1、卷积计算

卷积运算实现垂直边缘检测

过滤器检测不同方向的边缘

Padding

输入图片维度信息是[6,6],卷积核尺寸[3,3],padding=1,步长stride=1,经过卷积运算之后输出图片维度信息也是[(6+2x1-3+1),(6+2x1-3+1)],这样也就保持维度信息的一致性,不致于特征信息丢失。
计算公式:n = (n-f+2p)/s+1 ,n是指输入/输出维度信息,f是卷积核或过滤器,p是0元素填充个数,s是卷积核的步长。
如果两边n的维度信息都一样,且默认s = 1的情况下,就可以求出p = (f-1)/2,所以当f是一个奇数的时候,p的范围[0,1,2,3,4,…, (f-1)/2],只要选择相应的填充尺寸,就能保证得到输入相同尺寸的和输出。当卷积核5x5,使得输入和输出的维度信息都一样,就要保证f=5对应的p=2,一般情况下卷积核尺寸都是奇数,很少看到一个偶数的卷积核,为了保证输入维度信息周边都能均匀地填充0元素,我推荐你只用奇数的卷积核。在数字图像处理课程中是这样的,当你用卷积核与图像进行卷积时,是对应点相乘相加,最后输出在中心点的位置,如果是奇数,就刚好有中心点,偶数就没有了。
至于选择填充多少像素,通常有两个选择,分别叫做Valid卷积和Same卷积。
Valid
意味着padding的0元素填充个数为0,卷积运算输出维度信息:[n-f+1,n-f+1]
Same
意味着你填充padding之后,你的输入大小和输出大小是一样的。根据这个公式,当你填充p个像素点,原来输入的维度信息经过卷积运算之后得到新输出的维度信息[n+2p-f+1,n+2p-f+1]
卷积步长
input:7,f:3,s:2,output:3
代入式子output = (input-f+2p)/s+1,从而得到padding = 0

还有一个细节需要注意,如果输出的维度信息不是一个整数怎么办?这种情况下要向下取整。output = floor[(input-f+2p)/s+1]

2、卷积为何有效
RGB图片的卷积
图像的通道数也要与过滤器的通道数保持一致。

单过滤器
过滤器有三个通道,共有3x3x3=27个元素需要与待卷积图像对应点相乘相加,最后输出在中心点的位置。当padding=0,output = n-f+1 = 6-3+1=4

多过滤器

3、单层卷积网络
假设在一个神经网络的某一层有10个3x3x3尺寸的过滤器,那么这一层总共有多少参数呢?
parameters : (3 * 3 * 3 + bias) * 10 = (27 + 1) * 10 = 280

请注意一点,无论你输入的图片尺寸有多大,用这10个过滤器来提取特征,参数始终都是280个。即使图片尺寸很大,参数却很少。这就是卷积神经网络的一个特征——避免过拟合。
符号摘要
If layer
is convolution layer:
通常情况下,上标
用来标记第
层
= filter size 第 层中过滤器的尺寸大小为 x
= padding 标记padding的数量,也可以指定Valid(无padding)或Same(有padding,输出和输入图片的高度和宽度就相同了)
= stride 标记步长
Input:
x
x
x
代表第
层输入某个维度的数据,
通道数量
Output:第 层的图片大小为 x x ,第 层的输入就是上一层的输出,神经网络中这一层的输出图像大小为 x x
:channel在学术上既可表达通道也可以是深度,输出图片也具有深度,输出图像中的通道数量等于神经网络中该层所使用过滤器的数量。
每一个过滤器尺寸大小:
x
x
,过滤器的通道数量必须与输入数据的通道数量一致。
=
这样输出通道数量就是输入通道数量
计算输出图像高度或宽度公式:
,
,向下取整。
Activations:应用偏差和非线性函数之后,这一层的输出等于它的激活值
,
是一个三维体,即
x
x
,当你执行批量梯度下降或小批量梯度下降时,如果有m个例子就有m个激活值的集合,那么输出的
=
x
x
x
变量排列顺序:首先是索引和训练样本,其次是高度,宽度,通道数。
Weights: 权重参数,怎样确定权重参数的数量?已知 x x 代表一个过滤器的元素数量,而权重数量是所有过滤器的集合再乘以每个过滤器的元素数量, 就是层 过滤器的个数,故Weights = x x +
Bias:每个过滤器都有一个偏置参数,它是一个实数,可用
代表偏置,它是该维度上的一个向量(线代中默认向量为列向量),偏置在代码中表示为一个1 x 1 x 1 x
的四维向量或四维张量。
— (1,1,1,
)
在线上搜索或学习开源代码,关于高度、宽度和通道的顺序并没有完全统一的标准卷积,所以在查看GitHub上的源代码或阅读一些开源实现的时候,你会发现有些作者会采用把通道放在首位的编码标准。很遗憾!这只是一部分标记法,因为深度学习的相关文献并未对标记达成一致。
4、简单卷积网络示例
Convolution(Conv)
Polling(Pool)
Fully connected(FC)

虽然仅用卷积层也有可能构建出很好的神经网络,但是在部分神经网络架构师依然会添加池化层和全连接层。
5、池化层
Max pooling

Average pooling

Summary of pooling

6、卷积神经网络示例
下面我们来看一个例子,假设有一张大小为32x32x3的输入图片, 这是一张RGB模式的图片,你想做手写体数字识别,32x32的RGB图片中含有某个数字,比如“7”。你想识别它是属于10个数字(0~9)中的哪一个。现在我们基于这个简单任务构建一个神经网络来实现这个功能。我使用这个网络模型和经典网络LeNet-5非常相似,灵感也来源于此。现在我所采用的模型并不是LeNet-5,但是受它启发,许多参数选择都与LeNet-5相似。
输入一个32x32x3的矩阵,假设第一层使用的过滤器(f)大小为5x5,步幅(s)是1,padding是0,过滤器个数是6
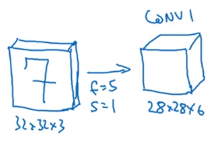
那么输出为28x28x6,将这层标记为CONV1,该层用了6个过滤器,增加了偏差,应用了非线性函数(ReLu),最后输出CONV1的结果。
将CONV1 输出的28x28x6 作为输入,输入到池化层。
现在开始构建池化层(最大池化),该层超参数f=2,s=2,padding=0,maxpool使用的过滤器(f)为2x2,步幅(s)为2,padding为0,表示该层的高度和宽度会减少一半。因此28x28变成了14x14,其中信道数量保持不变,所以最终输出为14x14x6,将该输出标记为POOL1。
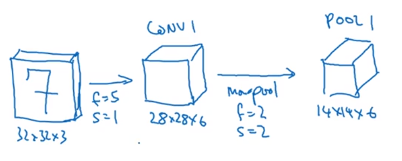
在卷积网络文献中,卷积有两种分类,这与所谓层的划分存在一致性,A类卷积是一个卷积层和一个池化层一起作为一层,这就是神经网络的Layer1层
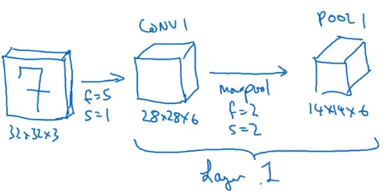
另一类卷积是把卷积层单独作为一层,而池化层单独作为一层,人们在计算神经网络有多少层时,通常只是统计具有权重和参数的层,因为池化层没有权重和参数,只有一些超级参数,所以刚才我们把CONV1和POOL1共同作为一个卷积并标记为Layer1。虽然你在阅读网络文章或研究报告时,可能会看到卷积层和池化层各为一层的情况,这只是两种不同的标记术语。一般我在统计网络层数时,只计算具有权重的层,也就是把CONV1和POOL1作为Layer1。这里我们用CONV1和POOL1来标记,两者都是神经网络Layer1的一部分。POOL1也被划分在Layer1中,因为它没有权重,得到的输出是14x14x6。
把上一层输出的14x14x6作为输入,输入到下一层的卷积。既是输入又输出的层可以看作为隐含层。新构建的卷积层,过滤器(f)大小为5x5,步幅(s)为1,过滤器数量为10,最后输出一个10x10x10的矩阵,并标记为CONV2然后做最大池化,maxpool超参数f=2,s=2,同样高度和宽度会减半,最后输出为5x5x10 ,标记为POOL2。这就是神经网络的第二个卷积层,即Layer2。

如果Layer1后面接另一个卷积层,该卷积层超参数f=5x5,s=1,padding=0,过滤器数量为16,则CONV2输出为10x10x16,继续执行最大池化计算,超参数f=2,s=2,p=0,输入的宽度和高度会减半的,输出结果为5x5x16,信道数量和之前一样,标记为POOL2。把这个卷积标记为Layer2。
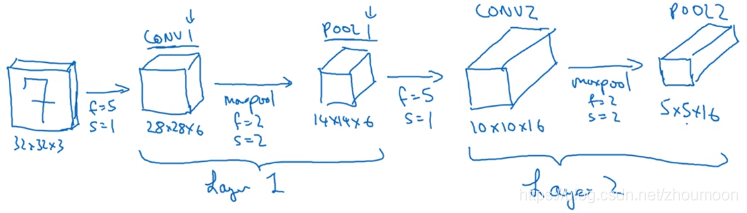
5x5x16矩阵包含400个元素,现在将POOL2平整化为一个大小400的一维向量。把平整化的结果想象成像一个神经元集合。

然后利用这400个单元构建下一层,下一层含有120个单元。这就是我们第一个全连接层,标记为FC3,这400个单元与120个单元紧密相连,这样就构成一个标准的神经网络。

它在120x400的维度上具有一个权重矩阵
,这就是所谓的全连接,因为这400个单元与这120个单元中的每一个单元相连接,还有一个偏差参数,最后输出维度大小是120,因为FC3只有120个输出。
然后我们在FC3层后面再添加一个全连接层,这层更小,假设它含有84个单元,标记为FC4。最后用这84个单元填充一个softmax单元,如果我们想通过手写数字识别来识别手写的0-9数字,那么这个softmax就会有10个输出。

此例中的卷积神经网络很典型,看上去它有很多超级参数,关于如何选定这些参数?常规做法是尽量不要自己设置超级参数,而是查看作者论文或文献采用了哪些超级参数,选一个在作者任务中效果很好的架构,那么它也有可能适用于你自己的应用程序。
随着神经网络深度的加深,高度和宽度通常都会减少,前面已经提到过,从32x32=>28x28=>14x14=>10x10到5x5,而信道数量会增加,从3=>6=>16不断增加,然后得到一个全连接层。在神经网络中,另一种常见模式就是一个或多个卷积层后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个softmax,这是神经网络的另一种常见模式。
下面表格描述神经网络的激活值形状、激活值大小和参数数量。
Neural network example
| Activation shape | Activation Size | # parameters | |
|---|---|---|---|
| Input: | (32,32,3) | 3072 | 0 |
| CONV1(f=5,s=1) | (28,28,8) | 6272 | 208 |
| POOL1 | (14,14,8) | 1568 | 0 |
| CONV2(f=5,s=1) | (10,10,16) | 1600 | 416 |
| POOL2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 48001 |
| FC4 | (84,1) | 84 | 10081 |
| Softmax | (10,1) | 10 | 841 |
表格第二行分析:激活值
有3072维 = 32 x 32 x 3,输入层没有参数。
其它行分析:这些都是网络中不同层的激活值形状、激活大小和参数数量。有几点需要注意。第一,池化层(POOL)没有参数;第二,卷积层的参数相对较少,其实很多参数都存在于神经网络的全连接层。从表格观察中可以发现,随着神经网络的不断加深,激活值会逐渐变小,如果激活值下降太快,也会影响网络性能。第一层的激活值是6272,第二层激活值1600,慢慢减少到84,最后输出softmax结果。
至此神经网络的基本构造模块基本讲完,一个卷积神经网络包括卷积层、池化层和全连接层。许多计算机视觉研究正在探索,如何把这些基本模块整合起来构建高效的神经网络。整合这些基本模块确实需要深入的理解和感觉,根据我的经验,找到整合基本构造模块的感觉,最好的方法就是大量阅读别人优秀的案例,或许你也可以将别人开发的框架应用于自己的应用程序。
为什么使用卷积
我们来分析一下卷积在神经网络中如此受用的原因,以及如何整合这些卷积,如何通过一个标注过的训练集训练卷积神经网络做一个简单地概括。
卷积层与全连接层相比,卷积层比全连接层映射的参数要少,主要有两原因:
(1)参数共享。举例说明一下,假设有一张32x32x3的纬度图片,用了6个大小为5x5的过滤器,输出维度为28x28x6。

我们构建一个神经网络,其中一层含有3072个单元,下一层含有4074个单元,两层中的每个神经元彼此相连,然后计算权重矩阵,它就等于3072x4704约等于1400万,所以要训练的参数很多。虽然以现在的技术我们可以用1400万个参数来训练网络,因为这张32x32x3的图片非常小,训练这么多参数没有问题。如果这是一张1000x1000的图片,权重矩阵会变得非常大。卷积层的参数数量等于每个过滤器尺寸大小乘以过滤器数量,过滤器尺寸大小是5x5,一个过滤器有25个参数,再加上偏差参数,那么每个过滤器就有26个参数,一共有6个过滤器,所以参数总计156个。
(2)稀疏连接
featuremap绿色圈标记的0元素就是通过3x3的卷积计算得到的,它只依赖于这个3x3的输入单元格,输出的featuremap仅与左边36个输入特征中的9个元素相连接,而且其它像素值都不会对输出产生任何影响,这就是稀疏连接的概念。

卷积神经网络善于捕捉平移不变的性质,通过观察可以发现向右移动两个像素,图片中的猫依然清晰可见。因为神经网络的卷积结构使得即使移动几个像素,这张图片依然具有非常相似的特征,应该属于同样的输出标记。实际上使用同一个过滤器生成各层中图片的所有像素值,希望网络通过自动学习变得更加健壮,以便更好地取得所期望的平移不变属性,这就是卷积或卷积网络在计算机视觉任务中表现良好的原因。
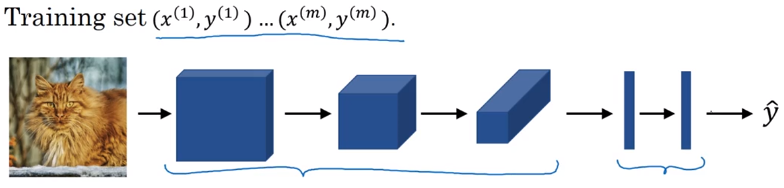
最后,我们把这些层整合起来,观察如何训练这些网络。比如我们要构建一个猫咪检测器,有下面这些标记训练集,
表示一张图片,
是二进制标记或某个重要标记。我们选定了一个卷积神经网络,输入图片,增加卷积层和池化层,然后添加全连接层,最后输出一个softmax,即
。卷积层和全连接层有不同的参数
和偏差
,我们可以用任何参数集合来定义代价函数
随机初始化函数参数 和 , 等于神经网络对整个训练集的平均预测损失总和,所以训练神经网络就要使用梯度下降法,或含有动量、RMSProp及其它因子的梯度下降来优化神经网络的所有参数,以减少代价函数 的值。
通过上述操作你可以构建一个高效的猫咪检测器或其它检测器。你也可以尝试去判断哪些网络架构类型效率更高,人们通常的做法是将别人发现和发表在研究报告上的架构应用于自己的应用程序。
参考
[1]深度学习的局部响应归一化LRN理解
[2]卷积神经网络之AlexNet
[3]https://blog.csdn.net/program_developer/article/details/89462239
[4]https://www.deeplearning.ai
