11.1 子集搜索与评价
特征选择:从给定的特征集中选择出相关特征子集的过程。特征选择过程必须确保不丢失重要特征。
处理高维数据两大主流技术:降维,特征选择
无关特征:与当前学习任务无关
冗余特征:它们所包含的特征能从其他特征中推演出来。有时候不起作用,去除减轻学习负担;有时候会降低学习任务的难度。若某冗余特征恰好对应了完成学习任务所需的“中间概念”,则该冗余特征是有益的
子集搜索:如何根据评价结果获取下一个候选特征集
前向搜索:逐渐增加相关特征的策略
后向搜索:从完整的特征集合开始,每次尝试去掉一个无关特征,逐渐减少特征
双向搜索:前向与后向搜索结合,每一轮逐渐增加相关特征(这些特征在后续轮中将确定不会被去除)同时减少无关特征
子集评价:如何评价候选特征集的好坏
一般的,特征子集A实际上确定了对数据集D的一个划分,每个划分域对应着A的一个取值,而样本标记信Y则对应着D的真实划分,通过估算这两个划分的差异,就能对A进行评价。与Y对应的划分的差异越小,则说明A越好。
特征选择方法:过滤式、包裹式、嵌入式
11.2 过滤式选择
先对数据集进行特征选择,然后再训练学习,特征选择过程与后续学习器无关。
Relief:“相关统计量”来度量特征的重要性。
给定训练集![]()
在![]() 的同类样本中找到最近邻
的同类样本中找到最近邻![]() ,称为“猜中近邻”,再从
,称为“猜中近邻”,再从![]() 的一类样本中找到最近邻
的一类样本中找到最近邻![]() ,称为“猜错近邻”;相关统计量对应于属性j的分量为:
,称为“猜错近邻”;相关统计量对应于属性j的分量为:
![]()
多分类问题扩展,Pl为l类样本在数据集D中所占比例
![]()
11.3 包裹式选择
包裹式特征选择直接把最终将要使用的学习器的性能作为特征子集的评价标准,“量身定做”特征子集
LVW算法描述

11.4 嵌入式选择与L1正则化
LASSO:
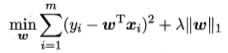
L1范数和L2范数正则化都有助于降低过拟合风险
L1范数更容易获得稀疏解,求得的W会有更少的非零向量

L1取得稀疏解意味着初始的d个特征中仅有对应着w的非零分量的特征才会出现在最终模型,于是,求解L1范数正则化的结果是得到了仅采用一部分初始特征的模型,即嵌入式特征选择方法
11.5 稀疏表示与字典学习
特征选择考虑的问题是特征具有稀疏性,即矩阵中的许多列与当前学习任务无关
另一种稀疏性:D所对应的矩阵存在很多零元素,但这些零元素并不是以整列、整行的形式存在。当样本具有这样的稀疏表达形式时,对学习任务来说会有不少好处,例如,支持向量机之所以能在文本数据上有很好的性能恰是由于文本数据在使用上述字频表示时具有高度的稀疏性,使大多数问题变得线性可分,同时稀疏矩阵不会造成存储上的巨大负担。
字典学习:为普通稠密表达的样本找到合适的字典,将样本转换为合适的稀疏表示形式,从而使学习任务得以简化,模型复杂度得以降低,通常称为“字典学习”,亦称“稀疏编码”。
字典学习最简答的形式为:

![]() 是
是![]() 的稀疏表示,B是字典矩阵,第一项希望
的稀疏表示,B是字典矩阵,第一项希望 ![]() 能很好的重构
能很好的重构![]() ,第二项希望
,第二项希望 ![]() 尽量稀疏
尽量稀疏
11.6 压缩感知
奈奎斯特采样定理:令采样频率达到模拟信号最高频率的两倍,则采样后的数字信号就保留了模拟信号的全部信息
