【机器学习】《机器学习》周志华西瓜书 笔记/习题答案 总目录
——————————————————————————————————————————————————————
特征选择与稀疏学习
这一章的内容大致如下:
- 子集搜索与评价:什么是相关特征和无关特征?如何进行子集搜索和子集评价?如何进行特征选择?
- 过滤式选择:什么是过滤式选择?什么是 Relief 算法?如何实现 Relief 算法的?
- 包裹式选择:什么是包裹式选择?什么是 LVW 算法?如何实现 LVW 算法的?
- 嵌入式选择与L 1正则化:什么是嵌入式选择?L1正则化和L2正则化是怎样的?
- 稀疏表示与字典学习:什么是稀疏表示?稀疏表示的另一种表示是怎么样的?什么是字典学习?字典学习是如何实现的?
- 压缩感知:什么是压缩感知?什么是感知测量?什么是重构恢复?如何实现基于部分信息来恢复全部信息?
子集搜索与评价
描述一个西瓜有很多属性,比如:色泽、根蒂、敲声、纹理、触感等,但是一个有经验的挑瓜人往往只需 看看根蒂、听听敲声 就知道是否好瓜。换句话说,对一个学习任务来说,给定属性集,其中有些属性可能很关键、很有用,另一些属性则可能没什么用。这些属性称为 特征(feature),对当前学习任务有用的属性称为 相关特征(relevant feature) 、没什么用的属性称为 无关特征" (irrelevant feature)。从给定的特征集合中选择出 相关特征子集 的过程称为 特征选择(feature selection)。
特征选择是一个重要的 数据预处理(data preprocessing) 过程,在现实机器学习任务中,获得数据之后通常先进行 特征选择,此后再训练学习器。那么为什么要进行 特征选择 呢?
有两个很重要的原因:
- 第一个原因是,在现实任务中经常会遇到 维数灾难 问题。若能选出重要的特征,仅需在部分特征上构建模型,则维数灾难问题会大为减轻。
特征选择与第10章 《机器学习》周志华西瓜书学习笔记(十):降维与度量学习 有相似的动机,它们是处理高维数据的两个主流技术。
- 第二个原因是,去除 不相关特征 往往会降低学习任务的难度。
但是需要注意的是,特征选择 过程必须确保不丢失重要特征,否则学习过程会因重要信息的缺失而无法获得好的性能。给定数据集,若学习任务不同,则 相关特征 很可能不同。因此,特征选择 中的 无关特征 是指与当前学习任务无关。有一类特征称为 冗余特征(redundant feature) ,它们所含的信息能从其他特征中推演出来。冗余特征 在很多时候没有作用,或者多余,去除它们会减轻学习过程的负担,但有时 冗余特征 会降低学习任务的难度。
想从初始特征集合中选取一个包含了所有重要信息的特征子集,若没有相关领域的知识作为 先验假设,那就只好遍历所有可能的子集了(穷举);然而很明显,这在计算上是不可行的,因为这样做会组合爆炸,特征个数稍多一点就无法进行。因此,可行的做法是产生一个 候选子集,评价出它的好坏,然后基于评价结果产生下一个 候选子集,再进行评价,……以此类推,这个过程持续进行下去,直至无法找到更好的 候选子集 为止。
显然,有两个关键环节:
- 如何根据评价结果获取下一个候选特征子集?
- 如何评价候选特征子集的好坏?
第一个环节是 子集搜索(subset search) 问题。
给定一个特征集合 ,将每个特征看成一个 候选子集 进行评价,假定 最优,把它作为第一轮的选定集;然后,在上一轮的选定集中加入一个特征,构成包含两个特征的候选子集。假定在这中 最优,且优于 ,于是将 作为本轮的选定集。假定在第 轮时,最优的候选 特征子集不如上一轮的选定集,则停止生成候选子集,并将上一轮选定的 特征集合作为特征选择结果,这样逐渐增加 相关特征 的策略称为 前向(fòrward) 搜索。类似的,若从完整的特征集合开始,每次尝试去掉一个 无关特征,这样逐渐减少特征的策略称为 后向(backward) 搜索,还可将 前向与后向搜索 结合起来,每一轮逐渐增加选定 相关特征 (这些特征在后续轮中将确定不会被去除)、同时减少 无关特征,这样的策略称为 双向(bidirectional) 搜索。
第二个环节是子集评价(subset evaluation) 问题。
假设给定数据集
, 其中第4类样本所占的比例为
,同时假定样本属性均为离散型。对属性子集
,假定根据其取值将
分成了
个子集
,每个子集中的样本在
上取值相同,于是属性子集
的信息增益

其中信息熵定义为

信息增益
越大,意味着特征子集
包含的有助于分类的信息越多。于是,对每个候选特征子集都可以基于训练数据集
来计算其信息增益,以此作为评价准则。
更一般的,特征子集 实际上确定了对数据集 的一个划分,每个划分区域对应着 上的一个取值,而样本标记信息 则对应着对 的真实划分,通过估算这两个划分的差异,就能对 进行评价。与 对应的划分的差异越小,则说明 越好。信息熵仅仅是判断这个差异的一种途径,其他能判断两个划分差异的机制都能用于特征子集评价。
将 特征子集搜索 机制与 子集评价 机制相结合,即可得到特征选择方法。
常见的方法大致可分为三类:
- 过滤式(fiter)
- 包裹式(wrapper)
- 嵌入式(embedding)
过滤式选择
过滤式方法先对数据集进行 特征选择,然后再训练学习器,特征选择过程与后续学习器无关。
Relief (Relevant Features) 是一种著名的 过滤式特征选择 方法,该方法设计了一个 相关统计量 来度量特征的重要性。该统计量是一个向量,其每个分量分别对应于一个初始特征,而特征子集的重要性则是由子集中每个特征所对应的相关统计量分量之和来决定。最终只需指定一个阔值 , 然后选择比 大的相关统计量分量所对应的特征即可;也可指定想选取的特征个数 , 然后选择相关统计量分量最大的 个特征。
Relief 的关键是确定相关统计量。给定训练集
,对每个示例
,Relief 先在
的同类样本中寻找其最近邻
,称为 猜中近邻(near-hit),再从
的异类样本中寻找其最近邻
, 称为 猜错近邻(near-miss),然后,相关统计量对应于属性
的分量为

其中
表示样本均在属性
上的取值,
取决于属性
的类型:
- 若属性 为离散型,则 时 ,否则为1;
- 若属性 为连续型,则 , 都已规范化到 [0,1] 互间。
从上式可看出:
- 若 与其 猜中近邻 在属性 上的距离小于 与其 猜错近邻 的距离,则说明属性 对区分同类与异类样本是有益的,于是增大属性 所对应的统计量分量;
- 反之,若 与其 猜中近邻 在属性 上的距离大于 与其 猜错近邻 的距离,则说明属性 起负面作用。于是减小属性 所对应的统计量分量。
- 最后,对基于不同样本得到的估计结果进行平均,就得到各属性的相关统计量分量,分量值越大,则对应属性的分类能力就越强。
实际上 Relief 是一个运行效率很高的过滤式特征选择算法。是专门为二分类问题设计的。其扩展变体 Relie-F 能处理多分类问题。假定数据集
中的样本来自
个类别。对示例
,若它属于第
类
,则 Relief-F 先在第
类的样本中寻找
的最近邻示例
并将其作为 猜中近邻,然后在第
类之外的每个类中找到一个
的最近邻示例作为 猜错近邻,记为
。于是,相关统计量对应于属性
的分量为

其中
为第
类样本在数据集
中所占的比例。
包裹式选择
与过滤式特征选择不考虑后续学习器不同,包裹式特征选择直接把最终将要使用的学习器的性能作为特征子集的评价准则。换句话说,包裹式特征选择的目的就是为给定学习器选择最有利于其性能、"量身走做"的特征子集。
一般而言,由于包裹式特征选择方法直接针对给定学习器进行优化,因此从最终学习器性能来看,包裹式特征选择比过滤式特征选择更好;但另一方面,由于在特征选择过程中需多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征边择大得多。
LVW (Las Vegas Wrapper) 是一个典型的包裹式特征选择方法。它在 拉斯维加斯方法(Las Vegas method) 框架下使用随机策略来进行子集搜索,并以最终分类器的误差为特征子集评价准则。
拉斯维加斯方法和蒙特卡罗方法是两个以著名赌城名字命名的随机化方法。两者的主要区别是:
- 若有时间限制,则拉斯维加斯方法或者给出满足要求的解,或者不给出解,而蒙特卡罗方法一定会给出解,虽然给出的解未必满足要求;
- 若无时间限制,则两者都能给出满足要求的解。
算法描述如图所示:

算法第8行是通过在数据集
上,使用交叉验证法来估计学习器
的误差,这个误差是在仅考虑特征子集
时得到的,即特征子集
上的误差,若它比当前特征子集
上的误差更小,或误差相当但
中包含的特征数更少,则将
保留下来。
需注意的是,由于 LVW 算法中特征子集搜索采用了随机策略,而每次特征子集评价都需训练学习器,计算开销很大,因此算法设置了停止条件控制参数 ,然而,整个 LVW 算法是基于 拉斯维加斯 方法框架,若初始特征数很多(即 很大)、 设置较大,则算法可能运行很长时间都达不到停止条件。换句话说,若有运行时间限制,则有可能给不出解。
嵌入式选择与L1正则化
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别;与此不同,嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
给定数据集
,其中
。考虑最简单的线性回归模型,以平方误差为损失函数,则优化目标为

当样本特征很多,而样本数相对较少时,上式很容易陷入 过拟合,所以引入L2 范数正则化,则有

其中正则化参数
。上式称为 岭回归(ridge regression),通过引入L2 范数正则化,能显著降低过拟合的风险。
那么,能否替换为Lp范数呢?答案是肯定的。若令
,即采用L1范数,则有

其中正则化参数
。上式称为 LASSO(Least Absolute Shrinkageg Selection Operator)。
L1范数和L2范数正则化都有助于降低过拟合风险,但前者还会带来一个额外的好处:它比后者更易于获得 稀疏(sparse) 解,即它求得的 会有更少的非零分量。
详情可以看这个博客——深度学习100问之深入理解Regularization(正则化)
稀疏表示与字典学习
不妨把数据集 考虑成一个矩阵,其每行对应于一个样本,每列对应于一个特征。特征选择所考虑的问题是特征具有 稀疏性,即矩阵中的许多列与当前学习任务无关,通过特征选择去除这些列,则学习器训练过程仅需在较小的矩阵上进行,学习任务的难度可能有所降低,涉及的计算和存储开销会减少,学得模型的可解释性也会提高。
另一种稀疏性: 所对应的矩阵中存在很多零元素,但这些零元素并不是以整列、整行形式存在的。当样本具有这样的稀疏表达形式时,对学习任务来说会有不少好处,一方面是使大多数问题变得线性可分,同时,稀疏样本并不会造成存储上的巨大负担,因为稀疏矩阵已经有很多高效的存储方法。
那么,若给定数据集 是稠密的,即 普通非稀疏数据,能否将其转化为 稀疏表示(sparse representation) 形式,从而享有稀疏性所带来的好处呢?注意,所希望的稀疏表示是 恰当稀疏 而不是 过度稀疏。
显然,在一般的学习任务中(例如图像分类)并没有《字表》可用,我们需学习出这样一个 字典,为普通稠密表达的样本找到合适的字典,将样本转化为合适的稀疏表示形式,从而使学习任务得以简化,模型复杂度得以降低,通常称为 字典学习(dictionary learning) ,亦称 稀疏编码(sparse coding)。这两个称谓稍有差别,字典学习 更侧重于学得字典的过程,而 稀疏编码 则更侧重于对样本进行稀疏表达的过程。由于两者通常是在同一个优化求解过程中完成的,因此下面不做进一步区分,笼统地称为 字典学习。
给定数据集
,字典学习 最简单的形式为

其中
为字典矩阵,
称为字典的词汇量,通常由用户指定,
则是样本
的稀疏表示。显然,上式的第一项是希望由
能很好地重构
, 第二项则是希望
尽量稀疏。
与 LASSO 相比,上式显然麻烦得多,因为除了 的 ,还需学习字典矩阵 。不过,受 LASSO 的启发,可采用变量交替优化的策略来求解上式。
第一步,固定住字典
,若将上式按分量展开,可看出其中不涉及
这样的交叉项,于是可参照 LASSO 的解法求解下式,从而为每个样本院找到相应的
:

第二步,固定住
来更新字典
,此时可将上式写为

其中
,
,
是矩阵的Frobenius范数。上式有多种求解方法,常用的有 基于逐列更新策略的KSVD。令
表示字典矩阵
的第4列,
表示稀疏矩阵
的第
行,上式可重写为

解析
南瓜书:https://datawhalechina.github.io/pumpkin-book/#/
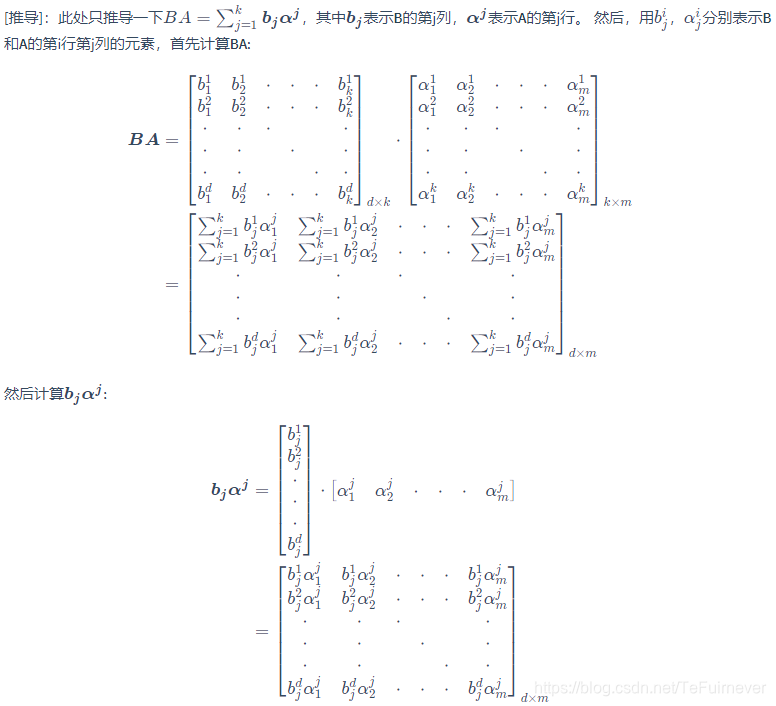
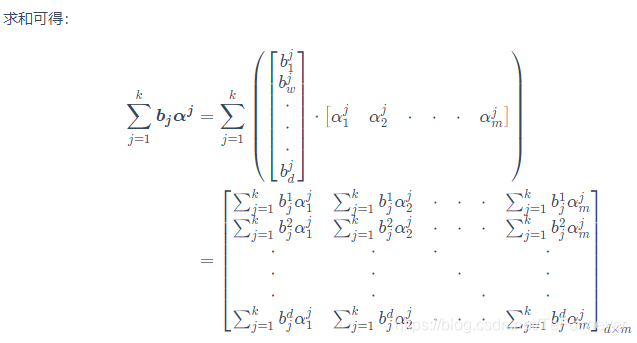
在更新字典的第
列时,其他各列都是固定的,因此

是固定的,于是最小化原则上只需对
进行奇异值分解,以取得最大奇异值所对应的正交向量。然而,直接对
进行奇异值分解会同时修改
和
,从而可能破坏
的稀疏性。为避免发生这种情况,KSVD 对
和
进行专门处理:
仅保留非零元素,
则仅保留
与
的非零元素的乘积项,然后再进行奇异值分解,这样就保持了第一步所得到的稀疏性。
初始化字典矩阵 之后反复迭代上述两步,最终即可求得字典 和样本 的稀疏表示 。在上述字典学习过程中,用户能通过设置词汇量 的大小来控制字典的规模,从而影响到稀疏程度。
压缩感知
在现实任务中,我们常希望根据部分信息来恢复全部信息。然而在现实中,总有各种信息的损失存在。那么基于收到的信号,能否精确地重构出原信号呢?压缩感知(compressed sensing) 为解决此类问题提供了新的思路。
与 特征选择、稀疏表示 不同,压缩感知关注的是如何利用信号本身所具有的稀疏性,从部分观测样本中恢复原信号。
通常认为,压缩感知分为 感知测量 和 重构恢复 这两个阶段。
- 感知测量 关注如何对原始信号进行处理以获得稀疏样本表示;
- 重构恢复关注的是如何基于稀疏性从少量观测中恢复原信号,这是压缩感知的精髓。
压缩感知的相关理论比较复杂,下面仅简要介绍一下 限定等距性(Restricted Isometry Property,简称RIP)。
对大小为 的矩阵 ,若存在常数 使得对于任意向量 和 的所有子矩阵 有

则称
满足
限定等距性(k-RIP)。此时可通过下面的优化问题近乎完美地从ν 中恢复出稀疏信号s , 进而恢复出x:

然而,上式涉及L0范数最小化,这是个NP难问题。值得庆幸的是,L1范数最小化在一定条件下与L0范数最小化问题共解,于
是实际上只需关注

这样,压缩感知问题就可通过L1范数最小化问题求解,例如上式可转化为LASSO的等价形式再通过近端梯度下降法求解,即使用 基寻踪去噪(Basis Pursuit De-Noising)。
基于部分信息来恢复全部信息的技术在许多现实任务中有重要应用。例如网上书店通过收集读者在网上对书的评价,可根据读者的读书偏好来进行新书推荐,从而达到走向广告投放的效果。显然,没有哪位读者读过所有的书,也没有哪本书被所有读者读过,因此,网上书店所搜集到的仅有部分信息。
下表给出了四位读者的网上评价信息,这里评价信息经过处理,形成了"喜好程度"评分(5 分最高)。由于读者仅对读过的书给出评价,因此表中出现了很多未知项"? "

那么,能否将表中通过读者评价得到的数据,当作部分信号,基于压缩感知的思想恢复出完整信号呢?
我们知道,能通过压缩感知技术恢复欠采样信号的前提条件之一是 信号有稀疏表示。读书喜好数据是否存在稀疏表示昵?答案是肯定的。一般情形读者对书籍的评价取决于题材、作者、装帧等多种因素,为简化讨论,假定表中的读者喜好评分仅与题材有关。《笑傲证湖》和《云海玉弓缘》是武侠小说,《万历十五年》和《人类的故事》是历史读物,《人间词话》属于诗词文学。
一般来说,相似题材的书籍会有相似的读者。若能将书籍按题材归类,则题材总数必然远远少于书籍总数,因此从题材的角度来看,表中反映出的信号应该是稀疏的。于是,应能通过类似压缩感知的思想加以处理。矩阵补全(matrix completion) 技术可用于解决这个问题,其形式为

其中,
表示需恢复的稀疏信号;
表示矩阵
的秩;
是如表读者评分矩阵这样的已观测信号;
是
中非"?"元素
的下标
的集合。约束项明确指出,恢复出的矩阵中
应当与已观测到的对应元素相同。
这个式子也是一个NP难问题。注意到
在集合
上的凸包是
的 核范数(nuclear norm):

其中
表示
的奇异值,即矩阵的核范数为矩阵的奇异值之和,于是可通过最小化矩阵核范数来近似求解,即

上式是一个凸优化问题,可通过 半正定规划(Semi-Definite Programming,简称SDP) 求解。理论研究表明,在满足一定条件时,若
的秩为
,
,则只需观察到
个元素就能完美恢复出
。
