JOISC 2020 Day1
T1 Building4
原题
CSDN下载:https://download.csdn.net/download/Ljnoit/12257726
链接
翻译
题目描述
给定长度为
的两个序列,分别为序列
2N ,和序列
2N 。
构造一个长度为
的序列
。满足以下条件:
- 序列 的第 个数 ,只能从 和 中选取。
- 设 为序列 中元素被选取的次数, 为序列 中元素被选取的次数,则 。
- 该序列是一个单调上升的序列,不要求严格单调上升。
如有多解,任意输出一组解即可。
输入格式
第一行包含一个数字
,表示序列长度的一半。
第二行包含
个数字,第
个数字表示序列
中的第
个数字
。
第三行包含
个数字,第
个数字表示序列
中的第
个数字
。
输出格式
你不需要直接输出这个序列。
你只需要输出一行长度为
的字符串
, 如果序列
的第
个数从
中选取,则
,否则
。
如果无解,输出一行一个数
。
样例输入 1
3
2 5 4 9 15 11
6 7 6 8 12 14
样例输出 1
AABABB
样例解释 1
序列 C 为 (2,5,6,9,12,14) ,分别选取的是 A1,A2,B3,A4,B5,B6 ,可以验证序列 C 满足所有条件。
样例输入 2
2
1 4 10 20
3 5 8 13
样例输出 2
BBAA
样例解释 2
多解输出任意解。
样例输入 3
2
3 4 5 6
10 9 8 7
样例输出 3
-1
样例解释 3
无法构造满足条件的排列,输出 −1 。
样例输入 4
6
25 18 40 37 29 95 41 53 39 69 61 90
14 18 22 28 18 30 32 32 63 58 71 78
样例输出 4
BABBABAABABA
数据范围与提示
对于 % 的数据,保证
子任务 1 ( 11 分):
。
子任务 2 ( 89 分):没有特殊性质。
解析
先不管n个A的限制,从左往右扫一遍,每次选尽量小的,先保证有解。若无解,直接输出"-1"。
考虑有些位置的选择可以改变,x改变了,x+1可能要改变,可能不要改变。
如果x改变了,x+1必须跟着改变,x->x+1连一条边,不难发现有若干条链。
每一条链可以选一个后缀。我这里type=0是A、type=1是B。
代码
#pragma GCC optimize(3,"Ofast","inline")
#pragma G++ optimize(3,"Ofast","inline")
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
#define R register int
#define re(i,a,b) for(R i=a; i<=b; i++)
#define ms(i,a) memset(a,i,sizeof(a))
#define MAX(a,b) (((a)>(b)) ? (a):(b))
#define MIN(a,b) (((a)<(b)) ? (a):(b))
using namespace std;
typedef long long LL;
namespace IO {
#include <cctype>
template <typename T>
inline void read(T &x){
x=0;
char c=0;
T w=0;
while (!isdigit(c)) w|=c=='-',c=getchar();
while (isdigit(c)) x=x*10+(c^48),c=getchar();
if(w) x=-x;
}
template <typename T>
inline void write(T x) {
if(x<0) putchar('-'),x=-x;
if(x<10) putchar(x+'0');
else write(x/10),putchar(x%10+'0');
}
template <typename T>
inline void writeln(T x) {
write(x);
putchar('\n');
}
}
const int N=1e6+5;
int n;
int a[N],b[N];
int l[2][N],r[2][N];
inline void dfs(R type,R last,R cnt) {
if(last==0) return;
if(cnt<0) exit(0);
if(type==0) {
if(l[0][last-1]<=cnt-1 && cnt-1<=r[0][last-1] && a[last-1]<=a[last]) dfs(0, last-1, cnt-1);
else dfs(1,last-1,cnt-1);
putchar('A');
} else {
if(l[0][last-1]<=cnt && cnt<=r[0][last-1] && a[last-1]<=b[last]) dfs(0,last-1,cnt);
else dfs(1,last-1,cnt);
putchar('B');
}
return;
}
int main() {
IO::read(n);
for (R i=1; i<=(n<<1); ++i) IO::read(a[i]);
for (R i=1; i<=(n<<1); ++i) IO::read(b[i]);
memset(l,0X3F,sizeof(l));
memset(r,-1,sizeof(r));
l[0][1]=r[0][1]=1;
l[1][1]=r[1][1]=0;
for(R i=2; i<=(n<<1); ++i) {
if(a[i]>=a[i-1]) l[0][i]=MIN(l[0][i],l[0][i-1]+1),r[0][i]=MAX(r[0][i], r[0][i-1]+1);
if(a[i]>=b[i-1]) l[0][i]=MIN(l[0][i],l[1][i-1]+1),r[0][i]=MAX(r[0][i],r[1][i-1]+1);
if(b[i]>=a[i-1]) l[1][i]=MIN(l[1][i],l[0][i-1]),r[1][i]=MAX(r[1][i],r[0][i-1]);
if(b[i]>=b[i-1]) l[1][i]=MIN(l[1][i],l[1][i-1]),r[1][i]=MAX(r[1][i],r[1][i-1]);
if(l[0][i]>r[0][i] && l[1][i]>r[1][i]) {
puts("-1");
return 0;
}
}
if(l[0][n<<1]<=n && n<=r[0][n<<1]) {
dfs(0,n<<1,n);
putchar('\n');
return 0;
}
if(l[1][n<<1]<=n && n<=r[1][n<<1]) {
dfs(1,n<<1,n);
putchar('\n');
return 0;
}
puts("-1");
return 0;
}
T2 hamburg
原题
CSDN下载:https://download.csdn.net/download/Ljnoit/12257726
链接
翻译
题目描述
你听说过奇异物品公司(Just Odd inventions, Ltd.)吗?这家公司以生产奇异物品出名。在本题中,我们简称它为 JOI 公司。
JOI 公司将要举办一场盛大的年会,主厨正在一块由 个网格组成的超大的网格形烤架上烤着 块汉堡肉。为了方便,我们用 表示从左往右数第 列,从下往上数第 行的网格。
我们将汉堡肉编号为 ,其中第 块汉堡覆盖了左下角 到右上角 的矩形区域,注意这些区域可能重叠。
你是 JOI 公司的萌新,现在你有 根竹签,你只要把竹签插到一个格子里就可以知道那格的肉有没有熟,你的任务是检查所有的肉是否已经煮熟。你可以把竹签插到一个没有肉的格子里,也可以把几根竹签插到同一格里。
形式化地说,你的任务是寻找一个由 个二元组 组成的 元组(其中元素可以重复),使得:
对于任意
,存在
使得
且
成立。
对于任意
,有
。
编写一个程序,给出汉堡肉覆盖的区域和竹签的数量,找出一个插竹签的方法。数据保证有解。
输入格式
第一行两个空格分隔的整数 ,含义见题面描述。
接下来 N 行每行四个空格分隔的整数 ,描述一块汉堡肉。
输出格式
输出 行,每行输出以空格分隔的两个整数 。如果有多解,输出任意一个。
样例输入 1
4 2
2 1 3 3
1 2 4 3
6 1 7 4
5 3 7 5
样例输出 1
2 2
7 4
样例解释 1
在 处插一根竹签,可以确定汉堡肉 和 的煮熟情况,在 处插一根竹签,可以确定汉堡肉 的煮熟情况。
另一种可行方案是,在 和 处分别插一根竹签。
样例输入 2
3 3
1 1 1 1
1 2 1 2
1 3 1 3
样例输出 2
1 1
1 2
1 3
数据范围与提示
对于 % 的数据,有 , , , ,且数据保证有解。
各子任务限制如下:
| 子任务编号 | 分值 | 附加限制 |
|---|---|---|
| 1 | 1 | N≤2000, K=1 |
| 2 | 1 | N≤2000, K=2 |
| 3 | 3 | N≤2000, K=3 |
| 4 | 6 | N≤2000, K=4 |
| 5 | 1 | K=1 |
| 6 | 3 | K=2 |
| 7 | 6 | K=3 |
| 8 | 79 | K=4 |
解析
本题可以随机。
每次先随机k个矩形,然后把其它矩形加入,每次选面积减小比最小的一个。
最后一个点超时,但还是100.
一般方法:
考虑算出
。
先考虑横坐标。
假设
,否则横坐标放在
的任意一个位置都行。在
这条直线的左边,至少要放一个点,因为
是一个矩形的右边界,这个矩形在
的左边。又因为这是最左的右边界,所以不如把一个点就放在
上,这样还能覆盖右边的一些矩形。
同理,对
可以得到类似的结论。
于是得到结论:
在k个点的坐标中,
都至少出现了一次。
当k<=3时,有鸽巢原理,至少有一个点的两维坐标都是
中的一个。
枚举这个点,把它覆盖的矩形去掉,递归到k−1的情况。
k=4时,先讨论以上的情况,最后的一种情况就是
围成的矩形A上,每一条边有一个点。
现在考虑其它要被覆盖的矩形B,如果一个矩形B经过了A的三条边,那一定有一条边是完全覆盖,所以矩形B一定会被覆盖不考虑。
剩下的情况就是:
- 1.B覆盖A的一个角。
- 2.B覆盖A的两条对边。
- 3.B覆盖A的一条边。
- 4.B和A无交
如果出现4说明每条边放一个(不放交点)无解。
对于一条边上的一个区间:
,建立两个点代表它选或不选,
当同一边上两个区间不交时,则只能选一个。
- 1,2相当于两个区间至少选一个
- 3相当于这个区间必须选。
用线段树可以优化到 。
代码
随机法:
#pragma GCC optimize(3,"Ofast","inline")
#pragma G++ optimize(3,"Ofast","inline")
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <ctime>
#include <algorithm>
#define R register int
#define re(i,a,b) for(R i=a; i<=b; i++)
#define ms(i,a) memset(a,i,sizeof(a))
#define MAX(a,b) (((a)>(b)) ? (a):(b))
#define MIN(a,b) (((a)<(b)) ? (a):(b))
using namespace std;
typedef long long LL;
namespace IO {
#include <cctype>
char buf[1<<20],*p1,*p2;
#define gc() (p1 == p2 && (p2 = (p1 = buf) + fread(buf,1,1<<20,stdin), p1 == p2) ? 0 : *p1++)
template <typename T>
inline void read(T &x){
x=0;
char c=0;
T w=0;
while (!isdigit(c)) w|=c=='-',c=gc();
while (isdigit(c)) x=(x<<3)+(x<<1)+(c^48),c=gc();
if(w) x=-x;
}
template <typename T>
inline void write(T x) {
if(x<0) putchar('-'),x=-x;
if(x<10) putchar(x+'0');
else write(x/10),putchar(x%10+'0');
}
template <typename T>
inline void writeln(T x) {
write(x);
putchar('\n');
}
}
const int N=2e5+5;
const int inf=1e9;
struct node {
LL l,r,d,u;
} a[N],ans[10];
node merge(node x,node y) {
return (node){MAX(x.l,y.l),MIN(x.r,y.r),MAX(x.d,y.d),MIN(x.u,y.u)};
}
double check(node x) {
if(x.l<=x.r && x.d<=x.u) return (x.r-x.l)*(x.u-x.d);
else return -1;
}
int n,K;
int main() {
srand(time(0));
IO::read(n);
IO::read(K);
for(R i=1; i<=n; ++i) {
IO::read(a[i].l);
IO::read(a[i].d);
IO::read(a[i].r);
IO::read(a[i].u);
}
LL flag=0;
while(!flag) {
for(R i=1; i<=K; ++i) ans[i]=(node){1,inf,1,inf};
random_shuffle(a+1,a+1+n);
LL cnt=0;
for(R i=1; i<=n; ++i) {
double mxsz=-1;
R u=-1;
for(R j=1; j<=K; ++j)
if(check(merge(a[i],ans[j]))/check(ans[j])>mxsz) {
mxsz=check(merge(a[i],ans[j]))/check(ans[j]);
u=j;
}
if(mxsz>=0) {
cnt++;
ans[u]=merge(a[i],ans[u]);
}
if(cnt!=i) break;
}
if(cnt==n) flag=1;
}
for(R i=1; i<=K; ++i) {
IO::write(ans[i].l);
putchar(' ');
IO::writeln(ans[i].d);
}
return 0;
}
一般方法:
#pragma GCC optimize(3,"Ofast","inline")
#pragma G++ optimize(3,"Ofast","inline")
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <ctime>
#include <algorithm>
#include <random>
#include <cassert>
#define RI register int
#define re(i,a,b) for(RI i=a; i<=b; i++)
#define ms(i,a) memset(a,i,sizeof(a))
#define MAX(a,b) (((a)>(b)) ? (a):(b))
#define MIN(a,b) (((a)<(b)) ? (a):(b))
#define pb push_back
#define mk make_pair
#define fi first
#define se second
using namespace std;
typedef long long LL;
typedef unsigned long long ULL;
typedef pair<int,int> PII;
namespace IO {
#include <cctype>
template <typename T>
inline void read(T &x){
x=0;
char c=0;
T w=0;
while (!isdigit(c)) w|=c=='-',c=getchar();
while (isdigit(c)) x=x*10+(c^48),c=getchar();
if(w) x=-x;
}
template <typename T>
inline void write(T x) {
if(x<0) putchar('-'),x=-x;
if(x<10) putchar(x+'0');
else write(x/10),putchar(x%10+'0');
}
template <typename T>
inline void writeln(T x) {
write(x);
putchar('\n');
}
}
using IO::read;
using IO::write;
using IO::writeln;
const int MAXN=2e5+5;
const int inf=1e9;
int n,K;
PII p[5];
struct steak {
int l,r,d,u;
bool contain(PII p) {
return l<=p.fi && p.fi<=r && d<=p.se && p.se<=u;
}
void input() {
read(l),read(d),read(r),read(u);
}
} a[5][MAXN];
int del(steak _old[MAXN],steak _new[MAXN],int oldn,PII p) {
int newn=0;
for(int i=1; i<=oldn; ++i)
if(!_old[i].contain(p))
_new[++newn]=_old[i];
return newn;
}
void dfs(int k,int n) {
int L=0,R=inf+1,D=0,U=inf+1;
for(int i=1;i<=n;++i) {
L=MAX(L,a[k][i].l);
R=MIN(R,a[k][i].r);
D=MAX(D,a[k][i].d);
U=MIN(U,a[k][i].u);
}
if(L<=R && D<=U) {
for(int i=1; i<k; ++i) puts("114 514");
write(L); putchar(' '); writeln(D);
for(int i=k+1; i<=K; ++i) {
write(p[i].fi); putchar(' '); writeln(p[i].se);
}
exit(0);
}
if(k==1) return;
int newn;
newn=del(a[k],a[k-1],n,p[k]=mk(L,D)); dfs(k-1,newn);
newn=del(a[k],a[k-1],n,p[k]=mk(L,U)); dfs(k-1,newn);
newn=del(a[k],a[k-1],n,p[k]=mk(R,D)); dfs(k-1,newn);
newn=del(a[k],a[k-1],n,p[k]=mk(R,U)); dfs(k-1,newn);
}
int main() {
read(n);
read(K);
for(int i=1; i<=n; ++i) a[K][i].input();
dfs(K,n);
assert(K==4);
srand((ULL)time(0)^(ULL)(new char));
while(1) {
#define a a[K]
int L=0,R=inf+1,D=0,U=inf+1;
int Lx=0,Rx=0,Dx=0,Ux=0;
for(int i=1; i<=n; ++i) {
if(a[i].l>L) L=a[i].l,Lx=i;
if(a[i].r<R) R=a[i].r,Rx=i;
if(a[i].d>D) D=a[i].d,Dx=i;
if(a[i].u<U) U=a[i].u,Ux=i;
}
int Ld=a[Lx].d,Lu=a[Lx].u;
int Rd=a[Rx].d,Ru=a[Rx].u;
int Dl=a[Dx].l,Dr=a[Dx].r;
int Ul=a[Ux].l,Ur=a[Ux].r;
bool ok=1;
for(int i=1; i<=n; ++i) {
if(a[i].l<=L && a[i].r>=L && a[i].d<=Ld && a[i].u>=Lu) continue;
if(a[i].l<=R && a[i].r>=R && a[i].d<=Rd && a[i].u>=Ru) continue;
if(a[i].d<=D && a[i].u>=D && a[i].l<=Dl && a[i].r>=Dr) continue;
if(a[i].d<=U && a[i].u>=U && a[i].l<=Ul && a[i].r>=Ur) continue;
bool flag=0;
static int order[4];
for(int j=0; j<4; ++j) order[j]=j;
random_shuffle(order,order+4);
for(int j=0; j<4; ++j) {
if(order[j]==0) {
if(a[i].l<=L && a[i].r>=L && MAX(a[i].d,Ld)<=MIN(a[i].u,Lu)){
Ld=MAX(a[i].d,Ld);
Lu=MIN(a[i].u,Lu);
flag=1;
break;
}
} else if(order[j]==1) {
if(a[i].l<=R && a[i].r>=R && MAX(a[i].d,Rd)<=MIN(a[i].u,Ru)) {
Rd=MAX(a[i].d,Rd);
Ru=MIN(a[i].u,Ru);
flag=1;
break;
}
} else if(order[j]==2) {
if(a[i].d<=D && a[i].u>=D && MAX(a[i].l,Dl)<=MIN(a[i].r,Dr)) {
Dl=MAX(a[i].l,Dl);
Dr=MIN(a[i].r,Dr);
flag=1;
break;
}
} else {
if(a[i].d<=U && a[i].u>=U && MAX(a[i].l,Ul)<=MIN(a[i].r,Ur)) {
Ul=MAX(a[i].l,Ul);
Ur=MIN(a[i].r,Ur);
flag=1;
break;
}
}
}
if(!flag) {
ok=0;
break;
}
}
if(ok) {
write(L); putchar(' '); writeln(Ld);
write(R); putchar(' '); writeln(Rd);
write(Dl); putchar(' '); writeln(D);
write(Ul); putchar(' '); writeln(U);
exit(0);
}
#undef a
}
return 0;
}
T3 sweeping
原题
CSDN下载:https://download.csdn.net/download/Ljnoit/12257726
链接
翻译
题目描述
Bitaro 的房间是一个边长为 的等腰直角三角形。房间内一点用坐标 表示,其中 。直角顶点为原点,三角形两腰分别为 轴与 轴。
一天,Bitaro 注意到他的房间满是灰尘。初始时,房间内有
堆灰尘。第
堆灰尘位于点
。在同一点可能有多堆灰尘。
现在,Bitaro 打算用扫帚打扫房间。我们认为扫帚是在房间里的一条线段,并且称线段的长度为扫帚的宽度。因为 Bitaro 做事很有条理,他只能按如下两种方式使用扫帚:
- Bitaro 将扫帚放在房间里,使得扫帚的一个端点位于原点,并且扫帚平行于 轴。然后,他会沿 轴正方向水平移动扫帚,直到不能移动为止。在移动过程中,他会保证扫帚始终与 轴平行,并且一个端点始终在 轴上。如果扫帚宽度为 ,则在 位置的灰尘 将会移动到 (在 处可能存在其他堆灰尘)。这个过程称为过程 。
- Bitaro 将扫帚放在房间里,使得扫帚的一个端点位于原点,并且扫帚平行于 轴。然后,他会沿 轴正方向水平移动扫帚,直到不能移动为止。在移动过程中,他会保证扫帚始终与 轴平行,并且一个端点始终在 轴上。如果扫帚宽度为 l,则在 位置的灰尘 将会移动到 (在 处可能存在其他堆灰尘)。这个过程称为过程 。
在 Bitaro 的房间里,会按顺序发生 个事件。第 个事件是以下事件中的一个:
- Bitaro 计算第 堆灰尘的位置坐标;
- Bitaro 使用宽度为 的扫帚,进行了过程 H;
- Bitaro 使用宽度为 的扫帚,进行了过程 V;
- 一堆新灰尘出现在点 处。如果在这个事件之前一共有 堆灰尘,那么这堆灰尘就是房间中的第 堆灰尘。
写一个程序,给出房间的腰长,每一堆灰尘的位置坐标和每个事件的细节,求出要求的某堆灰尘的位置坐标。
输入格式
从标准输入读入以下数据,所有输入的值均为整数。
第一行三个整数,分别为
。
接下来
行,每行两个整数
,表示第
堆灰尘的初始坐标。
接下来
行,每行表示一个事件,有两或三个整数。设
为第一个整数,每行含义如下:
- 如果 ,则这行有两个整数 。表示 Bitaro 要计算第 Pj 堆灰尘的坐标;
- 如果 ,则这行有两个整数 。表示 Bitaro 用宽度为 Lj 的扫帚进行了过程 ;
- 如果 ,则这行有两个整数 。表示 Bitaro 用宽度为 Lj 的扫帚进行了过程 ;
- 如果 ,则这行有三个整数 。表示一堆新的灰尘出现在 位置。
输出格式
对于每个 的事件,输出一行两个整数到标准输出。输出在事件 发生时第 堆灰尘的位置坐标。
样例输入 1
6 2 10
1 1
4 0
4 2 3
3 3
1 1
4 1 2
2 3
2 0
1 4
3 2
1 3
1 2
样例输出 1
1 3
3 2
3 3
6 0
样例说明 1
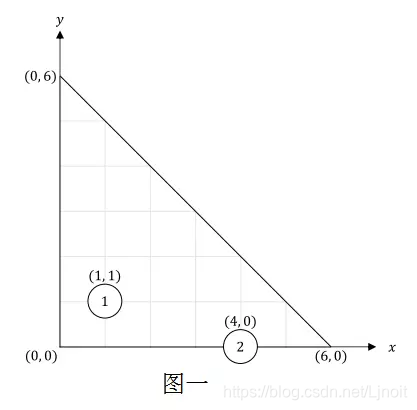
初始时,第一堆灰尘位于 (1,1),第二堆灰尘位于 (4,0)。图一描述了房间现在的情况。
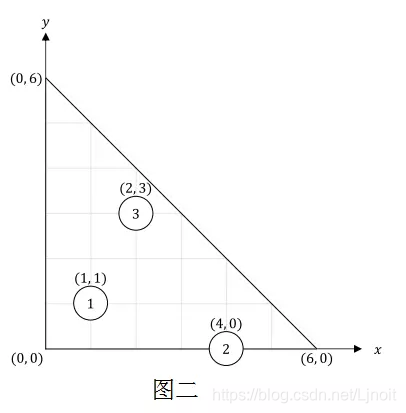
对于第一个事件,第三堆灰尘添加到点 (2,3) 的位置。图二描述了房间现在的情况。
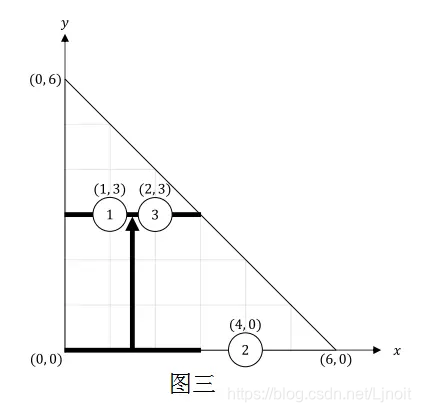
对于第二个事件,Bitaro 用宽度为 3 的扫帚进行了过程 V。之后,第一堆灰尘移动到了 (1,3),图三描述了房间现在的情况。
对于第三个事件,Bitaro 计算了第一堆灰尘的坐标 (1,3)。
对于第四个事件,第四堆灰尘添加到点 (1,2) 的位置。图四描述了房间现在的情况。
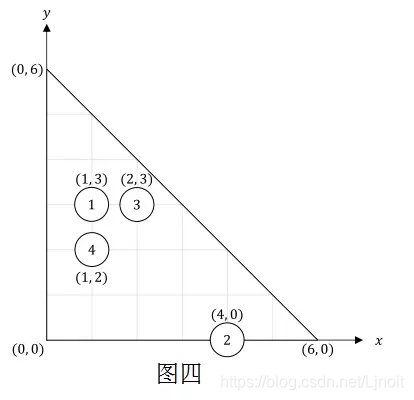
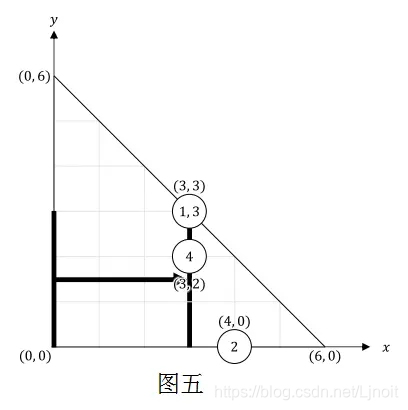
对于第五个事件,Bitaro 用宽度为 3 的扫帚进行了过程 H。之后,第一堆灰尘移到了 (3,3),第三堆灰尘移到了 (3,3),第四堆灰尘移到了 (3,2)。图五描述了房间现在的情况。
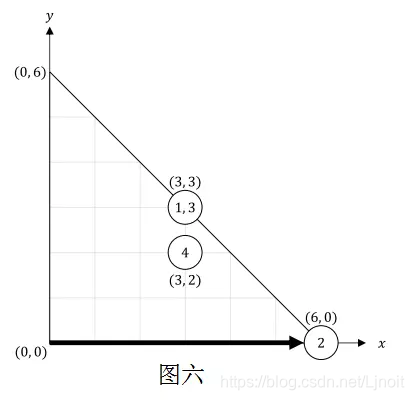
对于第六个事件,Bitaro 用宽度为 0 的扫帚进行了过程 H。之后,第二堆灰尘移到了 (6,0)。图六描述了房间现在的情况。
对于第七个事件,Bitaro 计算了第四堆灰尘的坐标 (3,2)。
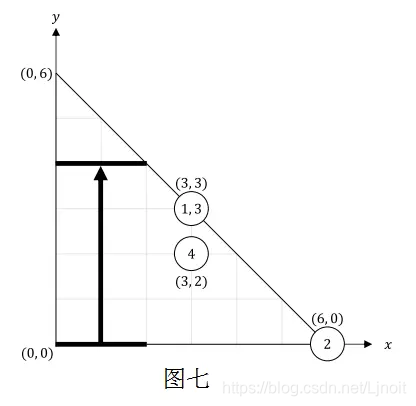
对于第八个事件,Bitaro 用宽度为 2 的扫帚进行了过程 V。没有任何灰尘堆移动。图七描述了房间现在的情况。
对于第九个事件,Bitaro 计算了第三堆灰尘的坐标 (3,3)。
对于第十个事件,Bitaro 计算了第二堆灰尘的坐标 (6,0)。
这组样例满足子任务 1 和子任务 5 的限制。
样例输入 2
9 4 8
2 3
3 1
1 6
4 3
2 6
1 3
2 2
1 4
2 3
1 2
2 4
1 1
样例输出 2
3 6
4 3
7 1
6 3
样例说明 2
这组样例满足子任务 1, 2, 4, 5 的限制。
样例输入 3
8 1 8
1 5
4 4 1
2 6
1 2
2 3
4 2 2
2 5
1 1
1 3
样例输出 3
4 1
3 5
3 2
样例说明 3
这组样例满足子任务 1, 2, 5 的限制。
样例输入 4
7 4 9
1 5
2 2
4 2
5 0
2 6
2 3
1 2
3 6
1 4
3 1
1 1
2 2
1 3
样例输出 4
4 2
5 1
1 6
5 2
样例说明 4
这组样例满足子任务 1, 3, 4, 5 的限制。
样例输入 5
20 5 25
10 6
0 4
2 1
1 0
2 3
2 18
3 9
4 1 5
4 0 2
3 10
4 3 3
3 3
2 9
4 9 1
3 12
1 4
3 19
1 3
1 9
2 1
1 7
1 6
4 3 3
1 10
1 1
1 5
2 0
1 2
2 2
1 7
样例输出 5
2 17
2 17
9 8
0 17
1 17
3 3
10 10
2 17
2 17
0 17
样例说明 5
这组样例满足子任务 1 和子任务 5 的限制。
数据范围与提示
对于全部数据, 。保证:
,其中
表示当事件
发生时灰尘的堆数;
存在至少一个事件
。
详细子任务与附加限制如下表:
| 子任务 | 附加限制 | 分值 |
|---|---|---|
| 1 | 1 | |
| 2 | T_j=1,2,4 | 10 |
| 3 | 11 | |
| 4 | 53 | |
| 5 | 无附加限制 | 25 |
解析
线段树分治+平衡树。
对于一开始y随x递增而不递增的部分分,每次修改的都是一段区间。用线段树(平衡树)维护,每次二分出修改的区间,然后区间赋值即可。对于没有4操作的部分,被移动过至少一次点,它们之间满足y随x递增而不递增。所以先对每个点求出第一次移动的时间(二维排序问题),或者平衡树在线维护什么时候移动。在点第一次移动时,丢入一棵维护已经移动过点的平衡树,那棵平衡树做前面说的操作。有4操作时,发现主要是因为新加入的点没有经过前面修改的洗礼,所以不满足那个性质了。对于每个询问,相当于求一个点经过一个区间的操作后的结果。利用线段树分治,把这个区间分成线段树上的log个区间。这样的话,对于线段树上的一个区间,上面的询问都要经过这个区间的修改,就可以当没有4操作那么做了。
时间复杂度:
代码
#pragma GCC optimize(3,"Ofast","inline")
#pragma G++ optimize(3,"Ofast","inline")
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <ctime>
#include <algorithm>
#include <random>
#include <tuple>
#define R register int
#define re(i,a,b) for(R i=a; i<=b; i++)
#define ms(i,a) memset(a,i,sizeof(a))
#define MAX(a,b) (((a)>(b)) ? (a):(b))
#define MIN(a,b) (((a)<(b)) ? (a):(b))
using namespace std;
typedef long long LL;
namespace IO {
#include <cctype>
char buf[1<<20],*p1,*p2;
#define gc() (p1 == p2 && (p2 = (p1 = buf) + fread(buf,1,1<<20,stdin), p1 == p2) ? 0 : *p1++)
template <typename T>
inline void read(T &x){
x=0;
char c=0;
T w=0;
while (!isdigit(c)) w|=c=='-',c=gc();
while (isdigit(c)) x=(x<<3)+(x<<1)+(c^48),c=gc();
if(w) x=-x;
}
template <typename T>
inline void write(T x) {
if(x<0) putchar('-'),x=-x;
if(x<10) putchar(x+'0');
else write(x/10),putchar(x%10+'0');
}
template <typename T>
inline void writeln(T x) {
write(x);
putchar('\n');
}
}
const int N=15e5+5;
const int inf=1e9;
mt19937 gen(1145141);
int n,m,clk;
pair<int,int> pts[N],ans[N];
int qt[N],qc[N],tag[N],del[N];
pair<pair<int,int>,int> tp[N];
namespace SegTree {
pair<int,int> tr[N * 4];
void build(int i,int l,int r) {
if(l==r) {
tr[i]=make_pair(tp[l].second,l);
return;
}
int mid=(l+r)>>1;
build(i<<1,l,mid);
build(i<<1|1,mid+1,r);
tr[i]=(pts[tr[i<<1].first].second < pts[tr[i<<1|1].first].second ? tr[i<<1] : tr[i<<1|1]);
}
pair<int,int> query(int i,int l,int r,int lf,int rg) {
if(lf<=l && r<=rg) return tr[i];
int mid=(l+r)>>1;
if(rg<=mid) return query(i<<1,l,mid,lf,rg);
else if(lf>mid) return query(i<<1|1,mid+1,r,lf,rg);
pair<int,int> r1=query(i<<1,l,mid,lf,rg),r2=query(i<<1|1,mid+1,r,lf,rg);
return ((pts[r1.first].second < pts[r2.first].second) ? r1 : r2);
}
void update(int i,int l,int r,int pos) {
if(l==r) {
tr[i].first = 0;
return;
}
int mid=(l+r)>>1;
if (pos<=mid) update(i<<1,l,mid,pos);
else update(i<<1|1,mid+1,r,pos);
tr[i]=(pts[tr[i<<1].first].second < pts[tr[i<<1|1].first].second ? tr[i<<1] : tr[i<<1|1]);
}
}
namespace Treap {
struct Node {
int lson,rson,par,rnd,x,y,tagx,tagy;
inline void upd(int tx,int ty) {
x=MAX(x,tx);
tagx=MAX(tagx,tx);
y=MAX(y,ty);
tagy=MAX(tagy,ty);
}
inline void pushdown();
} tr[N];
int tot,root;
inline void Init() {
tot=root=0;
tr[0].lson=tr[0].rson=tr[0].par=tr[0].rnd=tr[0].x=tr[0].y=tr[0].tagx=tr[0].tagy=0;
}
inline int NewNode(int x,int y) {
int p=++tot;
tr[p].lson=tr[p].rson=tr[p].par=tr[p].tagx=tr[p].tagy=0;
tr[p].rnd=gen();
tr[p].x=x,tr[p].y=y;
return p;
}
inline void Node::pushdown() {
if(tagx || tagy) {
if(lson) tr[lson].upd(tagx, tagy);
if(rson) tr[rson].upd(tagx, tagy);
tagx=tagy=0;
}
}
inline pair<int,int> Split_y(int p,int y) {
if(!p) return make_pair(0, 0);
tr[p].pushdown();
if(tr[p].y<=y) {
pair<int,int> q=Split_y(tr[p].lson,y);
tr[p].lson=q.second;
if(tr[p].lson) tr[tr[p].lson].par=p;
q.second=p;
tr[p].par=0;
return q;
} else {
pair<int,int> q=Split_y(tr[p].rson,y);
tr[p].rson=q.first;
if(tr[p].rson) tr[tr[p].rson].par=p;
q.first=p;
tr[p].par=0;
return q;
}
}
inline pair<int,int> Split_x(int p,int x) {
if(!p) return make_pair(0, 0);
tr[p].pushdown();
if(tr[p].x>x) {
pair<int,int> q=Split_x(tr[p].lson,x);
tr[p].lson=q.second;
if (tr[p].lson) tr[tr[p].lson].par=p;
q.second=p;
tr[p].par=0;
return q;
} else {
pair<int,int> q=Split_x(tr[p].rson,x);
tr[p].rson=q.first;
if(tr[p].rson) tr[tr[p].rson].par=p;
q.first=p;
tr[p].par=0;
return q;
}
}
int Merge(int p1,int p2) {
if(!p1 || !p2) return p1|p2;
if(tr[p1].rnd<tr[p2].rnd) {
tr[p1].pushdown();
tr[p1].rson = Merge(tr[p1].rson,p2);
if(tr[p1].rson) tr[tr[p1].rson].par=p1;
return p1;
} else {
tr[p2].pushdown();
tr[p2].lson=Merge(p1,tr[p2].lson);
if(tr[p2].lson) tr[tr[p2].lson].par=p2;
return p2;
}
}
int Insert(int x,int y) {
int p=NewNode(x, y);
int a,b,c;
tie(b,c)=Split_x(root,x);
tie(a,b)=Split_y(b,y-1);
root=Merge(Merge(a,p),Merge(b,c));
return p;
}
inline pair<int,int> query(int p) {
int x=tr[p].x,y=tr[p].y;
while(p) {
x=MAX(x,tr[p].tagx);
y=MAX(y,tr[p].tagy);
p=tr[p].par;
}
return make_pair(x,y);
}
}
int nid[N];
void solve(int l,int r) {
if(l==r) return;
int mid=(l+r)>>1;
solve(l,mid);
solve(mid+1,r);
int tot=0;
clk++;
for(int i=l; i<=mid; i++) {
if(qt[i]==4) {
tp[++tot]=make_pair(pts[qc[i]],qc[i]);
tag[qc[i]]=clk;
del[qc[i]]=0;
}
}
if(!tot) return;
sort(tp+1,tp+1+tot);
SegTree::build(1,1,tot);
Treap::Init();
for(int i=mid+1; i<=r; i++) {
if(qt[i]==4 || (qt[i]==1 && tag[qc[i]]!=clk)) continue;
if(qt[i]==1) {
ans[i]=(del[qc[i]] ? Treap::query(nid[qc[i]]) : pts[qc[i]]);
} else if(qt[i]==2) {
int p,q;
tie(p,q)=Treap::Split_y(Treap::root,qc[i]);
if(q) Treap::tr[q].upd(n-qc[i],0);
Treap::root=Treap::Merge(p,q);
int xr=lower_bound(tp+1,tp+1+tot,make_pair(make_pair(n-qc[i],n+5),0))-tp-1;
if(!xr) continue;
pair<int,int> pr;
while(true) {
pr=SegTree::query(1,1,tot,1,xr);
if(pts[pr.first].second>qc[i]) break;
nid[pr.first]=Treap::Insert(n-qc[i],pts[pr.first].second);
del[pr.first]=1;
SegTree::update(1,1,tot,pr.second);
}
} else if(qt[i]==3) {
int p,q;
tie(p,q)=Treap::Split_x(Treap::root,qc[i]);
if(p) Treap::tr[p].upd(0,n-qc[i]);
Treap::root=Treap::Merge(p, q);
int xr=lower_bound(tp+1,tp+1+tot,make_pair(make_pair(qc[i],n+5),0))-tp-1;
if(!xr) continue;
pair<int,int> pr;
while(1) {
pr=SegTree::query(1,1,tot,1,xr);
if(pts[pr.first].second > n-qc[i]) break;
nid[pr.first]=Treap::Insert(pts[pr.first].first,n-qc[i]);
del[pr.first]=1;
SegTree::update(1,1,tot,pr.second);
}
}
}
for(int i=l; i<=mid; i++) {
if(qt[i]==4 && del[qc[i]]) {
pts[qc[i]]=Treap::query(nid[qc[i]]);
}
}
}
int main() {
int q,cnt;
IO::read(n);
IO::read(m);
IO::read(q);
for (int i = 1; i <= m; i++) {
IO::read(pts[i].first);
IO::read(pts[i].second);
qt[i]=4;
qc[i]=i;
}
cnt=m;
for(int i=m+1; i<=m+q; i++) {
IO::read(qt[i]);
if (qt[i]<=3) IO::read(qc[i]);
else {
qc[i] = ++cnt;
IO::read(pts[cnt].first);
IO::read(pts[cnt].second);
}
}
m+=q;
clk=0;
pts[0].second=n+5;
solve(1,m);
for(int i=1; i<=m; i++) {
if(qt[i]==1) printf("%d %d\n", ans[i].first,ans[i].second);
}
return 0;
}
