本文将详细探讨Hadoop1和Hadoop2和Hadoop3之间的差异,借鉴了某些外国技术博客
Hadoop1和Hadoop2之间的差异
1. Components(组件)
在 Hadoop 1中我们有 MapReduce,但 Hadoop 2有 YARN (另一种资源协调者)和 MapReduce 版本2。
| Hadoop 1 | Hadoop 2 |
|---|---|
| HDFS | HDFS |
| Map Reduce | YARN / MRv2 |
2. Daemons(守护进程)
| Hadoop 1 | Hadoop 2 |
|---|---|
| Namenode | Namenode |
| Datanode | Datanode |
| Secondary Namenode | Secondary Namenode |
| Job Tracker | Resource Manager |
| Task Tracker | Node Manager |
3. Working(工作)
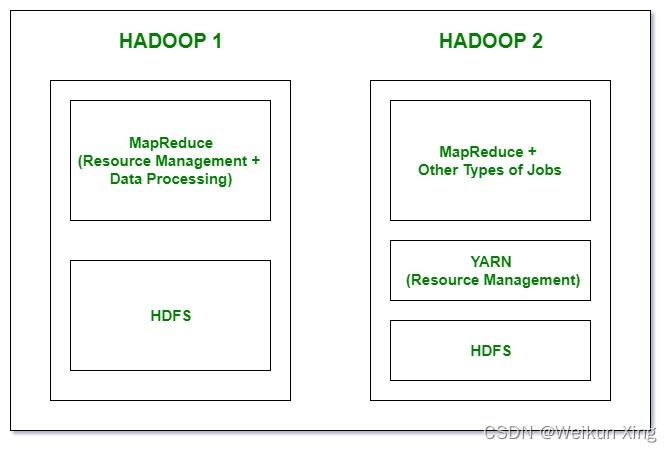
在Hadoop 1中,有HDFS用于存储,Map Reduce作为资源管理和数据处理。由于Map Reduce上的这种工作负载,它将影响性能。
在Hadoop 2中,同样有用于存储的HDFS,在HDFS的顶部有作为资源管理的YARN。它基本上分配了资源并使所有的事情继续进行。
4. Limitations(局限性)
Hadoop 1是一个主从架构。它由一个主服务器和多个从服务器组成。假设主节点崩溃了,那么不管你最好的从节点是什么,你的集群都会被摧毁。同样,创建这个集群意味着在另一个系统上复制系统文件、映像文件等非常耗时,这是当今组织所不能容忍的。
Hadoop 2也是一个主从架构。但它由多个主节点(即活动名称节点和备用名称节点)和多个从节点组成。如果主节点崩溃了,备用主节点就会接管它。主备节点可以进行多种组合。因此,Hadoop 2将消除单点故障的问题。
5. Ecosystem(生态系统)
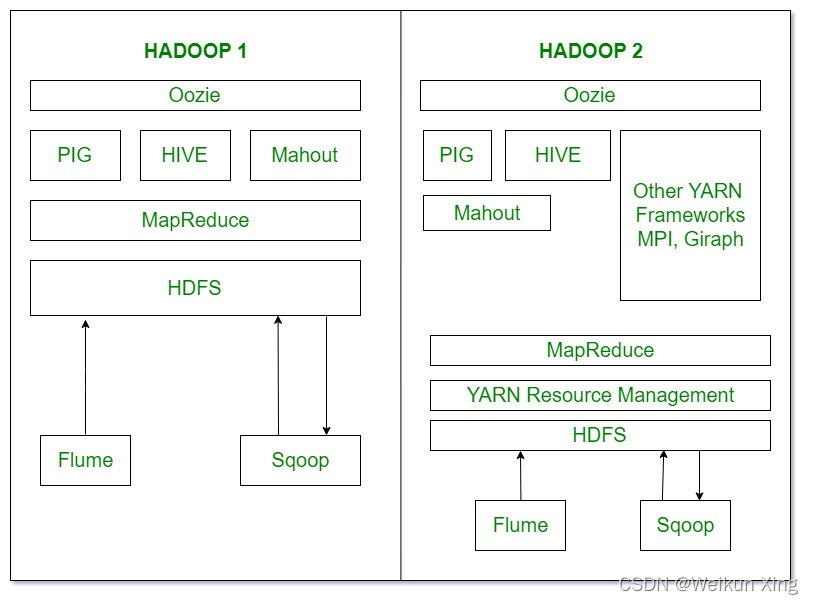
Oozie基本上是工作流调度程序。它根据作业的依赖关系决定执行作业的特定时间。
Pig、Hive和Mahout是在Hadoop之上工作的数据处理工具。
Sqoop用于导入和导出结构化数据。您可以通过SQL数据库直接将数据导入、导出到HDFS中。
Flume用于导入导出非结构化数据和流数据。
Hadoop2和Hadoop3之间的差异
显然,Hadoop 3. x 比较早期版本的 Hadoop 2. x 有一些更高级和兼容的特性。
1.License(许可证)
Hadoop 2.x – Apache 2.0, Open Source(开源)
Hadoop 3.x – Apache 2.0, Open Source(开源)
2.支持Java的最低版本
Hadoop 2.x – Java 的最小支持版本是 java7
Hadoop 3.x – Java 的最小支持版本是 java8
3.Fault Tolerance(容错性)
Hadoop 2.x – 容错可以通过复制来处理(这会浪费空间)
Hadoop 3.x – 容错可以通过删除编码来处理
4.数据平衡
Hadoop 2.x – HDFS 均衡器用于数据平衡
Hadoop 3.x –使用内部数据节点平衡器,通过 HDFS 磁盘平衡器命令行界面调用
5.贮存计划
Hadoop 2.x – 使用3x 复制模式
Hadoop 3.x –支持 HDFS 中的擦除编码
6.存储开销
Hadoop 2.x – HDFS 在存储空间上有200% 的开销
Hadoop 3.x –存储开销只有50%,这意味着我们有更多的空间来工作
存储开销示例
贴上英文,对照理解
Hadoop 2.x – If there is 6 block so there will be 18 blocks occupied the space because of the replication scheme.
如果有 6 个块,那么由于复制方案,将有 18 个块占用空间。
Hadoop 3.x – If there is 6 block so there will be 9 blocks occupied the space 6 block and 3 for parity.
如果有 6 个块,那么将有 9 个块占用空间 6 个块和 3 个用于奇偶校验。
7.YARN Timeline Service(YARN时间轴服务)
Hadoop 2.x – 使用具有可伸缩性问题的旧Timeline Service。
Hadoop 3.x –改进Timeline Service,提高服务的可扩展性和可靠性
8.默认端口范围
Hadoop 2.x – 在 Hadoop 2.0中,一些默认端口是临时端口范围。因此在启动时,它们将无法绑定
Hadoop 3.x –但是在 Hadoop 3.0中,这些端口已经移出了临时范围
9.可扩展性
Hadoop 2.x – 有限的可扩展性,一个集群中最多可以有10000个节点
Hadoop 3.x – 可扩展性得到改善,一个集群中可以有超过10000个节点
10.Tools(工具)
Hadoop 2.x – Hive, pig, Tez, Hama, Giraph and other Hadoop tools.
Hadoop 3.x – Hive, pig, Tez, Hama, Giraph and other Hadoop tools are available(可用的).
11.兼容文件系统
Hadoop 2.x – HDFS (默认 FS) ,FTP 文件系统: 这存储所有的数据在远程可访问的 FTP 服务器。Amazon S3(简单存储服务)文件系统 Windows Azure Storage Blobs (WASB)文件系统
Hadoop 3.x – 所有文件系统,包括 Microsoft Azure Data Lake 文件系统
12.Name Node recovery(Name Node恢复)
Hadoop 2.x – 恢复需要人工干预
Hadoop 3.x – Name Node恢复不需要手动干预
13.Datanode Resources(数据节点资源)
Hadoop 2.x – Datanode resource不是专用于MapReduce的,我们可以将它用于其他应用程序。
Hadoop 3.x – 这里的数据节点资源也可以用于其他应用程序。
14.MR API Compatibility(MR API兼容性)
Hadoop 2.x – MR API compatible with Hadoop 1. x program to execute on Hadoop 2.x
MR API 兼容 Hadoop 1.x 程序在 Hadoop 2.x 上执行
Hadoop 3.x – Here also MR API is compatible with running Hadoop 1. x programs to execute on Hadoop 3.x
这里 MR API 也兼容运行 Hadoop 1.x 程序以在 Hadoop 3.x 上执行
这段翻译还是谷歌翻译翻译的比较贴切.
15.Cluster Resource Management(集群资源管理)
Hadoop 2.x – 对于集群资源管理,它使用 YARN。 它提高了可扩展性、高可用性、多租户
Hadoop 3.x – 对于集群,资源管理使用 YARN,具有所有功能。
当然还有其他差异,大家可以在评论区探讨,如果我文章写的不对的地方,还请大佬们,哥哥姐姐们在评论区直接怼我,哈哈
