通过编程实现数据去重排序并导出jar在终端运行
本次实验中创建的class是在上一次wordcount中完成的 (因此导入的jar与上次一致) 可参考那篇博客导包:
题目内容
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
输入如下所示:
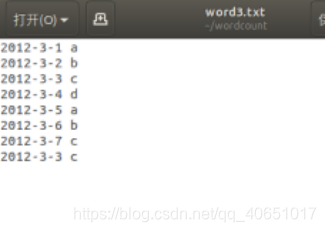
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
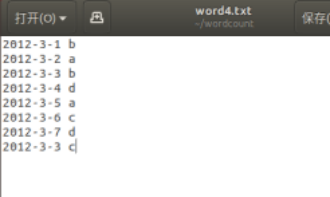
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
输出如下所示:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
创建word3、word4
本次实验将继续在wordcount文件夹中完成
打开上次创建的wordcount文件夹
创建word3、word4 写入内容
vim word3.txt
vim word4.txt
启动hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
在hdfs文件系统上创建input2
扫描二维码关注公众号,回复:
11197318 查看本文章

hdfs dfs -mkdir /user/hadoop/input2
将word3、word4上传到input2中
hdfs dfs -put ~/wordcount/word3.txt /user/hadoop/input2
hdfs dfs -put ~/wordcount/word4.txt /user/hadoop/input2
查看是否上传成功
hdfs dfs -ls /user/hadoop/input2
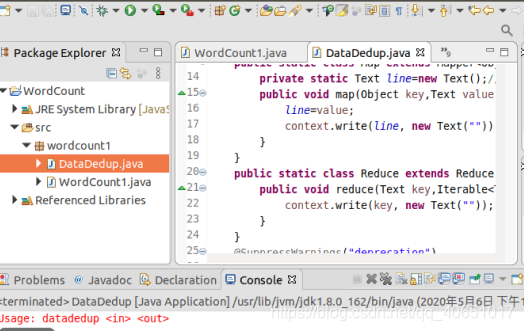
打开eclipse编写代码
代码如下:
package wordcount1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class DataDedup {
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行数据
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
public static class Reduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: datadedup <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "data dedup");
job.setJarByClass(DataDedup.class);
job.setNumReduceTasks(1);//设置reduce输入文件一个,方便查看结果,如设置为0就是不执行reduce,map就输出结果
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
结果图:
导出jar
进入hadoop目录(前面我们已经启动了hadoop)
cd /usr/local/hadoop
运行DataDedup.jar
hadoop jar ~/wordcount/DataDedup.jar /user/hadoop/input2 /user/hadoop/output2

查看output2文件
hdfs dfs -cat /user/hadoop/output2/*
通过结果图课发现word3、word4中的重复数据已经被去除并排序
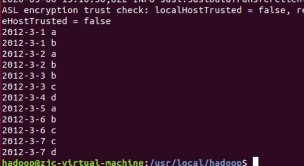
实验目的达到,关闭hadoop
./sbin/stop-dfs.sh
分享到此结束啦!!!

