文章目录
- 一、MapReduce编程实例
- 1.自定义对象序列化
- 需求分析
- 报错:Exception in thread "main" java.lang.IllegalArgumentException: Wrong FS: hdfs://192.168.17.10:9000/workspace/flowStatistics/output, expected: file:///
- 解答
- 2.数据去重
- 3.数据排序、二次排序
- 4.自定义分区
- 5.计算出每组订单中金额最大的记录
- 多文件输入输出、及不同输入输出格式化类型
- 8.join操作
- 9.**计算出用户间的共同好友**
- 二、MapReduce理论基础
- 三、Hadoop、Spark学习路线及资源收纳
- 四、MapReduce书籍推荐
- 五、MapReduce实战系统学习流程
- 词频统计
- 数据去重
- 数据排序
- 求平均值、中位数、标准差、最大/小值、计数
- 分组、分区
- 数据输入输出格式化
- 多文件输入、输出
- 单表关联
- 多表关联
- 倒排索引
- TopN
- PeopleRank算法实现
- 推荐系统——协同过滤算法实现
- 六、数据
- 七、关于我
这里放一个我学习MapReduce的编程实例项目吧,本来是想把这些分开写成多篇文章的,能够详细叙述我学习过程中感想。但无奈,时间不够,只好在Github上创建了该项目,在代码中由较为详细的注释,我想也足够了吧。
josonle/MapReduce-Demo
该项目有些题目是参考了网上几篇博客,但代码实现是本人实现的。其次,所谓的MapReduce学习流程是参照老师上课所讲的PPT上的流程【某985大数据课程PPT】,我想老师以这样的流程授课肯定是有道理的。项目中也放了老师提供的几个参考Demo文件。
该项目还在更新中,有些代码还没实现,慢慢来吧。
版权声明:本文为博主原创文章,未经博主允许不得转载(https://blog.csdn.net/lzw2016/)
一、MapReduce编程实例
1.自定义对象序列化
需求分析
需要统计手机用户流量日志,日志内容实例:
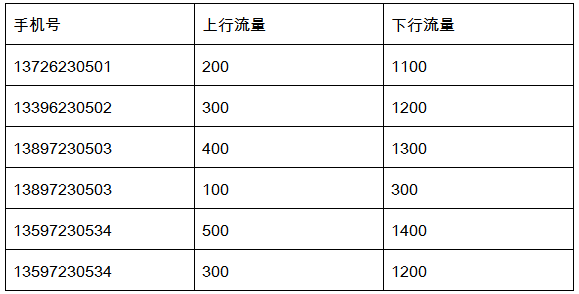
要把同一个用户的上行流量、下行流量进行累加,并计算出综合 。例如上面的13897230503有两条记录,就要对这两条记录进行累加,计算总和,得到:13897230503,500,1600,2100
报错:Exception in thread “main” java.lang.IllegalArgumentException: Wrong FS: hdfs://192.168.17.10:9000/workspace/flowStatistics/output, expected: file:///
解决:1、将core-site.xml 和hdfs-site.xml拷贝到项目里去就可以,原因是访问远程的HDFS 需要通过URI来获得FileSystem
2、在项目中,Configuration对象设置fs.defaultFS 【推荐这个,**大小写别拼错,我就是拼错了找了半天**】
String namenode_ip = "192.168.17.10";
String hdfs = "hdfs://"+namenode_ip+":9000";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfs);
解答
一、正常处理即可,不过在处理500 1400 这种时灵活变通一下即可
public static class FlowMapper extends Mapper<Object, Text, Text, Text>{
public void map(Object key,Text value,Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split("\t");
Text phone = new Text(strs[0]);
Text flow = new Text(strs[1]+"\t"+strs[2]);
context.write(phone, flow);
}
}
public static class FlowReducer extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException {
int upFlow = 0;
int downFlow = 0;
for (Text value : values) {
String[] strs = value.toString().split("\t");
upFlow += Integer.parseInt(strs[0].toString());
downFlow += Integer.parseInt(strs[1].toString());
}
int sumFlow = upFlow+downFlow;
context.write(key,new Text(upFlow+"\t"+downFlow+"\t"+sumFlow));
}
}
二、自定义一个实现Writable接口的可序列化的对象Flow,包含数据形式如 upFlow downFlow sumFlow
public static class FlowWritableMapper extends Mapper<Object, Text, Text, FlowWritable> {
public void map(Object key,Text value,Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split("\t");
Text phone = new Text(strs[0]);
FlowWritable flow = new FlowWritable(Integer.parseInt(strs[1]),Integer.parseInt(strs[2]));
context.write(phone, flow);
}
}
public static class FlowWritableReducer extends Reducer<Text, FlowWritable, Text, FlowWritable>{
public void reduce(Text key,Iterable<FlowWritable> values,Context context) throws IOException, InterruptedException {
int upFlow = 0;
int downFlow = 0;
for (FlowWritable value : values) {
upFlow += value.getUpFlow();
downFlow += value.getDownFlow();
}
context.write(key,new FlowWritable(upFlow,downFlow));
}
}
public static class FlowWritable implements Writable{
private int upFlow,downFlow,sumFlow;
public FlowWritable(int upFlow,int downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow+downFlow;
}
public int getDownFlow() {
return downFlow;
}
public void setDownFlow(int downFlow) {
this.downFlow = downFlow;
}
public int getUpFlow() {
return upFlow;
}
public void setUpFlow(int upFlow) {
this.upFlow = upFlow;
}
public int getSumFlow() {
return sumFlow;
}
public void setSumFlow(int sumFlow) {
this.sumFlow = sumFlow;
}
// writer和readFields方法务必实现,序列化数据的关键
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
upFlow = in.readInt();
downFlow = in.readInt();
sumFlow = in.readInt();
}
@Override
public String toString() {
// TODO Auto-generated method stub
return upFlow+"\t"+downFlow+"\t"+sumFlow;
}
}
注意: 要根据具体情况在job中设置Mapper、Reducer类及输出的key、value类型
具体见代码
2.数据去重
需求分析
需求很简单,就是把文件中重复数据去掉。比如说统计类似如下文件中不包含重复日期数据的日期
2017-02-14 1
2016-02-01 2
2017-07-10 3
2016-02-26 4
2015-01-19 5
2016-04-29 6
2016-05-10 7
2015-11-20 8
2017-05-23 9
2014-02-26 10
解答思路
只要搞清楚了MR的流程这个就很简单,reducer的输入类似<key3,[v1,v2,v3…]>,这个地方输入的key3是没有重复值的。所以利用这一点,Mapper输出的key保存日期数据,value置为空即可 【这里可以使用NullWritable类型】
还有就是,不一定是日期去重,去重一行数据也是如此,key保存这一行数据即可
public static class DateDistinctMapper extends Mapper<Object, Text, Text, NullWritable> {
public void map(Object key, Text value, Context context )
throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
Text date = new Text(strs[0]);//取到日期作为key
context.write(date, NullWritable.get());
}
}
public static class DateDistinctReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
public void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
3.数据排序、二次排序
需求分析
这一类问题很多,像学生按成绩排序,手机用户流量按上行流量升序,下行流量降序排序等等
-
日期计数升序排序
-
日期计数降序排序
//日期 日期出现的次数 2015-01-27 7 2015-01-28 3 2015-01-29 7 2015-01-30 6 2015-01-31 7 2015-02-01 15 2015-02-02 10 2015-02-03 9 2015-02-04 12 2015-02-05 14 -
手机用户流量按上行流量升序,下行流量降序排序
解答思路
MapReduce是默认会对key进行升序排序的,可以利用这一点实现某些排序
- 单列排序
- 升序还是降序排序
- 可以利用Shuffle默认对key排序的规则;
- 自定义继承WritableComparator的排序类,实现compare方法
- 二次排序
- 实现可序列化的比较类WritableComparable,并实现compareTo方法(同样可指定升序降序)
日期按计数升序排序
public static class SortMapper extends Mapper<Object, Text, IntWritable, Text> {
private IntWritable num = new IntWritable();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split("\t");
num.set(Integer.parseInt(strs[1]));
// 将次数作为key进行升序排序
context.write(num, new Text(strs[0]));
System.out.println(num.get()+","+strs[0]);
}
}
public static class SortReducer extends Reducer<IntWritable, Text, Text, IntWritable> {
public void reduce(IntWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
// 排序后再次颠倒k-v,将日期作为key
System.out.println(value.toString()+":"+key.get());
context.write(value, key);
}
}
}
日期按计数降序排序
实现自定义的排序比较器,继承WritableComparator类,并实现其compare方法
public static class MyComparator extends WritableComparator {
public MyComparator() {
// TODO Auto-generated constructor stub
super(IntWritable.class, true);
}
@Override
@SuppressWarnings({ "rawtypes", "unchecked" }) // 不检查类型
public int compare(WritableComparable a, WritableComparable b) {
// CompareTo方法,返回值为1则降序,-1则升序
// 默认是a.compareTo(b),a比b小返回-1,现在反过来返回1,就变成了降序
return b.compareTo(a);
}
所使用的Mapper、Reducer同上面升序排序的,其次,要在main函数中指定自定义的排序比较器
job.setSortComparatorClass(MyComparator.class);
手机用户流量按上行流量升序,下行流量降序排序
同第一个实例类似,要自定义对象序列化,同时也要可比较,实现WritableComparable接口,并实现CompareTo方法
我这里是将之前统计好的用户流量数据作为输入数据
public static class MySortKey implements WritableComparable<MySortKey> {
private int upFlow;
private int downFlow;
private int sumFlow;
public void FlowSort(int up, int down) {
upFlow = up;
downFlow = down;
sumFlow = up + down;
}
public int getUpFlow() {
return upFlow;
}
public void setUpFlow(int upFlow) {
this.upFlow = upFlow;
}
public int getDownFlow() {
return downFlow;
}
public void setDownFlow(int downFlow) {
this.downFlow = downFlow;
}
public int getSumFlow() {
return sumFlow;
}
public void setSumFlow(int sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
upFlow = in.readInt();
downFlow = in.readInt();
sumFlow = in.readInt();
}
@Override
public int compareTo(MySortKey o) {
if ((this.upFlow - o.upFlow) == 0) {// 上行流量相等,比较下行流量
return o.downFlow - this.downFlow;// 按downFlow降序排序
} else {
return this.upFlow - o.upFlow;// 按upFlow升序排
}
}
@Override
public String toString() {
// TODO Auto-generated method stub
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
}
public static class SortMapper extends Mapper<Object, Text, MySortKey, Text> {
Text phone = new Text();
MySortKey mySortKey = new MySortKey();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] lists = value.toString().split("\t");
phone.set(lists[0]);
mySortKey.setUpFlow(Integer.parseInt(lists[1]));
mySortKey.setDownFlow(Integer.parseInt(lists[2]));
context.write(mySortKey, phone);// 调换手机号和流量计数,后者作为排序键
}
}
public static class SortReducer extends Reducer<MySortKey, Text, Text, MySortKey> {
public void reduce(MySortKey key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
System.out.println(value.toString()+","+key.toString());
context.write(value, key);// 再次把手机号和流量计数调换
}
}
}
4.自定义分区
需求分析
还是以上个例子的手机用户流量日志为例,在上个例子的统计需要基础上添加一个新需求:按省份统计,不同省份的手机号放到不同的文件里。
例如137表示属于河北,138属于河南,那么在结果输出时,他们分别在不同的文件中。
解答思路
挺简单的,看过我之前结合源码解读MapReduce过程的话,就知道这其实就是一个分区的问题。定义自己的分区规则,一个分区会对应一个reduce,会输出到一个文件。
而你需要做的就是基础partitioner类,并实现getPartition方法,其余过程同第一个例子
// 自定义分区类
public static class PhoneNumberPartitioner extends Partitioner<Text, FlowWritable> {
private static HashMap<String, Integer> numberDict = new HashMap<>();
static {
numberDict.put("133", 0);
numberDict.put("135", 1);
numberDict.put("137", 2);
numberDict.put("138", 3);
}
@Override
public int getPartition(Text key, FlowWritable value, int numPartitions) {
String num = key.toString().substring(0, 3);
// 借助HashMap返回不同手机段对应的分区号
// 也可以直接通过if判断,如
// 根据年份对数据进行分区,返回不同分区号
// if (key.toString().startsWith("133")) return 0 % numPartitions;
return numberDict.getOrDefault(num, 4);
}
}
注意: main函数中要指定自定义分区类,以及Reducer task数量(一个分区对应一个reduce任务,一个Reduce任务对应一个输出文件)
// 设置分区类,及Reducer数目
job.setPartitionerClass(PhoneNumberPartitioner.class);
job.setNumReduceTasks(4);

增加ReduceTask数量可看到生成的文件数也增加了,不过文件内容为空
5.计算出每组订单中金额最大的记录
需求分析
有如下订单数据:
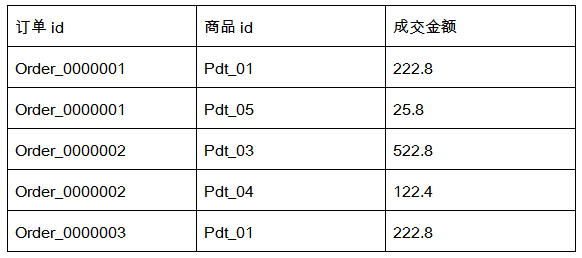
需要求出每一个订单中成交金额最大的一笔交易。
思路解答
实际上是求最大值、最小值的问题,一拿到题,大概会冒出两种思路吧
- 先排序(升序),Reduce端取第一条就是最小值,最后一条是最大值
- 不排序,在Reduce端不断循环作比较,也可以求得最值
但问题还涉及到每一个订单中的最大值,这就是分组的问题。比如说这里,同一订单号视为一组,在一组中找最大
先定义一个可序列化且可比较的对象Pair,用来存order_id,amount(只涉及这两个变量)。Mapper端输出类似
| Key2 | Value2 |
|---|---|
| {order_0000001,222.8} | null |
| {order_0000001,25.8} | null |
| {order_0000002,522.8} | null |
| {order_0000002,122.4} | null |
| {order_0000003,222.8} | null |
通过Pair中的order_id分组,因为Pair又是可比较,设置同一组按照amount降序排序。然后在Reduce端取第一个key-value对即可
Reduce端输入k-v类似下表:
| Key3 | Value3 |
|---|---|
| {order_0000001,[222.8,25.8]} | null |
| {order_0000002,[522.8,122.4]} | null |
| {order_0000003,[222.8]} | null |
以上是排序思路,因为这里比较简单,直接在reduce端进行比较求最值更方便 【你可以自己试一下】
// 定义Pair对象
public static class Pair implements WritableComparable<Pair> {
private String order_id;
private DoubleWritable amount;
public Pair() {
// TODO Auto-generated constructor stub
}
public Pair(String id, DoubleWritable amount) {
this.order_id = id;
this.amount = amount;
}
// 省略一些内容,你可以直接去文件中看
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(order_id);
out.writeDouble(amount.get());
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
order_id = in.readUTF();
amount = new DoubleWritable(in.readDouble());
}
@Override
public int compareTo(Pair o) {
if (order_id.equals(o.order_id)) {// 同一order_id,按照amount降序排序
return o.amount.compareTo(amount);
} else {
return order_id.compareTo(o.order_id);
}
}
}
// 是分组不是分区,分组是组内定义一些规则由reduce去处理,分区是由多个Reduce处理,写到不同文件中
// 自定义分组类
public static class GroupComparator extends WritableComparator {
public GroupComparator() {
// TODO Auto-generated constructor stub
super(Pair.class, true);
}
// Mapper端会对Pair排序,之后分组的规则是对Pair中的order_id比较
@Override
public int compare(WritableComparable a, WritableComparable b) {
// TODO Auto-generated method stub
Pair oa = (Pair) a;
Pair ob = (Pair) b;
return oa.getOrder_id().compareTo(ob.getOrder_id());
}
}
// Mapper类
public static class MyMapper extends Mapper<Object, Text, Pair, NullWritable> {
Pair pair = new Pair();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
pair.setOrder_id(strs[0]);
pair.setAmount(new DoubleWritable(Double.parseDouble(strs[2])));
context.write(pair, NullWritable.get());// 道理同上,以Pair作为key
System.out.println(pair.getOrder_id()+","+pair.getAmount());
}
}
// Reducer类
public static class MyReducer extends Reducer<Pair, NullWritable, Text, DoubleWritable> {
public void reduce(Pair key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(new Text(key.getOrder_id()), key.getAmount());// 已经排好序的,取第一个即可
System.out.println(key.order_id+": "+key.amount.get());
}
}
注意: main函数中要另外设置自定义的分组类 job.setGroupingComparatorClass(GroupComparator.class);
多文件输入输出、及不同输入输出格式化类型
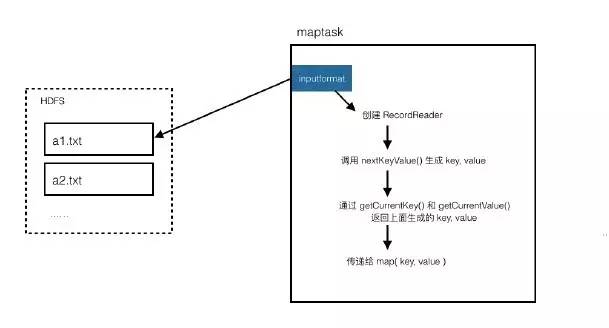
6.合并多个小文件(多文件输入输出、及不同输入输出格式化类型)
需求分析
要计算的目标文件中有大量的小文件,会造成分配任务和资源的开销比实际的计算开销还大,这就产生了效率损耗。
需要先把一些小文件合并成一个大文件。
解答思路
7.分组输出到多个文件【多文件输入输出、及不同输入输出格式化类型】
需求分析
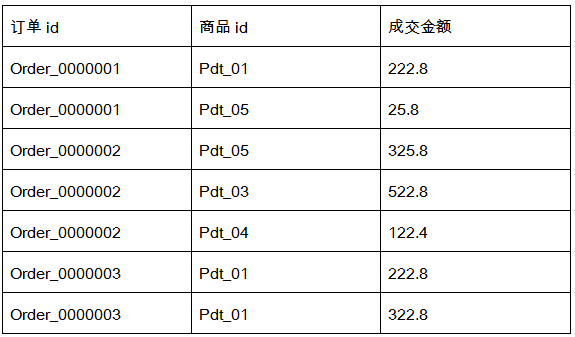
需要把相同订单id的记录放在一个文件中,并以订单id命名。
8.join操作
需求分析
有2个数据文件:订单数据、商品信息。【数据文件:product.txt,order.txt】
订单数据表order
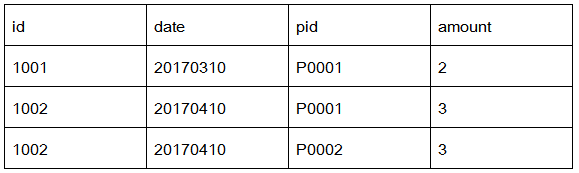
商品信息表product

需要用MapReduce程序来实现下面这个SQL查询运算:
select o.id order_id, o.date, o.amount, p.id p_id, p.pname, p.category_id, p.price
from t_order o join t_product p on o.pid = p.id
9.计算出用户间的共同好友
需求分析
下面是用户的好友关系列表,每一行代表一个用户和他的好友列表 【数据文件:friendsdata.txt】

需要求出哪些人两两之间有共同好友,及他俩的共同好友都有谁。
例如从前2天记录中可以看出,C、E是A、B的共同好友,最终的形式如下:

二、MapReduce理论基础
三、Hadoop、Spark学习路线及资源收纳
四、MapReduce书籍推荐
-
《MapReduce Design Patterns》

-
《MapReduce2.0源码分析与编程实战》

-
《Hadoop MapReduce v2 Cookbook, 2nd Edition》

五、MapReduce实战系统学习流程
词频统计
数据去重
数据排序
求平均值、中位数、标准差、最大/小值、计数
分组、分区
数据输入输出格式化
- 【源码 InputOutputFormatTest】,这个是输入不同路径下的CSV、TXT文件并分区输出到不同文件中
- 【源码 inputformat】
多文件输入、输出
单表关联
多表关联
倒排索引
TopN
PeopleRank算法实现
推荐系统——协同过滤算法实现
六、数据
见resources文件夹下,其中rand.sh脚本用于生成随机日期数据
七、关于我
你可以在途径找到我