如何用Python编写网络爬虫?
python提供了很方便的库来帮助我们实现很多复杂的功能。在编写网络爬虫的过程中,我们可以使用requests来与网站交互并获取网页的源代码,再使用beautifulsoup4对得到的网站源代码(通常是html)进行处理来获取所需要的内容。下面进行详细的介绍。
关于网页的基础知识
url(Uniform Resource Locator)也就是我们平时所说的域名,也就是网址。当用户在浏览器中输入网址后,浏览器会先访问本地的hosts文件来寻找是否存在匹配的IP地址,如果没有找到则再通过DNS服务器去获得正确的IP地址进行访问。例如域名www.baidu.com的IP地址为14.215.177.39。
对于一个网页,在浏览器上右键->查看源代码即可查看该网页的实现。网页的源代码大多都是以<p attribute>text</p>的html格式,其中成对的p称为标签, 标签后面的键值对称为属性, 标签对之间的部分称为正文。不同的标签显示出来的功能和效果截然不同。我们需要做的就是在这些标签里获取我们需要的信息。
给服务器传送数据有多种方式。
1.最简单的就是get方式,在域名后面加上?attr : a=a1&b=b1...x=x1,相当于一个{a:a1,b:b1,c:c1...x:x1}的参数表。
2.稍复杂一些的是post方式传值,像密码这样的需要藏起来的数据自然不能采用明文的get,还有像填一些表格,数据量比较大的也往往采用post方式传值。
关于requests库
requests库可用于访问网页,上传数据等操作。
http://docs.python-requests.org/en/master/
这是requests库的文档,写的很详细。这里我们就简要介绍一些常见的简单用法。
r = request.get(url)
这样我们就有了一个名为r的 Response对象,通过r.text就可以查看url网页的源代码。
最简单爬虫直接对r.text进行处理就可以获得我们想要的内容。处理的方式有很多种,最简洁的处理方式是采用正则表达式处理,(关于正则表达式的更多内容可以看我之前的博客)比如说我们需要爬取图片,而源代码中图片的url以
"ObjURL":"http:\/\/img3.imgtn.bdimg.com\/it\/u=560465708,1507159867&fm=214&gp=0.jpg"形式出现,那我们可以采用for x in re.findall(pt , r.text)的方式遍历所需要的图片的url。
其中pt是可与上面html匹配的正则表达式,例如pt = '\"objURL\":\"((http://|https://)[^\"]*)\"'。
session_requests = requests.session()
在requests中我们就可以通过session来实现这一功能,封装好的session模块很好用也很方便。
比如类似以下代码,就可以向服务器发送post请求,其中data就是我们需要传送的数据。
result = session_requests.post( # 向服务器发送post请求
url,
data=mylog,
headers=dict(referer=url),
)
假设某个网站需要登陆操作,那么怎么爬取登陆过后网页的信息呢?我们就可以使用session模块的post方法,现在问题来了,我们在登陆页面输入了用户名和密码,点击登陆后到底传输了哪些数据呢?只有知道了数据的格式,我们才能进行模拟传输。
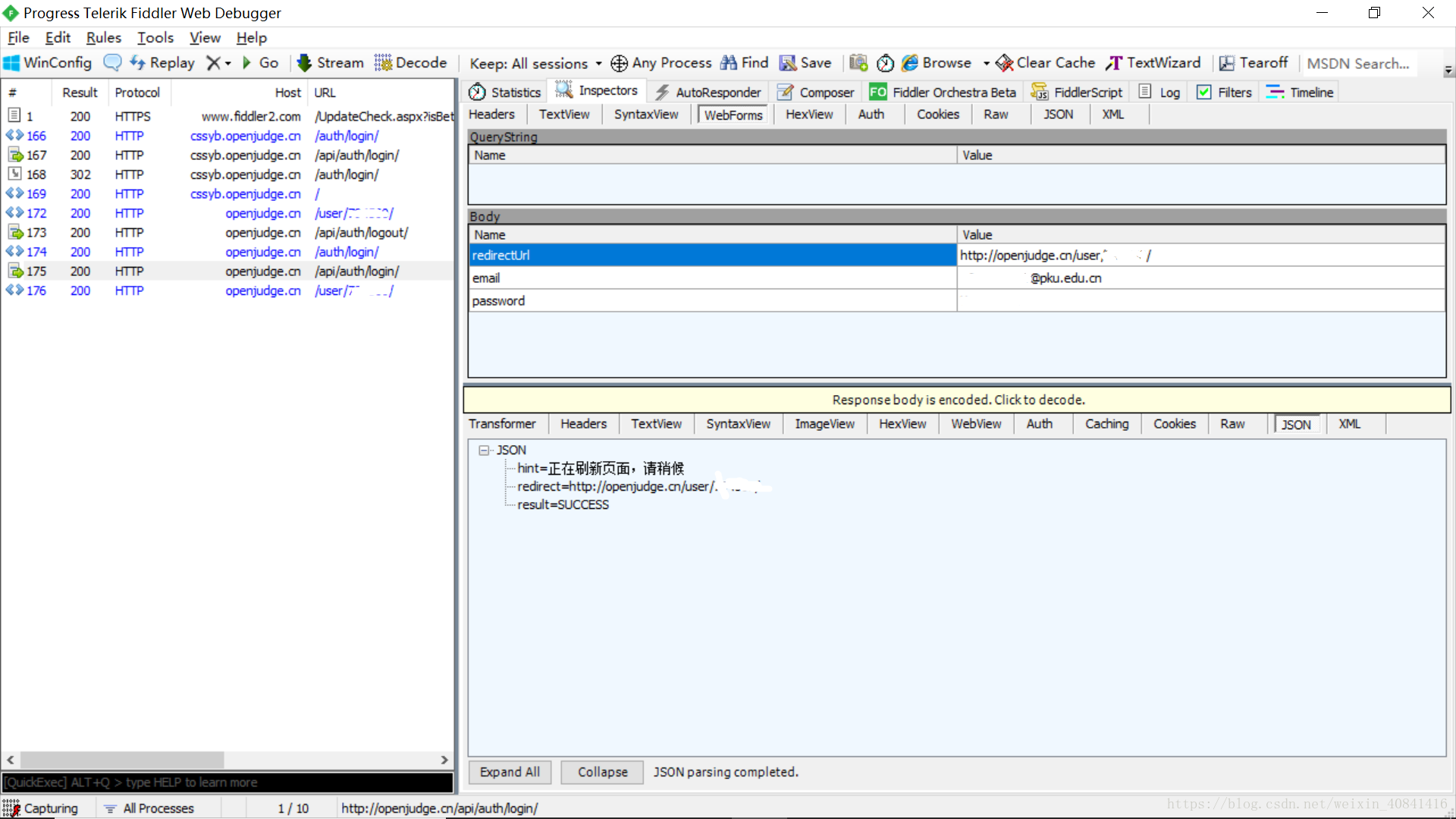
我们可以通过下载一个叫Fiddle4的免费软件来实现,Fiddle4会截取浏览器post的内容,因此我们通过这种方式查看login所使用的url和data。
以openjudge为例,当我们login后,在Fiddle4中可以发现data就是
mylog = {"redirectUrl": "http://openjudge.cn/",
"password": "",
"email": ""}的格式。
关于beautifulsoup4库
请查看官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html好好看看findall就够用了,find的使用和findall几乎相同。参数有多种写法,甚至可以带判别函数和正则表达式的形式,强烈建议看文档!
for tag in find_all( name , attrs , recursive , text , **kwargs )
返回值是beautifulsoup的类的列表。
它可以通过tag["attr"]来访问和修改属性(类似python里的dict),可以通过tag.text访问正文。如果没有符合要求的tag则返回空列表。
find的参数表与findall相同,只是返回值是一个单独的beautifulsoup类或者None
有时间再更...
以下是用python实现的登陆openjudge,并且爬取accept代码的程序
import requests
import bs4
import re
code_class = {"sh_cpp": ".cpp",
"sh_c": ".c", "": ".py",
"sh_pascal": ".pas",
"sh_java": ".java"}
mylog = {"redirectUrl": "http://openjudge.cn/",
"password": "",
"email": ""}
session_requests = requests.session()
own_url = "http://openjudge.cn/"
#爬取个人主页url下accept的内容,若有next page则继续爬取
def download_url(url):
global session_requests
global own_url
global code_class
ans = session_requests.get(url)
s = str(ans.content, encoding="utf-8")
soup = bs4.BeautifulSoup(s, "html.parser")
blocks = soup.find_all("a", class_="result-right")
#blocks包含accept代码网页的信息,遍历该页
if blocks != []:
for i in blocks:
solution_url = i["href"]
solution = session_requests.get(solution_url)
ss = str(solution.content, encoding="utf-8")
s_soup = bs4.BeautifulSoup(ss, "html.parser")
#判断该题的代码类型
for class_name in code_class:
block = s_soup.find("pre", class_=class_name)
if block == None:
continue
try:
name = s_soup.find_all("h3")[1]
name = name.text[:-5]
except:
print("Get name wrong!")
#去掉第一个':'前面的编号
index = name.find(':')
if (index != -1):
name = name[index + 1:]
#去除题名中的非法字符和开头结尾的空格
name = re.sub(r"[\\/:*?#\"<>|:]", " ", name).strip()
try:
#已存在同名代码
f = open("C:/tmp/" + name + code_class[class_name])
print(name + " has already downloaded")
continue
except IOError:
#不存在同名代码
print("downloading your correct code " + name)
try:
f = open("C:/tmp/" + name + code_class[class_name], 'w', encoding = "utf-8")
new_str = block.text
f.write(new_str)
f.close()
except Exception as e:
print(name + " can't be downloaded correctly")
print(e)
# next 是下一页的相对路径
next = soup.find("a", class_="nextprev", rel="next")
if next != None:
download_url(own_url + next["href"])
def spider():
global code_class
global mylog, session_requests, own_url
mylog["email"] = input("请输入您登陆openjudge使用的email账号:\n")
mylog["password"] = input("请输入您的密码:\n")
login_url = "http://openjudge.cn/api/auth/login/"
result = session_requests.post( # 向服务器发送post请求
login_url,
data=mylog,
headers=dict(referer=login_url),
)
result = session_requests.get("http://openjudge.cn/")
#用正则表达式匹配寻找个人首页的url
pt = r"<a href=\"(http://[^\"]*)\">个人首页</a>"
try:
own_url = re.search(pt, result.text).group(1)
print("这是您的主页:" + own_url)
except:
print("账号不存在或密码错误!请重新输入!")
spider()
return
own_url = ''
download_url(own_url)
print("您已成功下载所有accept的程序至c:\\tmp文件夹下!")
spider()