Hadoop_MapReduce压缩案例
在map输出端压缩
修改 Hadoop_WordCount单词统计 工程
只需要修改 MyWordCount 的main方法即可:
package com.blu.mywordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWordCount {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
//设置在mapper输出端进行压缩
conf.set("mapreduce.map.output.compress", "true");
//设置压缩方式
//参数2为要使用的压缩类型
//参数3为参数2的父类
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
Job job = Job.getInstance(conf);
//设置运行的类
job.setJarByClass(MyWordCount.class);
//设置mapper和reducer对应的类
job.setMapperClass(MyWordCountMapper.class);
job.setReducerClass(MyWordCountReducer.class);
//运行mapper和最终输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置文件的输入和输出的路径
// hadoop jar example.jar wordcount /input/a.txt /output
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//运行job
boolean flag = job.waitForCompletion(true);
//0表示正常退出
//1表示不正常退出
System.exit(flag ?0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
具体修改的内容(配置 Configuration ):
- 开启mapper输出端的压缩功能
- 指定压缩类型
//设置在mapper输出端进行压缩
conf.set("mapreduce.map.output.compress", "true");
//设置压缩方式
//参数2为要使用的压缩类型
//参数3为参数2的父类
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
在reduce输出端压缩
同样只需要修改 MyWordCount 的main方法即可:
package com.blu.mywordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWordCount {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("mapreduce.map.output.compress", "true");
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
Job job = Job.getInstance(conf);
job.setJarByClass(MyWordCount.class);
job.setMapperClass(MyWordCountMapper.class);
job.setReducerClass(MyWordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//设置在reduce输出端进行压缩
FileOutputFormat.setCompressOutput(job, true);
//设置压缩格式
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
boolean flag = job.waitForCompletion(true);
System.exit(flag ?0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
具体修改的内容(配置 job ):
- 开启reduce输出端的压缩功能
- 指定压缩类型
//设置在reduce输出端进行压缩
FileOutputFormat.setCompressOutput(job, true);
//设置压缩格式
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
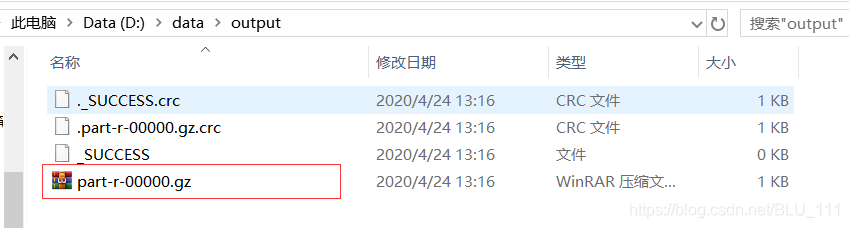
运行结果:在D:\data\output目录生成以下文件,其中part-r-00000为压缩包格式