大数据hadoop学习【13】-----通过JAVA编程实现对MapReduce的数据进行去重目录
之前的博客中,林君学长带大家了解了什么是MapReduce以及它的用途,并进行了一个简单的例子实现对词频的统计;本次博客,我们将深入了解MapReduce,并通过java编程实现对文件数据中数据的去重,一起看步骤吧!
一、数据准备
1、ubuntu文件系统中准备对应数据文件
1)、在对应位置创建file1.txt文件,并写入相关数据:文件中的每行都是一个数据
(1)、创建file1.txt文件,并打开
cd ~/lenovo/data
touch file1.txt
gedit file1.txt
其中 ~/lenovo/data为林君自己创建的文件夹
(2)、写入文件内容如下所示:
2020-4-1 a
2020-4-2 b
2020-4-3 c
2020-4-4 d
2020-4-5 a
2020-4-6 b
2020-4-7 c
2020-4-3 c
2)、在相同位置创建file2.txt文件,并写入数据,两个文件中的数据应该要有相同的和不同的,且文件中的每行都是一个数据
(1)、创建file2.txt文件,并打开
touch file2.txt
gedit file2.txt
(2)、写入文件内容如下所示:
2020-4-1 b
2020-4-2 a
2020-4-3 b
2020-4-4 d
2020-4-5 a
2020-4-6 c
2020-4-7 d
2020-4-3 c
2、运行hadoop
1)、终端输入以下命令运行hadoop
start-dfs.sh
2)、查看hadoop是否成功运行
jps
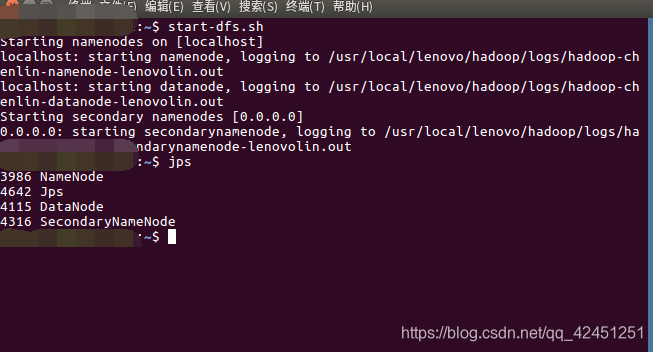
出现以上4个节点则为成功运行!
3、将文件上传至hadoop文件系统
1)、在hdfs文件系统中创建file1目录用来存放我们上传的文件

hdfs dfs -mkdir /user/hadoop/file1
2)、将file1.txt文件上传至hdfs文件系统中的file1目录
hdfs dfs -put ~/lenovo/data/file1.txt /user/hadoop/file1
3)、将file2.txt文件上传至hdfs文件系统中的file1目录
hdfs dfs -put ~/lenovo/data/file2.txt /user/hadoop/file1
4)、查看文件是否上传成功
hdfs dfs -ls /user/hadoop/file1
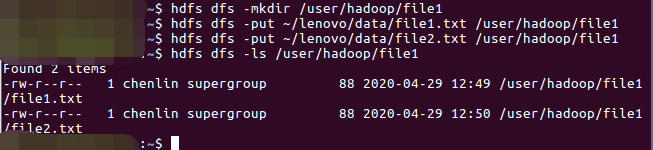
5)、查看文件内容是否一致
hdfs dfs -cat /user/hadoop/file1/file1.txt
hdfs dfs -cat /user/hadoop/file1/file2.txt

二、编写java程序
1、打开eclipse,编写数据去重的java代码
数据去重实例的最终目的是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台Reduce机器,无论这个数据出现多少次,只要在最终的结果中输出一次就行了。具体就是Reduce的输入应该以数据作为Key,而对value-list则没有要求。当Reduce接收到一个<key,value-list>时就直接将Key复制输出的Key中,并将value设置成空值。
1)、新建类DataDedup ,其中java代码如下所示:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class DataDedup {
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行数据
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
public static class Reduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: datadedup <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "data dedup");
job.setJarByClass(DataDedup.class);
job.setNumReduceTasks(1);//设置reduce输入文件一个,方便查看结果,如设置为0就是不执行reduce,map就输出结果
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在MapReduce流程中,Map的输出<Key,value>经过shuffle过程聚集成<key,value-list>后会被交给Reduce。所以从设计好的Reduce输入可以反推出Map的输出的Key应为数据,而value为任意值。继续反推,Map输出的Key为数据。而在这个实例中每个数据代表输入文件中的一行内容,所以Map阶段要完成的任务就是在采用Haodoop默认的作业输入方式之后,将value设置成Key,并直接输出(输出中的value任意)。Map中的结果经过shuffle过程之后被交给reduce。在Reduce阶段不管每个Key有多少个value,都直接将输入的Key复制为输出的Key,并输出就可以了(输出中的value被设置成空)
2)、运行,测试代码没有问题
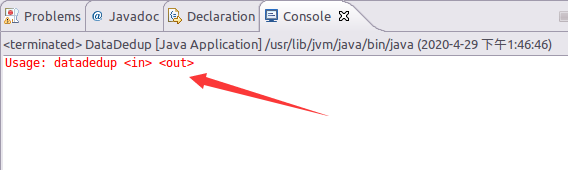
控制台出现如上显示则代码没有问题!
2、将java文件打包成jar
1)、按照如下截图步骤镜像jar打包

2)、选择JAR file

3)、选择导出的类和导出路径
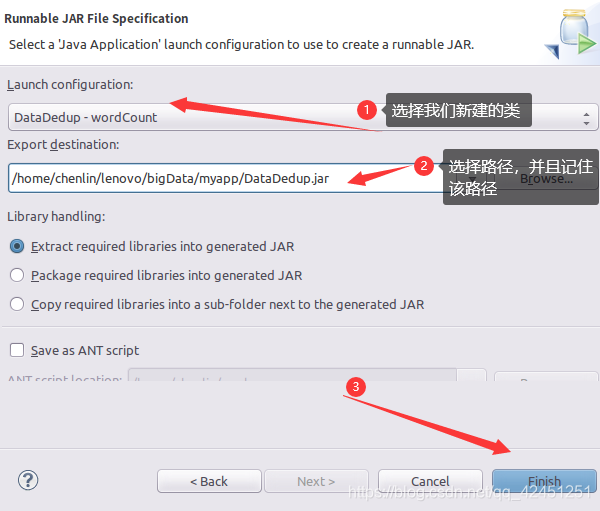
4)、点击ok
5)、导出成功
出现finished则为导出成功!
6)、找到对应路径,查询该包是否成功导出
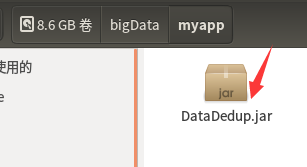
出现以上jar包,则导出成功,然后关闭eclipse
三、结果测试
1、终端运行jar包
1)、终端输入如下命令运行我们导出的jar包
hadoop jar ~/lenovo/bigData/myapp/DataDedup.jar /user/hadoop/file1 /user/hadoop/output2
提示: 路径 /user/hadoop/output2中的output2不用我们创建,该命令会自动帮我们创建的,但我们输入的output2是要保证hdfs中没有与之相同的名称哦,不然会报错的,其中 /user/hadoop/file1是我们创建好的保存测试文件的目录哦!
2)、出现如下界面则为成功运行
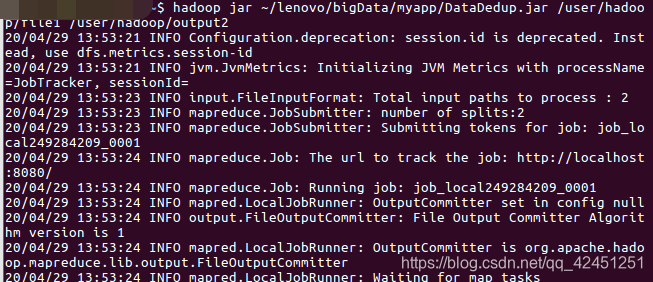

2、查看运行结果
1)、终端输入以下命令查看我们去重的结果
hdfs dfs -cat /user/hadoop/output2/*
2)、查看结果如下所示:

3、运行结果分析
1)、最开始的两个文件的数据如下所示:
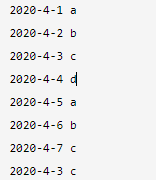
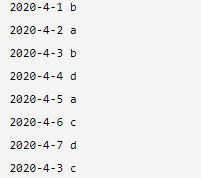
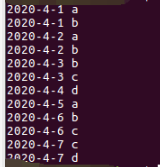
上面的左边为file1.txt,中间为file2.txt,右边为最终运行的结果
2)、在上面的结果中我们可以看出,运行出来的结果将我们上面两个文件的结果相结合,然后去除掉了重复元素,只保留了相同的其中一个
3)、除此之外,该代码还实现了对数据的排序,因为文件中再末尾的数据2020-4-3 c 在最终的运行结果中通过排序在上面去了哦!
4)、需要注意的是:如果要再次运行DataDedup.jar,需要首先删除HDFS中的output2目录,否则会报错
4、实验结束,关闭hadoop
stop-dfs.sh
以上就是本次博客的全部内容啦,通过对本次博客的阅读,希望小伙伴理解如何通过java对MapReduce的数据进行操作,进而理解原理,这样以后的编程中,就可以通过原理编程,而不是面向百度编程!
遇到问题的小伙伴记得留言评论哦,林君学长看到会为大家解答的,这个学长不太冷!
陈一月的又一天编程岁月^ _ ^
