1 导入初始数据到Neo4j
数据下载地址:https://www.macalester.edu/~abeverid/data/stormofswords.csv。它看起来像这样:

Source,Target,Weight
Aemon,Grenn,5
Aemon,Samwell,31
Aerys,Jaime,18
这里,我们拥有整个文本中角色的邻接表和他们的互动次数。我们将使用一个简单的数据模型(:Character {name})-[:INTERACTS {weight}]->(:Character {name})。带有标签的节点Character表示文本中的角色,单个关系类型INTERACTS从该角色连接到另一个文本中交互的角色。我们将把角色名作为node属性name存储,把两个角色之间的交互数作为relationships属性weight存储。
首先,我们必须创建一个约束来断言我们架构的完整性:
CREATE CONSTRAINT ON (c:Character) ASSERT c.name IS UNIQUE;
一旦创建了约束(该语句也将构建一个索引,它将提高通过角色名查找的性能),我们可以使用Cypher的LOAD CSV语句来导入数据:
导入本地文件:
# 本地csv文件要放到安装包下的import目录下
load csv with headers from 'file:///stormofswords.csv' as row
merge (src:Character {name: row.Source})
merge (tgt:Character {name: row.Target})
merge (src) -[r:INTERACTS]-> (tgt)
set r.weight = toInt(row.Weight)

导入网络文件:
LOAD CSV WITH HEADERS FROM "https://www.macalester.edu/~abeverid/data/stormofswords.csv" AS row
MERGE (src:Character {name: row.Source})
MERGE (tgt:Character {name: row.Target})
MERGE (src)-[r:INTERACTS]->(tgt)
ON CREATE SET r.weight = toInt(row.Weight)
我们有一个非常简单的数据模型:
CALL apoc.meta.graph()
权利的游戏图的数据模型。角色节点通过INTERACTS关系连接。我们可以看到整个图形,但这并没有给我们关于最重要人物或他们如何交互的许多信息:
MATCH p=(:Character)-[:INTERACTS]-(:Character) RETURN p
2 分析网络
这里探索的许多思路在https://www.cs.cornell.edu/home/kleinber/networks-book/进行了详细的解释。
2.1 角色数
让我们先从简单的部分入手。在我们的图中,出现了多少个角色?
MATCH (c:Character) RETURN count(c)
2.3 网络直径
一个网络的直径(或者测地线)被定义为网络中的最长最短路径。
// Find maximum diameter of network,maximum shortest path between two nodes
MATCH (a:Character), (b:Character) WHERE id(a) > id(b)
MATCH p=shortestPath((a)-[:INTERACTS*]-(b))
RETURN length(p) AS len, extract(x IN nodes(p) | x.name) AS path
ORDER BY len DESC LIMIT 4
我们可以看到,在网络中,有许多长度为6的路径。
2.4 最短路径
我们可以使用Cypher中的shortestPath函数来查找图中任意两个角色的最短路径。让我们找找从Catelyn Stark到Khal Drogo的最短路径:
// Shortest path from Catelyn Stark to Khal Drogo
MATCH (catelyn:Character {name: "Catelyn"}), (drogo:Character {name: "Drogo"})
MATCH p=shortestPath((catelyn)-[INTERACTS*]-(drogo))
RETURN p
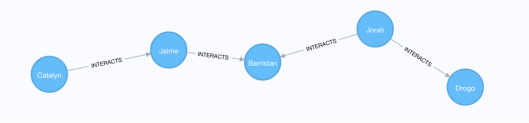
2.5 所有最短路径
可能还有其他具有相同长度的连接Catelyn和Drogo的路径。我们可以使用allShortestPaths函数来查找:
// All shortest paths from Catelyn Stark to Khal Drogo
MATCH (catelyn:Character {name: "Catelyn"}), (drogo:Character {name: "Drogo"})
MATCH p=allShortestPaths((catelyn)-[INTERACTS*]-(drogo))
RETURN p
3 关键节点
如果节点位于网络中的其它两个节点之间的所有最短路径之中,那么该节点被认为是关键的。我们可以找到网络中的所有关键节点:
要修改neo4j.conf配置文件:
cypher.forbid_shortestpath_common_nodes=false
// Find all pivotal nodes in network
MATCH (a:Character), (b:Character)
MATCH p=allShortestPaths((a)-[:INTERACTS*]-(b)) WITH collect(p) AS paths, a, b
MATCH (c:Character) WHERE all(x IN paths WHERE c IN nodes(x)) AND NOT c IN [a,b]
RETURN a.name, b.name, c.name AS PivotalNode SKIP 490 LIMIT 10
如果我们翻阅了有趣结果的结果表,那么可以看到,对于Drogo和Ramsay来说,Robb是一个关键节点。这意味着,所有连接Drogo和Ramsay的最短路径都经过Robb。我们可以通过看看连接Drogo和Ramsay的所有最短路径,验证这点:
MATCH (a:Character {name: "Drogo"}), (b:Character {name: "Ramsay"})
MATCH p=allShortestPaths((a)-[:INTERACTS*]-(b))
RETURN p
4 中心性度量
中心性度量为我们提供了网络中重要性的相对措施。有许多不同的中心性度量,而每种度量不同类型的“重要性”。
4.1 度中心性(Degree Centrality)
度中心性仅是一个节点在网络中的连接数。在权利的游戏的图的上下文中,一个角色的度中心性是该角色交互的其他角色数。我们可以像这样使用Cypher来计算度中心性:
MATCH (c:Character)
RETURN c.name AS character, size( (c)-[:INTERACTS]-() ) AS degree ORDER BY degree DESC
而且我们看到,Tyrion与网络中的角色具有最多的互动。鉴于他的心计,我觉得这是有道理的。
4.2 加权度中心性
我们存储一对角色之间的交互数,作为INTERACTS关系上的weight属性。对角色的所有INTERACTS关系上的该权重求和,我们可以获得他们的加权度中心性,或者他们参与的交互总数。同样,我们可以使用Cypher来为所有的角色计算该度量:
MATCH (c:Character)-[r:INTERACTS]-()
RETURN c.name AS character, sum(r.weight) AS weightedDegree ORDER BY weightedDegree DESC
4.3 中介中心性(Betweenness Centrality)
一个网络中的一个节点的中介中心性(Betweenness Centrality)是,网络中所有的节点对之间通过该节点的最短路径数。中介中心性是一项重要的指标,因为它可以用于识别网络中的“信息代理”,或者那些连接不同集群的节点。
红色的节点具有较高的中介中心性,并且是集群的连接点。要计算中介中心性,我们将使用新的用于Neo4j 3.x或apoc库的程序。
要修改neo4j.conf配置文件:
dbms.security.procedures.unrestricted=algo.*,apoc.*
一旦我们安装了apoc,我们就可以调用Cypher中170+个程序中的任意一个:
MATCH (c:Character)
WITH collect(c) AS characters
CALL apoc.algo.betweenness(['INTERACTS'], characters, 'BOTH') YIELD node, score
SET node.betweenness = score
RETURN node.name AS name, score ORDER BY score DESC
4.4 接近中心性(Closeness centrality)
接近中心性(Closeness centrality)是到网络中所有其他角色的平均距离的倒数。具有高接近中心性的节点通常在图中的集群之间被高度连接,但在集群外部不一定是高度连接的。
具有高接近中心性的节点连接了网络中许多其他节点。
MATCH (c:Character)
WITH collect(c) AS characters
CALL apoc.algo.closeness(['INTERACTS'], characters, 'BOTH') YIELD node, score
RETURN node.name AS name, score ORDER BY score DESC
4.5 PageRank
估计当前节点对其相邻节点的重要性,然后再从其邻居那里获得节点的重要性。一个节点的排名来源于其传递链接的数量和质量。PageRank虽然被谷歌抛弃了,但它还是被广泛认为是检测任何网络中有影响力的节点的常用方式。
MATCH (c:Character) WITH collect(c) AS nodes
CALL apoc.algo.pageRankWithConfig(nodes,{types:'INTERACTS'}) YIELD node, score
RETURN node.name, score
ORDER BY score DESC
5 使用python-igraph
我们可以继续使用apoc来运行PageRank和社区检测算法,但是,让我们切换到使用python-igraph来计算一些分析。Python-igraph移植自R的igraph图形分析库。仅需使用pip install python-igraph,即可安装它。
5.1 从Neo4j构建一个igraph实例
要在我们的权利游戏的数据图上使用igraph,所需要做的第一件事是从Neo4j中取出数据,然后在Python中构建一个igraph实例。我们可以使用py2neo,将一个py2neo查询的结果对象直接传到igraph的TupleList构造函数,以创建一个igraph实例:
from py2neo import Graph
from igraph import Graph as IGraph
graph = Graph()
query = '''
MATCH (c1:Character)-[r:INTERACTS]->(c2:Character)
RETURN c1.name, c2.name, r.weight AS weight
'''
ig = IGraph.TupleList(graph.run(query), weights=True)
现在,我们有了一个igraph对象,我们可以用它来运行任何igraph中实现的图算法了。
5.2 PageRank
igraph中,我们要使用的第一个算法是PageRank。PageRank是一种最初由Google用来对网页重要性进行排序的算法,它是一种特征向量中心性(eigenvector centrality)算法。

PageRank:每个节点的大小正比于网络中指向它的其他节点的数目和大小。
这里,我们将在igraph实例上运行Pagerank,然后将结果写回到Neo4j,在角色节点上创建一个pagerank属性,以存储刚刚在igraph中计算的值:
pg = ig.pagerank()
pgvs = []
for p in zip(ig.vs, pg):
pgvs.append({"name": p[0]["name"], "pg": p[1]})
write_clusters_query = '''
UNWIND {nodes} AS n
MATCH (c:Character) WHERE c.name = n.name
SET c.pagerank = n.pg
'''
graph.run(write_clusters_query, nodes=pgvs)
现在,我们可以查询在Neo4j中的图,以找到具有最高PageRank得分的节点:
MATCH (n:Character)
RETURN n.name AS name, n.pagerank AS pagerank ORDER BY pagerank DESC LIMIT 10
5.3 社区检测
社区检测算法用以查找图中的集群。使用igraph中实现的walktrap方法,来找到那些在社区之中频繁交互,但在社区之外不存在太多互动的角色的社区。
我们将运行walktrap社区检测算法,然后将新发现的社区数写回到Neo4j,其中,每个角色所属的社区用一个整数来表示:
clusters = IGraph.community_walktrap(ig, weights="weight").as_clustering()
nodes = [{"name": node["name"]} for node in ig.vs]
for node in nodes:
idx = ig.vs.find(name=node["name"]).index
node["community"] = clusters.membership[idx]
write_clusters_query = '''
UNWIND {nodes} AS n
MATCH (c:Character) WHERE c.name = n.name
SET c.community = toInt(n.community)
'''
graph.run(write_clusters_query, nodes=nodes)
然后,我们可以查询Neo4j,看看最后我们有多少个社区(或者集群),以及每个社区中的成员:
MATCH (c:Character)
WITH c.community AS cluster, collect(c.name) AS members
RETURN cluster, members ORDER BY cluster ASC
5.4 可视化-把它们放在一起
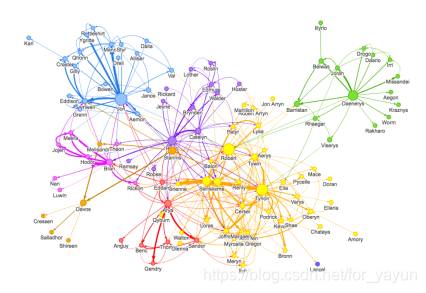
Neo4j浏览器对于可视化Cypher查询的结果是棒棒哒,但如果我们想要在另一个应用中嵌入我们的图形可视化,我们可能需要使用许多用于图形可视化的伟大的Javascript库中的一个。Vis.js就是这样的一个库,它允许我们构建互动式图形可视化。要进行从Neo4j抽取数据,并使用vis.js构建图形可视化的过程,我一直使用neovis.js,它将vis.js和Neo4j官方Javascript驱动组合在一起。Neovis.js提供了一个简单的API,允许配置可视化。例如,下面的Javascript是生成上面的可视化所需的:
var config = {
container_id: "viz",
server_url: "localhost",
labels: {
"Character": "name"
},
label_size: {
"Character": "betweenness"
},
relationships: {
"INTERACTS": null
},
relationship_thickness: {
"INTERACTS": "weight"
},
cluster_labels: {
"Character": "community"
}
};
var viz = new NeoVis(config);
viz.render();
请注意,我们已经指定:
在可视化中,我们想要包含带标签Character的节点,使用合适的name作为其标题
节点大小应该正比于它们的betweenness属性
在可视化中,我们想要包含INTERACTS关系
关系的厚度应该正比于weight属性值
节点应该根据community属性值来着色,该属性标识网络中的集群
从localhost上的一个Neo4j服务器中抽取数据
在一个id为viz的DOM元素中展示可视化
Neovis.js需要从Neo4j拉取数据,并且基于我们的最低配置创建可视化。
Github上找到代码。
https://github.com/johnymontana/graph-of-thrones/blob/master/network-of-thrones.ipynb
