union-find主要用于解决动态连通性的问题,
如下图:
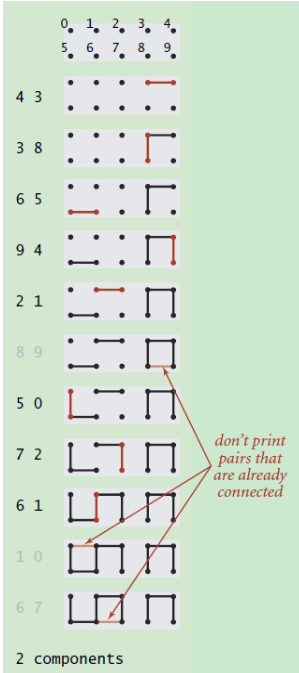
对于输入的一系列整数对p,q,表示p和q是相连的,在将整数对输入完毕后,我们就可以从该图中获取该图的连通性,如任意两个节点是否相连,共有几个连通分量。如上图可看出共有两个连通分量:0-5-6-1-2-7,8-3-4-9
union-find算法API如下:
//初始化count个顶点
public UF(int count)
//p和q两个点是否连通
public boolean connected(int p,int q)
//返回点p所在分量的标识符
private int find(int p)
//返回连通分量的个数
public int count()
//将p和q两个点连接
public void union(int p,int q)
对于find()和union()有多种实现方式,我们先介绍最基本的quick-find算法:
quick-find
在该算法中,我们使用一个int id[]数组表示对应的顶点所在的连通分量标识符,如id[0]=0表示顶点0所在的连通分量为0,
在构造函数中,会将所有顶点对应的id[]值初始化为与其自身相等的值,表示一开始各个点都以自身作为一个单独的分量,互相不连通。
如下:
private int[] id;
/**
* 连通分量数量(标识符)
*/
private int count;
public UF(int count) {
this.count = count;
this.id=new int[count];
for (int i = 0; i < count; i++) {
id[i]=i;
}
}
对于find()的实现,先介绍quick-find算法,其实现如下:
private int quickFind(int i) {
return id[i];
}
id[i]直接保存i的分量id,因此当id[p]=id[q]时,表示p和q是连通的。
由此可得connected(p,q)的实现:
/**
* p和q是否在同一个分量
*/
public boolean connected(int p,int q){
return quickFind(p)==quickFind(q);
}
而要想实现将p和q连接起来,
首先要判断两点是否连通,如果连通则直接返回,如果不连通,则遍历id数组,让所有与id[p]相等的点,改为id[q],即将所有与p在同一个连通分量上的点修改为q所在连通分量。
图示如下:
如要连接union(3,4),p=3,q=4
id数组如下:
p q 0 1 2 3 4 5 6 7 8 9
3 4 1 1 2 3 5 6 6 3 3 5
可见,id[p]=id[3]=3 ,id[q]=id[4]=5
与p在同一分量的点有:3 7 8
与q在同一分量的点有: 4 9
所以union(3,4)的任务就是让所有id[i]等于3的位置,改为5,即实现连接
连接后的状态如下:
p q 0 1 2 3 4 5 6 7 8 9
3 4 1 1 2 3 5 6 6 3 3 5
1 1 2 5 5 6 6 5 5 5
union实现如下:
public void union(int p,int q){
if (!connected(p,q)){
for (int i = 0; i < id.length; i++) {
if (id[i]==id[p]){
id[i]=id[q];
count--;
}
}
}
}
不难发现,该算法每次find()只会访问一次数组,每次union()操作数组的次数 在N+3到2N+1次,最坏情况下会达到平方级别。因此该算法速度快,但无法解决大型问题,因为每次都需要遍历整个id[]数组。
接下来的quick-union对quick-find进行了优化:
quick-union
该算法的数据结构同quick-find相同,但是id[]的意义改变了。
在该算法中,id[]中的元素保存的都是同一个连通分量中的另一个元素。
如下图:
1 8
/ | \ / \
0 2 7 3 9
| |
5 4
|
6
由上图可得id数组:
0 1 2 3 4 5 6 7 8 9 id索引
1 1 1 8 3 0 5 1 8 8 值
可知除了根节点,所有的节点的id值都等于上一个节点的值。
而同一个分量的节点,循环向上寻找,最终都会在根节点相遇。
如果两个节点在根节点的值相同,则说明在同一个分量,否则在不同的分量中。
如果要连接两个分量,只需连接两个分量的根节点,如上图,要连接5和9,则直接让id[1]=8即可。
可得如下union-find算法:
public void union(int p,int q){
int i = find(p);
int j = find(q);
if (i!=j){
id[i]=j;
count--;
}
}
public int find(int p){
while(p!=id[p]){
p=id[p];
}
return p;
}
分析可知,该算法的find()方法访问数组的次数为1+给定出点对应的高度的两倍,union()访问数组次数为两次find()操作,如果两个不在一个分量中,则还需+1次。在最坏情况下,只有一个无分支的连通分量,即顶点高度height=N,N为所有节点数,此时的运行时间也是平方级的,如果数量巨大,则也很吃力。
加权quick-union算法
该算法在理解quick-union的基础上,会记录每个节点的高度,在每次union时,会比较高度,并将小树连接到大树上,这样控制树的高度就可以解决上述quick-union的最坏情况。
public class WeightedQuickUnionFind {
private int[] id;
//每个根节点对应的分量的大小
private int[] weighted;
private int count;
public WeightedQuickUnionFind(int count) {
this.count = count;
weighted=new int[count];
id = new int[count];
for (int i = 0; i < count; i++) {
//分量大小初始化为1
weighted[i]=1;
//分量标识符初始化为自身
id[i]=i;
}
}
}
该算法的find()方法同上,union算法如下:
/**
* 加权quick-union算法,保证每次都将小树加到大树上
* @param p
* @param q
*/
public void union(int p,int q){
int i = find(p);
int j = find(q);
if(i==j)return;
else{
//连接时判断两个根节点所在分量的大小
if (weighted[i]<weighted[j]){
id[i]=j;
//修改大小
weighted[j] += weighted[i];
}else {
id[j]=i;
weighted[i] += weighted[j];
}
}
count--;
}
加权quick-union算法 可用于解决大型问题
N个点M个连接最多访问数组cMlogN次,c为常数
最坏情况下find()、connected()和union()的增长数量级为logN
最优算法(使用路径压缩)
最优的算法应当是一种能够保证在常数时间内完成各种操作的算法。
理想情况下我们希望各个节点都直接链接到根节点,又不想通过大量修改实现。要实现这种算法,就是在find()同时,将该节点路径上的所有节点都直接链接到根节点。
在find()中实现路径压缩:
/**
* 使用路径压缩,将路径上的所有节点都直接与根节点相连
* @param p
* @return
*/
public int find(int p) {
//root记录根节点
int root=p;
while (root!=id[root]){
//循环找到当前节点所在分量的根节点
root=id[root];
}
//此时root已经为当前分量根节点
//对p进行同样方法的循环,将与p在同一个路径上的节点直接与root相连接
while (id[p]!=root){
int temp=p;
//当前节点与root连接
id[temp]=root;
//指向下一个节点,继续循环
p=id[p];
}
return root;
}
因此使用路径压缩的加权quick-union算法就是该问题的最优解,该算法的union和find()的成本的增长数量级已经非常接近1,但没达到1
以下是完整代码:
public class ComPathWeightedQuickUnionFind {
private int[] id;
private int[] weighted;
private int count;
public ComPathWeightedQuickUnionFind(int count) {
this.count = count;
weighted=new int[count];
id = new int[count];
for (int i = 0; i < count; i++) {
weighted[i]=1;
id[i]=i;
}
}
/**
* 加权quick-union算法,保证每次都将小树加到大树上
* @param p
* @param q
*/
public void union(int p,int q){
int i = find(p);
int j = find(q);
if (i==j){
return;
}else {
if (weighted[i]<weighted[j]){
id[i]=j;
weighted[j] += weighted[i];
}else {
id[j]=i;
weighted[i] += weighted[j];
}
}
count--;
}
/**
* 使用路径压缩,将路径上的所有节点都直接与根节点相连
* @param p
* @return
*/
public int find(int p) {
int root=p;
while (root!=id[root]){
root=id[root];
}
while (id[p]!=root){
int temp=p;
id[temp]=root;
p=id[p];
}
return root;
}
public boolean connected(int p , int q){
return find(p)==find(q);
}
public int count(){
return count;
}
}
参考:《算法第四版》1.5节
