一、JML语言
JML是针对Java的形式化描述语言,功能是以形式化的方式描述预期效果,以注释的形式书写在代码之中。
使用JML可以提供很好的模型规格描述,从而容易高效地检查、发现、纠正错误,并且提供与代码同步的文档。
语法
-
\result:方法执行后的返回值。 -
\old(expr):表示一个表达式expr在相应方法执行前的取值 -
\nonnullelements(container):表示container对象中存储的对象不会有null。 -
\type(type):返回类型type对应的类型(Class),如type(boolean)为Boolean.TYPE。TYPE是JML采用的缩略表示,等同于Java中的 java.lang.Class。 -
\typeof(expr):该表达式返回expr对应的准确类型。如\typeof(false)为Boolean.TYPE。 -
\forall:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。 -
\exists:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。 -
\sum:返回给定范围内的表达式的和。 -
\max:返回给定范围内的表达式的最大值。 -
\min:返回给定范围内的表达式的最小值。 -
\product:返回给定范围内的表达式的连乘结果。 -
requires:前置条件
-
ensures:后置条件
-
signals:抛出异常
-
normal_behavior:正常行为
-
exceptional_behavior:异常行为
-
invariant:不变式,任何可见状态下必须满足
工具链
JML相关的工具链目前不是很完善,有OpenJML、JMLUnitNG等,可以用于检查JML语法、检查程序是否满足JML规格、根据规格自动生成测试样例等。
二、SMT Solver部署结果
在经过层层困难终于完成openJML部署之后,貌似还是只弄清楚了怎么验证整个项目的JML规格,得到结果如下
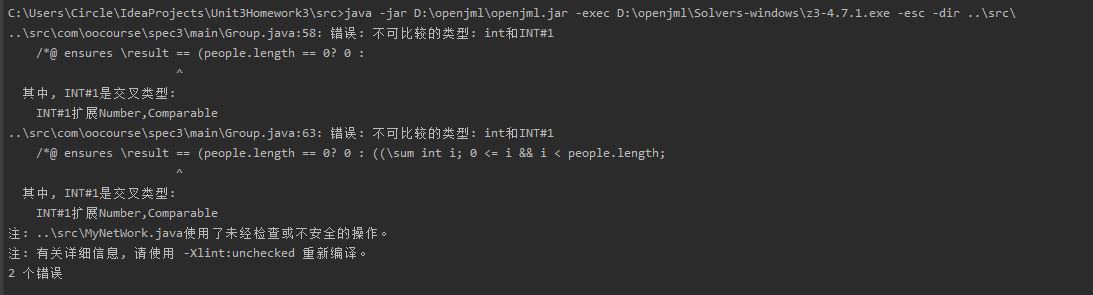
不太清楚为啥会出现这个奇怪的类型问题。
修改JML手动制造了一个拼写错误后再运行

可以看到OpenJML成功检测到了这个变量名不存在。
三、JMLUnitNG 测试结果
由于在本地弄了很久还是一直跑不起来,并且据说JMLUnitNG生成的测试效果无非就是针对少数常见的极端数据运行而已,诸如Null,INT_MAX,INT_MIN等数据,可能效果并不如手动编写JUnit测试,甚至可能不如手动编写随机样例生成进行黑盒测试,因此没有接着完成。
四、架构设计以及Bug分析
第一次作业
第一次作业时初步尝试对JML语言给出的模型进行实现,且功能也比较简单,因此按照对功能的理解直接进行了实现,isCircle采用递归dfs实现
Bug分析
没有出现Bug
第二次作业
第二次作业功能需求更为复杂,数据量大大加大,必须考虑性能问题。
因此对所有存放Person/Group的容器都采用同时使用ArrayList和id到Person/Group的HashMap来存放Person/Group的方式,保证既能快速查找id对应的Person/Group也能快速遍历,并根据数据量对容器设置了合适的初始大小。
对除了isCircle以外的所有查询都采用了预计算,在addPerson,addRelation,addtoGroup等方法执行时修改好结果,在查询时直接返回结果。具体来说,Group类中缓存了ageSum,ageSquareSum,conflictSum,relationSum,valueSum几个量,从而getAgeMean,getConflictSum,getRelationSum,getValueSum直接返回对应量则可以,getAgeVar受限于整数除法的特性,只能简化为(ageSquareSum-2*mean*ageSum+len*mean*mean)/len,考察数据范围得出中间结果应当不会溢出,因此采用该公式计算。数据值的更新,ageSum、ageSquareSum、conflictSum只需要在addtoGroup时更新一次就行了,但relationSum和valueSum的缓存导致一定的麻烦,首先addtoGroup时需要检测新增Person与原有Person的关系数,使得addtoGroup中多了一个遍历,复杂度变为O(np),np为总人数,并且addRelation会改变对应Person所在Group的状态,因此在Person中记录了所在的所有Group,并使Group类提供了addRelationEvent方法,由于addRelation需要通知所在的所有Group,复杂度变为O(ng),ng为总组数。总体来讲,相较于线性复杂度乃至平方复杂度的查询方法,预计算缓存的方式有很大的改善。
isCircle防止递归爆栈改为了不使用递归的版本,在数据范围下由于dfs做法复杂度够用且担心并查集写错,没有使用并查集实现。
Bug分析
isCircle修改后的实现存在错误将两个变量混淆使用的情况,导致该函数完全不能正常运行,结果要么进入死循环、要么抛出NoSuchElementException,但是由于既没有采用JUnit白盒测试,而且本地进行黑盒测试时不够仔细,没有注意到query_circle的缩写指令是qci而query_conflict的缩写指令才是qc,因此在自动生成测试数据时没有生成qci指令,没有发现这个严重错误。最终导致强测几乎全错,修复则是直接将对应变量名修改正确即完成了。
第三次作业
第三次作业增加了delFromGroup,因此也需要对应修改各个缓存的内容,除去conflictSum利用异或性质再取一次异或,其它几个量均直接减去对应值即可。
第三次作业主要增加了几个图论相关的查询方法,queryMinPath采用了朴素dijskra算法实现,queryBlockSum采用了逐次bfs获取对应联通块,复杂度O(n),queryStrongLinked采用每次尝试去除一个点再检查两点是否连通的暴力做法,复杂度O(n^2),borrowFrom和queryMoney则很容易实现。
Bug分析
没有功能上的Bug,但性能却是不符合要求的。
queryMinPath采用的朴素dijskra复杂度O(n^2),且qmp指令没有数据数量限制,导致了CTLE,由于总指令数目的限制,如果要进行一定量的qmp指令,则这个图要么点数很少,要么很稀疏,因此应当采用堆优化的dijskra,在使用堆优化dijskra后依旧无法完全通过测试,去除预先检测连通性,而是在算法中失败时返回不连通结果,从而降低了一定的常数才完成修复。
queryStrongLinked由于遍历过程不去除起始点和终止点,所以出现在整个图中只有两个点的时候,不会进入循环,结果完全没有做任何检测就直接返回了true的问题,修复是特判了图中只有两个点时直接返回false。
queryStrongLinked也出现CTLE问题,但原因不在于算法复杂度,虽然存在tarjan等更好的算法,但在题目所给数据范围内,暴力做法应当能够完成任务。根据JProfiler的CPU时间度量,60%的CPU时间在于HashSet.contains函数上,其中绝大多数CPU时间又在于MyPerson.hashCode函数上。因此耗时过长的原因可能在于,在bfs检测连通性的过程中使用HashSet<Person>保存访问过的节点,而MyPerson类的hashcode函数被写为返回Objects.hash(id),而Objects.hash函数有一定的时间开销,改为直接返回id后CTLE的两个数据点时间占用降低到1.2s,成功完成修复。
五、心得体会
JML语言大体与形式逻辑相关内容用到的概念相同,形式化建模的语言大多更倾向于具有更好的数学基础的书写方式,JML也不例外,JML对于规格的描述是尽可能倾向于数学性的,而与具体的代码实现不一样,但感觉上JML还是略显鸡肋,因为一般的设计架构很难忍受这么高的规格描述开发时间,规格描述相关的代码甚至比实现还要多,而对于安全性有强要求的领域来说,JML相比起主流形式化验证所使用的语言还是更为自由宽松,语法也没有那么完善,工具链也比较陈旧,强安全要求的领域可能更倾向于采取Coq、Isabelle等自成体系的形式化证明工具来完成模型安全性的证明。规格化的描述通过对前置条件和后置条件的描写,对于设计者来说,摆脱了具体实现的内容,更容易做出合理的设计,对于安全性保障来说,前置条件到后置条件这样一种推出关系,比起程序语言概念里的函数更为接近数学上的函数,即由自变量求得因变量,在此基础上更容易证明设计的正确性,测试上来说,有了明确的规格说明,容易设计出测试样例对实现进行具体的测试。