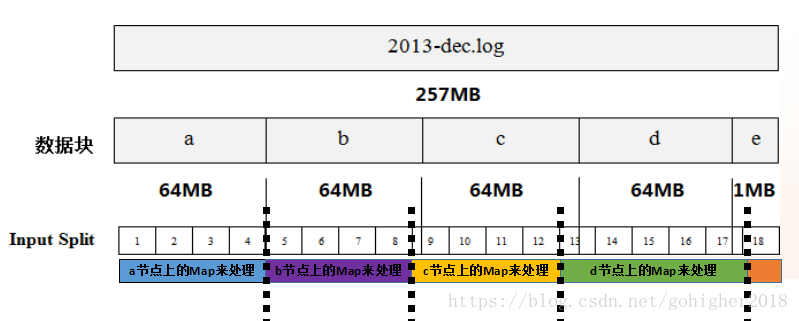
如果数据记录位于一个数据块中,Input Split可表示完整的数据记录集;若数据记录跨两个数据块,Input Split中会包含第二个数据块的位置以及所需完整数据的偏移量。
Reduce是处理Map后的结果,具体在哪个节点(a/b/c/…..)上处理,是由MR分资源确定的,对我是透明的
Hadoop1 环境搭建
两台为例,

| ip | hostname | 角色 | 进程 |
|---|---|---|---|
| 10.221.n.43 | host03 | master | Namenode SecondaryNamenode JobTracker |
| 10.221.n.44 | host04 | slave | Datanode TaskTracker |
安装hadoop,hadoop-1.2.1,解压安装在/opt/app/hadoop。
安装jdk1.7
两台机器配互信
hadoop的配置文件在/opt/app/hadoop/conf中,有,

修改hadoop-env.sh中的export JAVA_HOME=/opt/app/jdk。
修改conf目录中以下配置文件:
core-site.xml:核心配置文件
hdfs-site.xml:HDFS配置文件
mapred-site.xml:MapReduce配置文件
配置Hadoop — core-site.xml
vi conf/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop1/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://host03:8020</value> 也就是listen的端口,用于slave节点、client来连接
</property>
</configuration>其中使用了一个不存在的目录,可以使用mkdir命令事先创建该目录。
配置Hadoop — hdfs-site.xml
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value> 复制因子,需要小于实际slave节点数
</property>
</configuration>配置Hadoop — mapred-site.xml
vi conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>host03:8021</value> 也就是listen的端口,用于slave节点、client来连接
</property>
</configuration>vi masters
host03vi slaves
host04启动,
在master节点上,HDFS使用前,需要执行格式化NameNode(仅第一次的时候需要),hadoop namenode -format。格式化的目的是在NameNode上创建初始的原数据,创建空的fsimage和edits文件,并为DataNode随机产生storgeID。当DataNode第一次连接NameNode时会接受这个storageID,之后他会拒绝与其他NameNode连接。如需重新格式化NameNode,必须将DataNode的数据和StorageID全部删除。或者是可以尝试将之前的name目录下所有文件cp到新的name目录下。接下来看图,也是关于格式化NameNode的,

启动,start-all.sh
之后使用jps查看进程,
master上,
slave上,
Hadoop1 配置文件
1、主要配置文件
core-site.xml、hdfs-site.xml、mapred-site.xml。它们中定义的参数会覆盖hadoop jar中的默认值,而提交作业时的参数又可以覆盖这三个配置文件的定义。如果配置文件中的属性被final标识,开发者不能覆盖其值。
经验:
在hdfs中,/tmp目录应该是对所有应用放开的,hadoop fd -chmod 777 /tmp
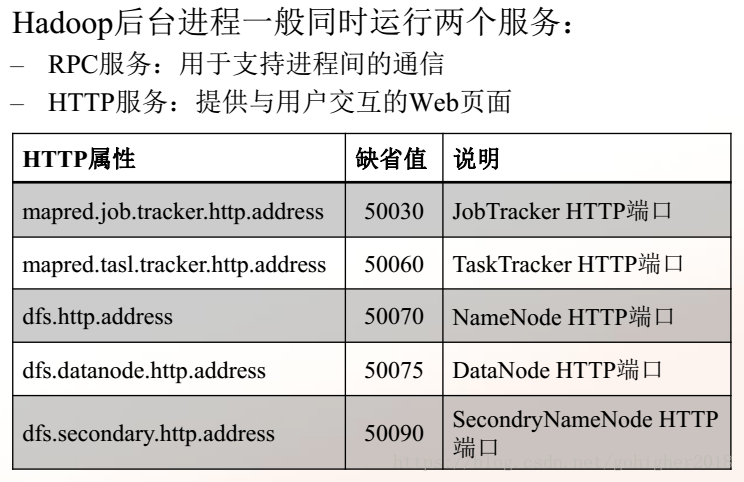
2、默认页面端口
3、bin下脚本:
hadoop-daemons.sh 将hadoop命令已守护进程方式运行
hadoop 基本管理工具:
1)balancer
再平衡,默认半分比为10%
比如,hadoop balancer -threshold 20
2)daemonlog
连接http://host:port/loglevel?log=name,以获取或设置运行在host:port的进程的日志级别
比如,JobTracker的http端口为50030
[hadoop@host03 bin]$ hadoop daemonlog -getlevel 10.221.n.43:50030 org.apache.hadoop.mapred.JobTracker
Connecting to http://10.221.n.43:50030/logLevel?log=org.apache.hadoop.mapred.JobTracker
Submitted Log Name: org.apache.hadoop.mapred.JobTracker
Log Class: org.apache.commons.logging.impl.Log4JLogger
Effective level: INFO
日志级别有,

3)dfsadmin。注意前面要加hadoop

4)namenode&secondarynamenode&datanode
这些都是前台运行的,一般不用来启动,启动用hadoop-daemon.sh
5)mradmin
6)joktracker&tasktracker
Hadoop1 日常维护
1、动态添加从节点
1)配置好新节点的主机名、ssh等。
2)在master节点上修改slaves文件,添加新节点。
3)在master节点执行刷新,hadoop dfsadmin -refreshNodes。
4)登录到新节点,启动DataNode和TaskTracker进程。hadoop-daemon.sh start datanode;hadoop-daemon.sh start tasktracker。
5)验证,hadoop dfsadmin -report
当新增节点时,整个集群存储负载可能不平衡,HDFS不会自动移动其他节点的数据到新节点,并且新的数据只往新节点写。(哪怕之前执行过balancer)。那么可以在master节点上执行start-balancer.sh/hadoop balancer(这两个命令其实是一样的)。并且可以适当修改balance的带宽,默认只有1M/s
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>2、动态卸载从节点
1)在master节点的df_excludes和mapred_excludes文件中添加需要删除的节点名。修改Name节点的hdfs-site.xml增加
<property>
<name>dfs.hosts.exclude</name>
<value>/soft/hadoop/conf/excludes</value>
</property>修改Name节点的mapred-site.xml增加
<property>
<name>mapred.hosts.exclude</name>
<value>/soft/hadoop/conf/excludes</value>
<final>true</final>
</property>新建excludes文件,文件里写要删除节点的hostname
2)刷新 hadoop dfsadmin -refreshNodes;hadoop mradmin -refreshNodes。
这个就是在将要被删除的节点上面的数据均匀着拷到其他节点上面,因此如果数据较大则关闭的时间可能会很长。
3)验证 hadoop dfsadmin -report,当节点处于Decommissioned,表示关闭成功。
3、检查文件系统一致性
fsck工具,可用来检查HDFS中损坏的文件,并帮忙查找丢失的数据块。当且仅当所有文件都有最小数量的副本可用时,文件系统才是健康的。
示例,hadoop fsck /
4、HDFS数据块均衡
balance
可以用来根据存储策略重新分配数据,将数据从过度使用的节点移到使用率较低的节点,以达到存储的平衡
5、终结MapReduce作业
1)查找想要终止的jobID,hadoop job -list。
2)hadoop job -kill $jobID
6、处理TaskTracker黑名单
如果一个TaskTracker上的任务异常,那么JobTracker将原本在这个坏掉的Tracker上面的task分发给别的TaskTracker来处理。
若持续出现问题,JobTracker会自动将其列入黑名单,默认24小时内不会向其分配任何工作。
没有命令可以查看或删改黑名单,只能通过日志查看,可通过重启坏的、Tracker的方式来移除黑名单。
7、HDFS:当Namenode异常时,
法一:可以通过cp secondaryNamenode的数据来恢复上一个checkpoint时间点的namenode数据。
法二:构建第三方离线存储。这样namenode写的时候就写两份了
8、HDFS: 数据块报告
DataNode在启动时,或者运行时定期会向NameNode发送数据块报告(BlockReport),即数据块与本地文件的对应关系。
9、HDFS: 心跳检查
DataNode会定时向NameNode发送心跳
NameNode会定时检查数据块的副本数,若不足,该数据块将会复制到其他数据节点,以达到最小副本数
10、HDFS: 完整性校验
client读HDFS文件时,如何确认读到的数据块正常呢?
当创建HDFS文件时,系统会计算每个数据块的校验和,并将校验和作为一个单独的隐含文件保存在其命名空间下。当client获取文件后,会检查从DataNode所获取的数据块校验和与从隐含文件所获取的数据库校验和是否相同(Checksum)如果不同,客户端认为数据块有损,会再从其他DataNode获取该数据块的副本。
11、HDFS: 存储资源回收
当HDFS中文件被删后,会被移到当前用户目录下的.Trash子目录中,默认保存6小时候删除。也就是在6小时以内,此删除操作和恢复。
12、HDFS: 获取HDFS状态信息
hadoop dfsadmin -report
Pig
Pig相当于一个Hadoop的client,连接到Hadoop集群后进行操作。
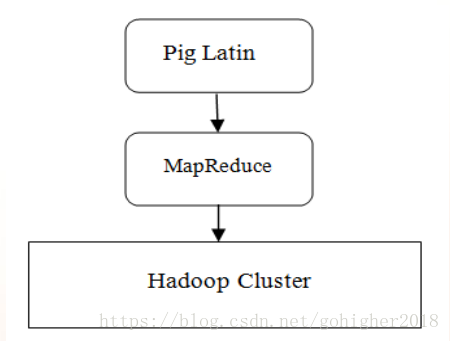
操作需要使用Pig Latin语言,这个语言是一种类似于SQL的面向数据流语言,提供了对数据进行排序、过滤、求和、分组、关联等功能并允许自定义函数。当需要处理海量数据时,先使用Pig Latin语言写脚本程序,然后在Pig中执行Pig Latin程序。Pig将用户编写的Pig Latin程序编译为MapReduce作业程序,并上传到Hadoop集群中运行。对于用户来说,MapReduce的工作完全透明的。
Hive
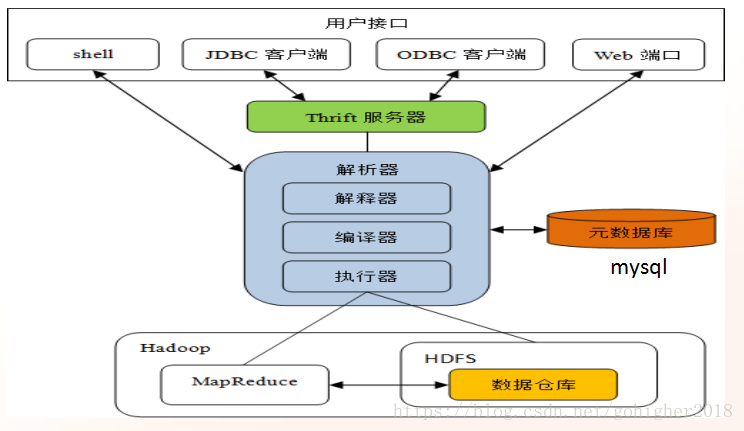
Hive SQL是一种类SQL语言
组件说明:
1)用户接口
包括HiveShell、Thrift client、Web端口等
2)Thrift服务器
当Hive已服务器模式运行时,可以作为Thrift服务器共client连接。
3)解析器
解析并执行HiveSQL语句
4)元数据库
存储Hive元数据(表名、表列、分区、属性,没有HDFS数据块位置信息)。由于Hive的元数据需要不断更新,而HDFS中的文件是多读少改的,所以元数据通常使用Mysql。
5)Hadoop
数据仓库存储在HDFS上,并由MapReduce执行解释器生成的查询计划
Thrift允许用户简单定义文件中的数据类型和服务接口,编译器生成代码来实现RPC客户端和服务器之间的通信。
Hive和Pig是同级别的,是个编程的框架,与HBase不是一个层级的概念。
Hive/Pig可以理解为一个伪SQL,真正操作的是MR、HDFS。Hive将伪SQL编程MR任务来执行,Hive表存在HDFS中。在Hive的配置文件里面会配置连那个数据仓库。如下:

Zookeeper
ZK客户端运行于功能组件节点(例如DataNode),通过TCP连接与某个ZK服务器相连,并通过这个连接发送请求、接受响应、获取观察的时间以及维持心跳信息。如果因为ZK服务器故障导致连接中断,ZK客户端会自动连接到其他ZK服务器上。若某个fellow挂了,之后好了,那么这个leader和fellow间会自动进行同步,在同步完成后,这个fellow才会开始提供服务(实际上只有同步完成后,进程才会起来)
读写过程
每个服务器都可以响应ZK客户端的读取配置信息请求,但只有主ZK服务器可以处理ZK客户端的更新配置信息请求,如果是从节点接到了写请求,那么会将这个写请求转发给主节点,必须等到leader和过半fellow都同步好了新的数据后,才会返回给client消息说我已经写好了。
watch
1、一次性
api可提供持续watch
2、watch等到的仅是个通知,通知某个znode发生了变化,因此还需要使用zk API去下载当前的znode信息。
znode类型
1、永久性
2、临时性
client和server的连接断开时,这个client创建的临时znode会被自动删除。临时znode不可有子znode。通常用于监控节点状态
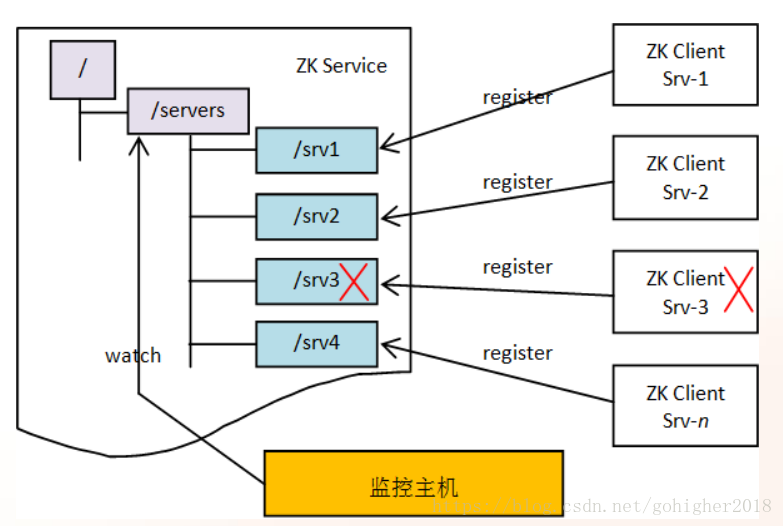
3、顺序性
在被创建时,zk服务器会自动在此znode路径的末尾添加一个递增序列。这类znode通常用于实现分布锁。最小编号加1
关于使用zk实现分布锁和队列
使用场景:当部署多台服务器时,有一个任务需要,如果没有分布式锁,则多台服务器都会执行这个任务,但是我们往往只想让其中一台服务器执行这个任务。
1)5台tomcat服务器,部署相同的war包,每个tomcat服务器都会在凌晨2点执行一次消息推送,为了防止5台服务器都推送消息,部署三台zookeeper 服务器,5台Tomcat服务器都连接上zookeeper服务器,然后在推送消息的时候,获取锁的那台服务器执行任务,从而保证了Tomcat服务器集群只有一台服务器获取锁,执行任务。
2)分布式调度,一台消息队列服务器MQ,多个业务逻辑服务器,多个业务逻辑服务器可以使用一个分布式锁去竞争消息队列数据,获取到锁的服务器获取数据,保证了消息队列的每条数据只被一台服务器获取,从而保证多台服务器并发执行任务。
1、分布式锁
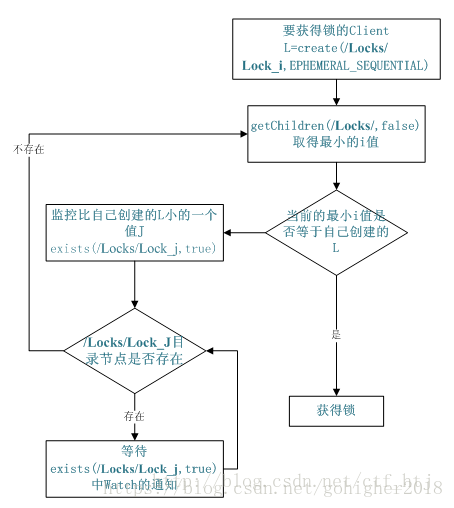
1)首先创建一个作为锁目录,通常用它来描述锁定的实体,类型为永久性。
2)希望获得锁的客户端在锁目录下创建znode,作为锁目录的子节点,并且节点类型为有序+临时节点;
例如:有两个客户端创建znode,分别为/Locks/lock-1和/Locks/lock-2
3)当前客户端调用getChildren(/Locks)得到锁目录所有子节点,不设置watch,接着获取小于自己(步骤2创建)的兄弟节点
4)步骤3中获取小于自己的节点不存在 && 最小节点与步骤2中创建的相同,说明当前客户端顺序号最小,获得锁,结束。
5)客户端监视(watch)相对自己次小的有序临时节点状态
6)如果监视的次小节点状态发生变化,则跳转到步骤3,继续后续操作,直到退出锁竞争。
2、分布式队列
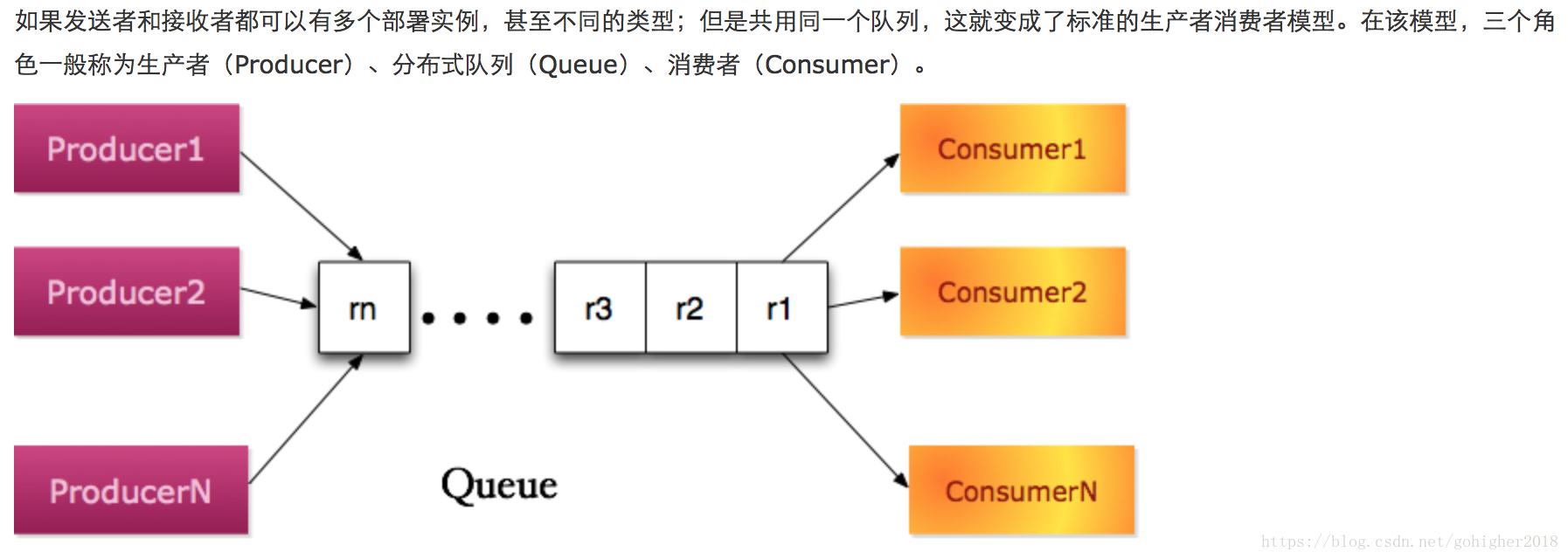
应用场景
1、统一命名服务
zk的命名服务将层次型的目录结构关联到一定资源上
2、配置管理
3、集群节点监控
临时性节点
4、集群选主
这里指的是与hadoop结合,选hadoop的主master,即namenode。


这个功能仅仅是在与hadoop结合上,zk没有可以选app服务器主的功能。
客户端命令



HBase
1、概述
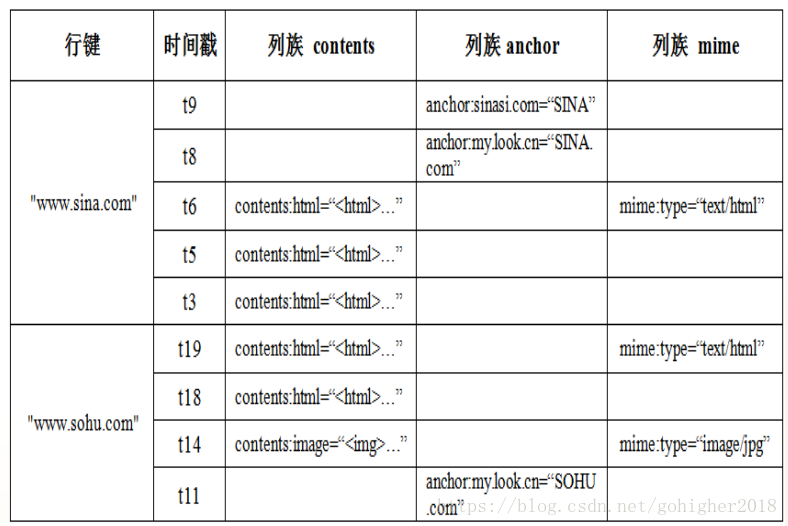
行键唯一标识,最大长度为64KB。共有3个列族,共包含5列,每一列以前缀的方式给出其所属的列族。列族contents中有3列,列族anchor中有2列, 列族mime中有1列。<列族><限定符>,限定符即列名。
数据版本回收方式:
1)对每个数据单元,只存储最新版本
2)保存最近一段时间内的版本
HBase只有一个HMaster在运行。单点。 HMaster责任如下:
1)将Region分配给HRegionServer,协调HRegionServer的负载
2)若HRegionServer坏了,HMaster会通过zk感知到(临时znode注册),随机处理相应的HLog文件,重新分配Region
HMaster不会对client提供服务,不参与数据的输入输出过程,仅维护表和Region的元数据。而是由HRegionServer负责所有Region的读写请求。HMaster坏了不会影响一定量内的表数据的读写。若数据量达到使得表结构改变了,则不能操作了,因为需要用到HMaster了
所有Region的元数据存储在一个叫做.META.表(在HMaster上)中,当表过大时,同样会分裂为多个Region。进一步的,HBase将.META.表中的所有元数据保存在-ROOT-表中,由zk记录-ROOT-表的位置信息。这个-ROOT-表永远有一个Region。为加快访问速度,元数据表会在内存中也存储一份。

ZK的作用:
存储“-ROOT-表 ”地址、“HMaster”的地址
2、HBase存储结构
每个HBase表由一个或多个Region组成。运行时,每个Region对应一个HRegion实例,这些实例被一个或多个HRegionServer进程所管理(同常一台机器上仅运行一个HRegionServer),一个表的所有Region会分布在尽量多不同的HRegionServer上被管理,但一个Region内的数据只会被一个服务器所管理。
HBase在行的方向将表分成了多个Region,每个Region包含了一定范围内(根据行键进行划分)的数据。每个表最初只有一个Region。随着数据不断插入到表中,Region不断变大。当增大到一个阈值时,Region会被分成两个新的Region。一段时间后,一个表同常会包含多个Region。Region是HBase的最小单位。
物理上数据都存储在HDFS上,由HRegionServer提供数据服务。
HLog用于灾备,使用了预写式日志(WAL)。每个HRegionServer只维护一个HLog,来自不同表的Region日志是混在一起的。这样的好处是减少了磁盘寻址次数,提高对表的写性能。不好之处是,若某一台HRegionServer坏了,为了恢复其上面的Region,需要将HLog进行拆分,分发到其他HRegionServer上来恢复。被分配到新HRegionServer上面的Region会领取失效服务器中属于它的HLog,并将其中的信息重新加载到MemStore中。
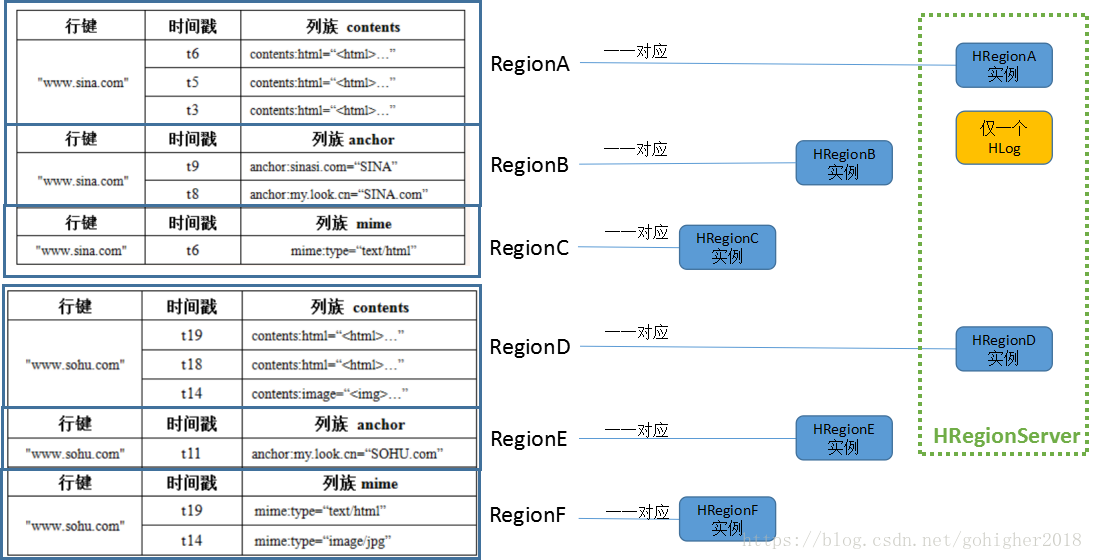
下面具体详细说明下Region内部结构,
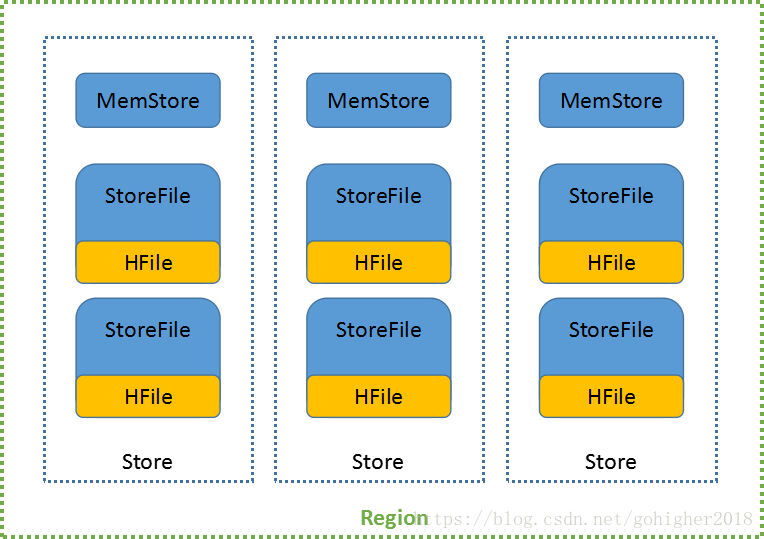
每个Store保存一个列族的所有数据。
在写操作时,首先连接到相应的HRegionServer,然后向Region提交数据。提交的数据会首先被写入WAL和MEMStore,之后返回(保证HBase I/O高性能 )。当MemStore数据写满了之后,HRegionServer会启动一个单独的线程,执行Flush操作将数据写至StoreFile。StoreFile以HFile的格式存储在HDFS上。
数据的合并:当StoreFile文件的数量到达阈值后,HRegionServer会将多个StoreFile合并(Compact)为一个大的StoreFile。在这个合并的过程中,才真正会有数据的删除等操作。之后,随着StoreFile越来越大,超过阈值后会将当前的Region分割成两个Region,并由HMaster分配到相应的HRegionServer上。
3、HBase与HDFS
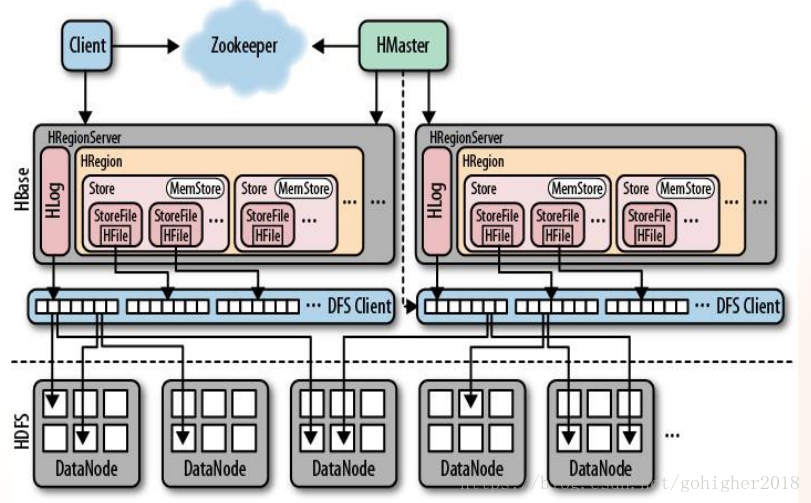
HFile仅一份,可以看做是我人工往HDFS上写了一个文件,之后的DFS client(即HDFSclient)会将HFile拆分为数据块,每个数据块在HDFS上存三份,这个过程对我的透明的。具体可看前面的HDFS写过程。
元数据表在HMaster中
4、安装
配置文件
hbase-env.sh
hbase-site.xml
regionservers
Hadoop2
1版本的局限性
1)HDFS:NameNode元数据时放在内存中的,受主机内存大小的限制。单点故障
2)MapReduce:JobTracker容易成为瓶颈。JobTracker可实际管理和监控的节点数量会在4000-5000
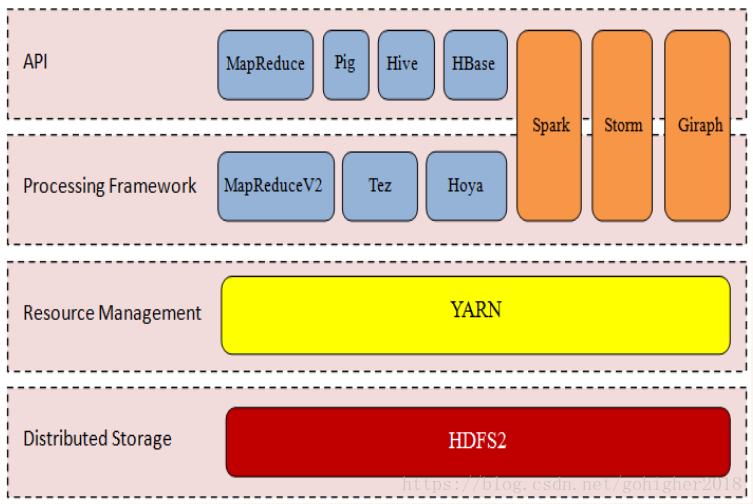
资源管理层:YARN将资源管理从Hadoop1的数据处理中分离出来
数据处理框架层:MapReduce2是基于YARN的框架。
HDFS架构
NameNode高可用。主备NameNode都需要访问edits文件。当主NamaNode写入edits日志时,备NameNode会事务性的确保数据完全同步。这里主要就是edits文件,因为fsimage仅仅是在启动的时候读一下。edits文件就是一个,主备NameNode都读这同一个文件。对于此有两种文件共享机制,具体见下面。
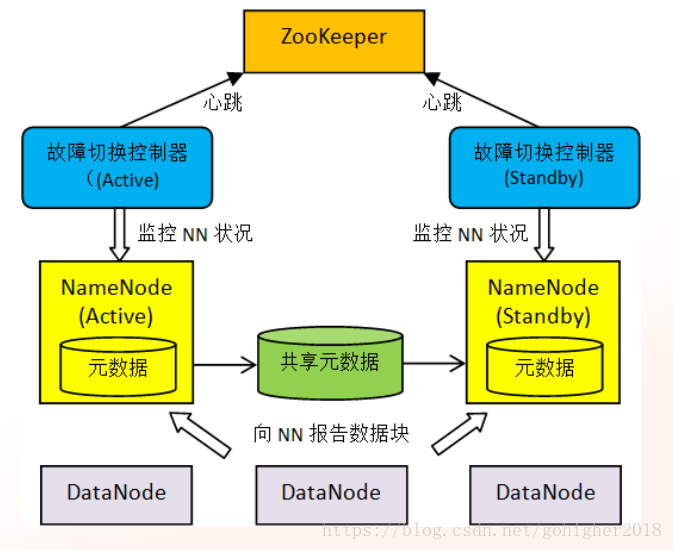
所有的DataNode都会同时向主备NameNode(NN)发送数据块报告。主NameNode坏了DataNode不知道,依旧发送。没有Hadoop1中的SecondaryNameNode了
HDFS支持两种共享机制:
1)JournalNode集群:默认。JournalNode应保持奇数个,edits分块存储在各个JournalNode上,由JournalNode来保证edits的高可用
2)NFS:需要自己加
zk可进行应用端的主备切换,这个功能是zk提供给Hadoop使用的,别的不成。比如,使用zk进行redis主备的切换,这个是没有接口的,需要自己写watch,自己写应用端(redis)切换的程序。
YARN
MapReduce2是基于YARN进行重构的MapReduce计算框架。负责Hadoop1中的资源管理的功能,MapReduce2仅是应用的计算功能,类似storm、spark
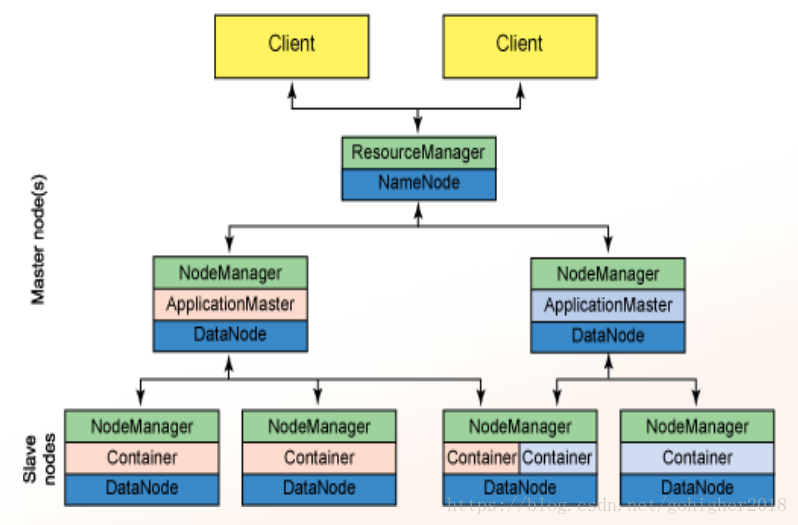
ResourceManager:负责Application(里面有好多Task)的调度、管理、资源分配
NodeManager:具体执行的模块,Hadoop1中的Slot在这里是Container,Task通过在NodeManager上启动Container的方式来执行。
程序运行过程如下:
1)客户端提交一个程序
2)ResourceManager分配一个NodeManager,这个NodeManager在本机上为程序创建一个ApplicationMaster。若ApplicationMaster 坏了client会知道,那么就重新创建一个ApplicationMaster
3)ApplicationMaster向ResourceManager注册。计算出应用程序所需的资源情况,向ResourceManager要资源。(ApplicationMaster在运行是会向ResourceManager发心跳,以及资源的情况)
4)ResourceManager授权ApplicationMaster租用Container,ResourceManager会告诉ApplicationMaster可供使用的Container位置
5)ApplicationMaster通过NodeManager获取指定的Container。NodeManager创建Container。
6)现在程序将在Container上运行,ApplicationMaster会监控Container的运行,若某一个Container失败,任务将会在下一个可用的Container重启,重启4次还失败,ApplicationMaster会直接与client通信反馈失败。
7)在Container运行时,ResourceManager可以向NodeManager发送kill指令,中断某个特定的Container
8)同样的,Map任务完成后,ApplicationMaster会为Reduce任务申请资源。
9)成功完成后,ApplicationMaster会将结果直接告知client,并且通知ResourceManager自己的应用程序已执行完成,让ResourceManager注销自己,之后自行关闭。
几个Map可以程序中定,默认由YARN来分
数据的导入导出
Flume/Chukwa:用于将日志文件导入HDFS
HFS(Slurper):用于导入导出半结构化或二进制数据
Oozie:用于定期导入数据
Sqoop:简称SQL-Hadoop。用于导入导出数据库数据,hadoop处理完数据后,将结果导出到传统数据库中,用于查询,这个比较常见。
1、安装配置Sqoop
主节点安就可以。
2、安装配置Flume
创建配置文件
vi /opt/apache-flume-1.6.0-bin/conf/flume.conf
输入以下内容:
指定一个Agent的组件名称 为a1
a1.sources = r1 数据来源,a1中的sources叫做r1
a1.sinks = k1 输出路径
a1.channels = c1 队列指定Flume source(要监听的路径)
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/flumein指定Flume sink
a1.sinks.k1.type = logger 直接输出到屏幕上指定Flume channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100绑定source和sink到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume agent
flume-ng agent --conf conf --conf-file /opt/apache-flume-1.6.0-bin/conf/flume.conf --name a1 -Dflume.root.logger=INFO,consolevi 1.log
Hello Flume然后拷贝到flume监听路径。
cp 1.log /home/hadoop/flumein
cp 1.log /home/hadoop/flumeinHadoop2-HA 搭建
| - | server1 | server2 | server3 | server4 | 命令 |
|---|---|---|---|---|---|
| 1、zk(QuorumPeerMain) | Y | Y | Y | zkServer.sh start | |
| 4、DFSZKFailoverController | Y | Y | hadoop-daemon.sh start zkfc | ||
| 3、NameNode | Y | Y | hadoop-daemon.sh start namenode | ||
| 5、DataNode | Y | Y | Y | hadoop-daemon.sh start datanode | |
| 2、Journalnode | Y | Y | Y | hadoop-daemon.sh start journalnode | |
| 6、NodeManager | Y | Y | Y | start-yarn.sh | |
| 6、ResourceManager | Y | start-yarn.sh |
其他
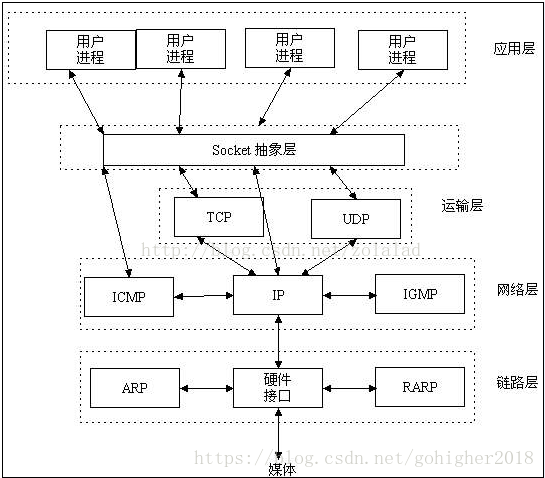
RPC&RMI&Socket
RPC是远程过程调用,是会话层的协议,基于TCP/IP。C/S模式。是分布式程序的基础(分布式操作系统、分布式计算、分布式软件设计)。是个框架,编程时使用RPC,可实现像调用本地方法一样调用远端的方法。
RMI是RPC的Java版本
Socket:
RPC通过socket接口来使用TCP/IP,实现网络通信。其他常用的应用层协议(FTP、HTTP、TELNET、SMTP)也同样是通过socket这个接口来使用TCP/IP,实现网络通信。Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式(Facade),它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。