以下所有案例源代码地址:案例源代码
1. 求每月最高温度的两天
在一组含有时间年月日时分秒以及此时温度的数据中,通过hadoop的map&reduce取出一个月中温度最高的两个数据。
数据如下:
1949-10-01 14:21:02 34c
1949-10-01 19:21:02 38c
1949-10-02 14:01:02 36c
1950-01-01 11:21:02 32c
1950-10-01 12:21:02 37c
1951-12-01 12:21:02 23c
1950-10-02 12:21:02 41c
1950-10-03 12:21:02 27c
1951-07-01 12:21:02 45c
1951-07-02 12:21:02 46c
1951-07-03 12:21:03 47c
直接上代码: 主类,按照框架运行的机制来说,为client
// 主要实现找出每个月气温最高的两天
public class MyTQ {
public static void main(String[] args) throws Exception {
// 加载配置
Configuration conf = new Configuration(true);
// 获取工作
Job job = Job.getInstance(conf);
// 设置jar类,方便寻找
job.setJarByClass(MyTQ.class);
// conf 开始配置
// 输入格式化类,如果需要可以自己定义
// job.setInputFormatClass(ooxx.class);
// 设置map,获取mapper
job.setMapperClass(TMapper.class);
// 设置输出的key-value键值对类型
job.setOutputKeyClass(TQ.class);
job.setOutputValueClass(IntWritable.class);
// 由于map的主要功能就是映射数据形成keyvalue,需要设置比较器
job.setSortComparatorClass(TSortComparator.class);
// 在输出的时候需形成k&v&p,所以需要设置分区
job.setPartitionerClass(TPartitioner.class);
// 输出之后需要进入溢写区,按照框架给的默认的即可
// 设置combiner,如果有需要数据合并的话
// job.setCombinerClass(TCombiner.class);
// 设置reduce,获取reduce
job.setReducerClass(TReduce.class);
// 使用reduce:原语:一组数据对应一个reduce,在一个reduce方法中迭代数据,进行计算
// 设置分组比较器
job.setGroupingComparatorClass(TGroupingComparator.class);
// 设置reduce个数
job.setNumReduceTasks(2);
// 设置文件输入路径
Path input = new Path("/data/tq/input");
FileInputFormat.addInputPath(job, input);
// 设置文件输出路径
Path output = new Path("/data/tq/output");
// 由于hadoop对于文件输出的路径要求不能已存在的
if (output.getFileSystem(conf).exists(output)) {
output.getFileSystem(conf).delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
job.waitForCompletion(true);
}
}
TQ类:主要实现数据的写入类型,注意这里实现了WritableComparable需要重写比较方法、序列化、反序列化,需要注意对于序列化反序列化的读取与写入需要使用相同的反方,否则会报错EOFException异常…
public class TQ implements WritableComparable<TQ> {
private int year;
private int month;
private int day;
private int wd;
// 省略构造方法与get/set方法
// 日期正序
@Override
public int compareTo(TQ that) {
int c1 = Integer.compare(this.year, that.getYear());
if (c1 == 0) {
int c2 = Integer.compare(this.month, that.getMonth());
if (c2 == 0) {
return Integer.compare(this.day, that.getDay());
}
return c2;
}
return c1;
}
// 下面两个方法是序列化与反序列化
// 写的时候也需要按照整型写入否则会出现I/O异常!
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(year);
out.writeInt(month);
out.writeInt(day);
out.writeInt(wd);
}
@Override
public void readFields(DataInput in) throws IOException {
this.year = in.readInt();
this.month = in.readInt();
this.day = in.readInt();
this.wd = in.readInt();
}
}
TMapper类:
public class TMapper extends Mapper<LongWritable, Text, TQ, IntWritable> {
TQ mkey = new TQ();
IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 主要是设置mkey-mval,获取到分区的数据 2019-09-20 12:20:31 34c
try {
String[] str = StringUtils.split(value.toString(), "\t");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date time = sdf.parse(str[0]);
// 获取到时间的数据
Calendar calendar = Calendar.getInstance();
calendar.setTime(time);
mkey.setYear(calendar.get(Calendar.YEAR));
// 看注解可以发现这个月份是从1开始,但是值是从0开始
mkey.setMonth(calendar.get(Calendar.MONTH) + 1);
mkey.setDay(calendar.get(Calendar.DAY_OF_MONTH));
// 取出温度
int wd = Integer.parseInt(str[1].substring(0, str[1].length() - 1));
mkey.setWd(wd);
mval.set(wd);
// 写入到上下文
context.write(mkey, mval);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
TSortComparator:排序器
public class TSortComparator extends WritableComparator {
// 构造器,调用父类的方法生成比较的实例
public TSortComparator() {
super(TQ.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 转换成天气做对比,此时需要比较的是三个维度
TQ t1 = (TQ) a;
TQ t2 = (TQ) b;
int c1 = Integer.compare(t1.getYear(), t2.getYear());
if (c1 == 0) {
int c2 = Integer.compare(t1.getMonth(), t2.getMonth());
if (c2 == 0) {
// 如果是同一天的话,采用逆序排列
return -Integer.compare(t1.getWd(), t2.getWd());
}
}
return c1;
}
}
TPatritioner:分区器,hashCode取余
public class TPartitioner extends Partitioner<TQ, IntWritable> {
@Override
public int getPartition(TQ tq, IntWritable intWritable, int numPartitions) {
return tq.hashCode() % numPartitions;
}
}
TGroupingCompartator:分组比较器
public class TGroupingComparator extends WritableComparator {
public TGroupingComparator(){
super(TQ.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
TQ t1 = (TQ) a;
TQ t2 = (TQ) b;
// 按照年月分组,取的温度值
int c1 = Integer.compare(t1.getYear(), t2.getYear());
if (c1 == 0) {
return Integer.compare(t1.getMonth(), t2.getMonth());
}
return c1;
}
}
TReducer:reduce处理
public class TReduce extends Reducer<TQ, IntWritable, Text, IntWritable> {
// 构建输出数据,都需要写入到上下文中
Text reduceKey = new Text();
IntWritable reduceVal = new IntWritable();
@Override
protected void reduce(TQ key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int data = 0;
int day = 0;
// 对真迭代器中的数据做一个遍历
for (IntWritable value : values) {
// 表示是第一个数据
if(data == 0){
// 写入处理
reduceKey.set(key.getYear()+"-"+key.getMonth()+"-"+key.getDay());
reduceVal.set(key.getWd());
data++;
day = key.getDay();
// 写入上下文
context.write(reduceKey,reduceVal);
}
// 数据迭代更新,找到了第二高的数据了
if(data != 0 && day != key.getDay()){
reduceKey.set(key.getYear()+"-"+key.getMonth()+"-"+key.getDay());
reduceVal.set(key.getWd());
context.write(reduceKey,reduceVal);
break;
}
}
}
}
源码地址:github源码地址
2. 好友推荐

数据集:
tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr
只计算间接的关系得出的数据:可以通过此数据集计算出topN推荐
cat:hadoop 2
cat:hello 2
cat:mr 1
cat:world 1
hadoop:hello 3
hadoop:mr 1
hive:tom 3
mr:tom 1
mr:world 2
tom:world 2
3. PageRank算法
什么是pagerank
- PageRank是Google提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。
- 是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的,PageRank实现了将链接价值概念作为排名因素。
算法原理:
- 入链等同于投票
- PageRank让链接来投票,到一个页面的链接相当于对该页面投一票。
- 入链数量
- 如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
- 入链质量
- 指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
PageRank的计算:
PR值需要迭代计算,PR值计算过程是一个收敛过程,最终结果的对比值将趋向于0.
算法原理:
- 初始值
- Google的每个页面设置相同的PR值
- PageRank算法给每个页面的PR初始值为1
- 迭代计算(收敛)
- Google不断的重复计算每个页面的PR值,经过不断的重复计算,这些页面的PR值会趋向于稳定,即处于一个收敛的状态。
- 如何确定收敛的标准?
- 每个页面的PR值和上一次计算的PR值相等
- 设定一个差值指标,例如0.0001,当所有页面和上一次计算的PR差值平均小于此指标时,表明收敛
- 设定一个百分比99%,当99%的页面和上一次计算的PR值相等即可判定收敛
PageRank计算:
- 从互联网的角度看问题:
- 只出,不入,PR会为0;只入,不出,PR会很高。
- 由于存在上述两种极端情况,所以需要修正PR值计算公式,增加阻尼系数d
- 一般d取0.85(表示在日常生活中,人们访问网页,85%都是通过链接访问的)
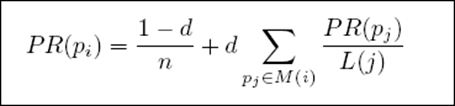
- d:阻尼系数
M(i):指向i的页面集合
L(j):页面的出链数
PR(pj):j页面的PR值
n:所有页面数
4. TFIDF词频逆文件频率
概念:
- TFIDF(term frequency-inverse document frequency)是一种用于资讯检索和资讯探勘的常用加权技术。
- TFIDF是一种统计方法,用以评估一字词对于一个文件集或者一个语料库的其中一份文件的重要程度。
- 字词的重要性随着它在文件中出现的次数成正比增加
- 但同时会随着它在语料库中出现的频率成反比下降
- TF-IDF加权的各种形式常被搜寻引擎应用
- 作为文件与用户查询之间相关程度的度量或者评级
- 除了TF-IDF外,因特网上的搜寻引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序:PR(PageRank)
词频(Term Frequency,TF) 指得是某一个给定的词语在一份给定的文件中出现的次数。这个数字通常会被归一化(分子一般小于分母区别于IDF),以防止它偏向场的文件。(同一个词语在长文件中可能会比段文件有更高的词频,而不管该词语重要与否)
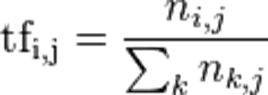
- ni,j是该词在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的衡量。某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,在将得到的商取对数得到。
|D|:语料库中的文件总数
|{j:ti ∈ dj}|表示ti文件总的数目
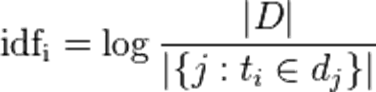
TF-IDF:
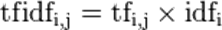
- 某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语
- TFIDF的重要思想:如果某个词语或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用于分类。
具体实现的步骤:
- 利用第三方工具实现句子的分词,同时实现文件总个数的计算
- 面向文本计算词频:wc
- 面向全量文本计算包含集合:wc
- 套用公式实现句子中每个此出现的词频逆文件频率
5. itemCF
协同过滤算法:Collaborative Filtering协同过滤
ItemCF:基于item的系统过滤,通过用户对不同的评分来评测item直接的相似性,基于item之间的相似性做出推荐,简单来讲:给用户推荐和他之前喜欢的物品相似的物品。

通过对于获取到的同现矩阵和用户评分向量相乘来得到这个推荐向量。
- 基于全量数据的统计,产生同现矩阵
- 体现商品间的关联性
- 每件商品都有自己对其他全部商品的关联性(每件商品的特征)
- 用户评分向量体现的是用户对于一些商品的的评分
- 任一商品需要:
- 用户评分向量乘以基于该商品的其他商品关联值
- 求和得出针对该商品的推荐向量
- 排序取出topN即可

具体实现:
部分数据集:
item_id user_id action vtime
i161 u2625 click 15:03:00
i161 u2626 click 22:40:00
i161 u2627 click 19:09:00
i161 u2628 click 21:35:00
i161 u2629 click 16:33:00
i161 u2630 click 18:45:00
i161 u2631 click 16:57:00
i161 u2632 click 21:58:00
i161 u2633 click 22:41:00
i161 u2634 click 13:30:00
公共客户端启动类:
public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step1");
job.setJarByClass(Step1.class);
job.setMapperClass(Step1_Mapper.class);
job.setReducerClass(Step1_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(paths.get("Step1Input")));
Path outpath = new Path(paths.get("Step1Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
第一步实现数据的去重:
static class Step1_Mapper extends Mapper<LongWritable, Text, Text, NullWritable> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if (key.get() != 0) {
// 只要key不为0,就写入
context.write(value, NullWritable.get());
}
}
}
static class Step1_Reducer extends Reducer<Text, IntWritable, Text, NullWritable> {
protected void reduce(Text key, Iterable<IntWritable> i, Context context)
throws IOException, InterruptedException {
// 对于同一个key,也就是key相同的一组数据,只取第一个,实现去重
context.write(key, NullWritable.get());
}
}
第二步:对于数据按照用户分组,计算所有物品出现的组合列表,得到用户对于物品喜爱的得分矩阵。
static class Step2_Mapper extends Mapper<LongWritable, Text, Text, Text>{
//如果使用:用户+物品,同时作为输出key,更优
//i161,u2625,click,2014/9/18 15:03
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
// 对数据进行切分
String[] tokens=value.toString().split(",");
// 得到物品+用户+用户行为
String item=tokens[0];
String user=tokens[1];
String action =tokens[2];
Text k= new Text(user);
// 从map中获取相应的用户行为分数
Integer rv =StartRun.R.get(action);
Text v =new Text(item+":"+ rv.intValue());
context.write(k, v);
//u2625 i161:1 输出的key就是用户,所有reduce拿到的就是此处输出的用户
}
}
static class Step2_Reducer extends Reducer<Text, Text, Text, Text>{
protected void reduce(Text key, Iterable<Text> i,
Context context)
throws IOException, InterruptedException {
Map<String, Integer> r =new HashMap<String, Integer>();
//u2625
// i161:1
// i161:2
// i161:4
for(Text value :i){
String[] vs =value.toString().split(":");
// 获取商品
String item=vs[0];
// 获取用户行为评分的总和
Integer action=Integer.parseInt(vs[1]);
action = ((Integer) (r.get(item)==null? 0:r.get(item))).intValue() + action;
r.put(item,action);
}
// StringBuffer是为了解决大量拼接字符串时产生很多中间对象问题而提供的一个类
StringBuffer sb =new StringBuffer();
for(Entry<String, Integer> entry :r.entrySet() ){
sb.append(entry.getKey()+":"+entry.getValue().intValue()+",");
}
context.write(key,new Text(sb.toString()));
}
}
第三步:对物品组合列表进行计数,建立物品的同现矩阵,也就是相同的出现就作为组合出现,建立A:B 3 B:A 3 A:D 2 A:C 4这样的数据
static class Step3_Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//u3244 i469:1,i498:1,i154:1,i73:1,i162:1,
// 先使用制表符切割,将用户和商品评分分割开
String[] tokens=value.toString().split("\t");
// 分隔获取商品和评分的字符串对象
String[] items =tokens[1].split(",");
// 双重遍历,获取所有的A:B B:A商品与商品的组合
// 第一个和所有的,第二个和所有的
for (int i = 0; i < items.length; i++) {
// 遍历
String itemA = items[i].split(":")[0];
for (int j = 0; j < items.length; j++) {
String itemB = items[j].split(":")[0];
K.set(itemA+":"+itemB);
// V默认值是1
context.write(K, V);
}
}
}
}
static class Step3_Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> i,
Context context)
throws IOException, InterruptedException {
int sum =0;
// IntWritable这是按照每一组key的数据来的
for(IntWritable v :i ){
sum =sum+v.get();
}
V.set(sum);
// 输出写出
context.write(key, V);
}
}
第四步:把同现矩阵和得分矩阵相乘,获取单个商品的总得分情况,此时的数据来源有2和3两个,需要设置输入文件的路径。
这里主要是将得分矩阵和同现矩阵组合,算出乘积,迭加到用户头上,作为信息放入到此人身上。
例如:A:i100,1 B:u20,2 此时进入到reduce中处理的时候就变成map(i100,1) map(u20,2)
计算结果的时候由于每个同现矩阵的元素都要乘得分矩阵中的每个元素,并记录数据,数据格式变为(key=u20,value=i100,2),以此获取所有商品在对应用户上面的得分总和。
/**
* 无论是同现矩阵还是得分矩阵,其中共同因素就是商品
* 如果要建立两者之间相乘的结果,需要在map中以商品为key,生成需要的数据
* 同现矩阵中A做标志
* 得分矩阵中B做标志
*/
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 根据正则表达式获取,只要是含有制表符或者逗号的就切割
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
// 同现矩阵,数据形式:i100:i125 1
if (flag.equals("step3")) {
//i100:i125 1
String[] v1 = tokens[0].split(":");
String itemID1 = v1[0];
String itemID2 = v1[1];
String num = tokens[1];
//A:B 3
//B:A 3
Text k = new Text(itemID1);// 以前一个物品为key 比如i100
Text v = new Text("A:" + itemID2 + "," + num);// A:i109,1
context.write(k, v);
} else if (flag.equals("step2")) {// 用户对物品喜爱得分矩阵
//u26 i276:1,i201:1,i348:1,i321:1,i136:1,
String userID = tokens[0];
for (int i = 1; i < tokens.length; i++) {
String[] vector = tokens[i].split(":");
String itemID = vector[0];// 物品id
String pref = vector[1];// 喜爱分数
Text k = new Text(itemID); // 以物品为key 比如:i100
Text v = new Text("B:" + userID + "," + pref); // B:u401,2
context.write(k, v);
}
}
}
}
static class Step4_Reducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// A同现矩阵 or B得分矩阵
//某一个物品,针对它和其他所有物品的同现次数,都在mapA集合中
// 和该物品(key中的itemID)同现的其他物品的同现集合// 。其他物品ID为map的key,同现数字为值
Map<String, Integer> mapA = new HashMap<String, Integer>();
// 该物品(key中的itemID),所有用户的推荐权重分数。
Map<String, Integer> mapB = new HashMap<String, Integer>();
//A > reduce 相同的KEY为一组
//value:2类:
//物品同现A:b:2 c:4 d:8
//评分数据B:u1:18 u2:33 u3:22
for (Text line : values) {
String val = line.toString();
if (val.startsWith("A:")) {// 表示物品同现数字
// A:i109,1
String[] kv = Pattern.compile("[\t,]").split(
val.substring(2));
try {
mapA.put(kv[0], Integer.parseInt(kv[1]));
//物品同现A:b:2 c:4 d:8
//基于 A,物品同现次数
} catch (Exception e) {
e.printStackTrace();
}
} else if (val.startsWith("B:")) {
// B:u401,2
String[] kv = Pattern.compile("[\t,]").split(
val.substring(2));
// 评分数据B:u1:18 u2:33 u3:22
try {
mapB.put(kv[0], Integer.parseInt(kv[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
}
double result = 0;
Iterator<String> iter = mapA.keySet().iterator();//同现
while (iter.hasNext()) {
String mapk = iter.next();// itemID
int num = mapA.get(mapk).intValue(); //对于A的同现次数
Iterator<String> iterb = mapB.keySet().iterator();//评分
while (iterb.hasNext()) {
String mapkb = iterb.next();// userID
int pref = mapB.get(mapkb).intValue();
result = num * pref;// 矩阵乘法相乘计算
Text k = new Text(mapkb); //用户ID为key
// 基于A物品,其他物品的同现与评分(所有用户对A物品)乘积
Text v = new Text(mapk + "," + result);
context.write(k, v);
}
}
}
}
第五步:对于所有的用户下的商品总得分求和,不同的商品做不同的分类统计。
static class Step5_Mapper extends Mapper<LongWritable, Text, Text, Text> {
/**
* 原封不动输出,注意map的功能,虽然数据的输入是从第四步的输出得到的
* 但是进入map以后由于InputFormat类的操作,会将原数据的key转换成偏移量
* value转换成句子,所以下面才出现切割数据能够获取到所有的信息
*/
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
Text k = new Text(tokens[0]);// 用户为key
Text v = new Text(tokens[1] + "," + tokens[2]);
context.write(k, v);
}
}
static class Step5_Reducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Map<String, Double> map = new HashMap<String, Double>();// 结果
//u3 > reduce
//101, 11
//101, 12
//101, 8
//102, 12
//102, 32
for (Text line : values) {// i9,4.0
String[] tokens = line.toString().split(",");
String itemID = tokens[0];
Double score = Double.parseDouble(tokens[1]);
if (map.containsKey(itemID)) {
map.put(itemID, map.get(itemID) + score);// 矩阵乘法求和计算
} else {
map.put(itemID, score);
}
}
Iterator<String> iter = map.keySet().iterator();
while (iter.hasNext()) {
String itemID = iter.next();
double score = map.get(itemID);
Text v = new Text(itemID + "," + score);
// key为用户id
context.write(key, v);
}
}
}
第六步:实现排序获取top10数据
private final static Text K = new Text();
private final static Text V = new Text();
public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step6");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step6_Mapper.class);
job.setReducerClass(Step6_Reducer.class);
// 设置排序比较器
job.setSortComparatorClass(NumSort.class);
// 设置分组比较器
job.setGroupingComparatorClass(UserGroup.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat
.addInputPath(job, new Path(paths.get("Step6Input")));
Path outpath = new Path(paths.get("Step6Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step6_Mapper extends Mapper<LongWritable, Text, PairWritable, Text> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
String u = tokens[0];
String item = tokens[1];
String num = tokens[2];
PairWritable k =new PairWritable();
k.setUid(u);
k.setNum(Double.parseDouble(num));
V.set(item+":"+num);
context.write(k, V);
}
}
static class Step6_Reducer extends Reducer<PairWritable, Text, Text, Text> {
protected void reduce(PairWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int i=0;
StringBuffer sb =new StringBuffer();
for(Text v :values){
if(i==10)
break;
sb.append(v.toString()+",");
i++;
}
K.set(key.getUid());
V.set(sb.toString());
context.write(K, V);
}
}
static class PairWritable implements WritableComparable<PairWritable>{
// private String itemId;
private String uid;
private double num;
public void write(DataOutput out) throws IOException {
out.writeUTF(uid);
// out.writeUTF(itemId);
out.writeDouble(num);
}
public void readFields(DataInput in) throws IOException {
this.uid=in.readUTF();
// this.itemId=in.readUTF();
this.num=in.readDouble();
}
public int compareTo(PairWritable o) {
int r =this.uid.compareTo(o.getUid());
if(r==0){
return Double.compare(this.num, o.getNum());
}
return r;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public double getNum() {
return num;
}
public void setNum(double num) {
this.num = num;
}
}
static class NumSort extends WritableComparator{
public NumSort(){
super(PairWritable.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
PairWritable o1 =(PairWritable) a;
PairWritable o2 =(PairWritable) b;
int r =o1.getUid().compareTo(o2.getUid());
if(r==0){
return -Double.compare(o1.getNum(), o2.getNum());
}
return r;
}
}
static class UserGroup extends WritableComparator{
public UserGroup(){
super(PairWritable.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
PairWritable o1 =(PairWritable) a;
PairWritable o2 =(PairWritable) b;
return o1.getUid().compareTo(o2.getUid());
}
}
6. 小结
这一节主要是学习实践了三个例子单词统计(wordCount)、天气、好友推荐,总的来说都是做的wordcount,所有的都是在做wordcount,大致相同,其中天气是稍微复杂一点,因为涉及到自定比较器,分区器,以及分组比较器,这都是因为获取到的数据需要分组的问题,所以才会遇到这样的问题,其实所有的问题转换一下都可以得到wordcount,多数的reduce方法就是在做wordcount操作,这些都是取决于map中映射的数据是如何设定的,以及数据的分组是按照什么进行的,原语:一组数据对应一个reduce方法,相同的key为一组调用一次reduce方法,在reduce方法中迭代计算。上述的例子都是按照分组来做reduce,其中单词统计,为什么能够统计到单词,这是因为在map中,我们使用单词来做reduce输入的key,这样,只要是单词,就会被计算,单纯的相加。上述例子具体可以看代码。
还有三个算法的实现,pagerank谷歌提出的算法,用作网页排名的算法,利用hadoop的离线计算在windows本地可以跑起来获取到数据,每一次的迭代都是看入链与出链,经过多次的迭代,通过设定一个标准的差值来获取迭代的差值趋近于设定的标准差即完成网页的排名。设计到数学的运算,其中主要是实现对数据的map映射,以及在reduce中如何对数据进行处理之后判断再次迭代计算。然后就TFIDF,对单词词频的逆出现频率的计算,以此来判定对于一系列文本文件中的某个词对于文件的重要程度。主要是去重,依据提出的算法进行每一步数据的分组,实现垂直的数据合并计算,最后依据公式得出最后的每个词所占据的重要程度值。最后是介绍物品的协同过滤算法ItemCF,这里主要是对于我们日常的购物过程中产生的对于一件商品的行为,对商品的行为打分,以此获取到需要给你推荐什么样的商品,主要是计算评分矩阵以及同现矩阵,最后依据同现矩阵与评分矩阵得出最后该用户对于每一件商品的总得分,最后实现商品的实时推荐。
大数据学习加油!
