第一次作业
第一次作业的内容为不含异常格式的多项式求导,整体难度不是非常大。
程序结构分析
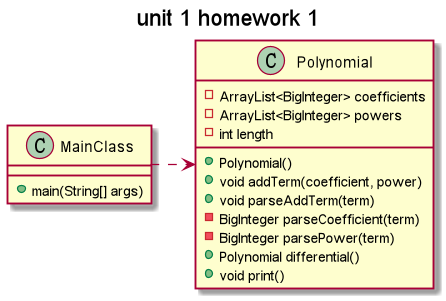
只有主类和一个多项式类,程序的大多数逻辑由多项式类进行管理。
分析与评价
因为这次作业的需求相对简单,并且输入的格式也比较固定(常数或系数*x**指数),因此程序格式相对比较简单。完成后两次作业后再来回顾,发现其实写得比较面向过程。主类负责读入,并用正则表达式匹配出每一项的字符串,再把匹配出的字符串送入Polynomial类解析。
Polynomial类则负责解析、求导等工作。它用两个ArrayList来存储每一项的系数和指数(两个ArrayList中的元素一一对应),用一个整数来存储表达式项数。首先外部调用parseAddTerm(),这个方法调用两个private的parse方法,最后用addTern()方法将项加入。解析的过程其实没有什么好说的,就是分几种情况(常数项的,有系数的,没系数的,有指数的,没指数的)用正则表达式匹配。在解析完成后,调用differential()方法进行求导,并通过print()方法打印。(当时还不知道可以通过重写toString()方法来支持输出)
这次作业的设计其实非常面向过程,基本上只是把用到的东西封装成了方法,因而拓展性很低,在第二次直接就重构了。也没有用到过多的面向对象思想,只有一个多项式类,并且这个类也只创建了原多项式和求导后多项式两个对象,有点Java版C程序的感觉。
本次作业代码量统计如下:
NUMOF LINES FILENAME
19 lines Homework1\src\MainClass.java
173 lines Homework1\src\Polynomial.java
---------------------------------------------
total : 192 lines.
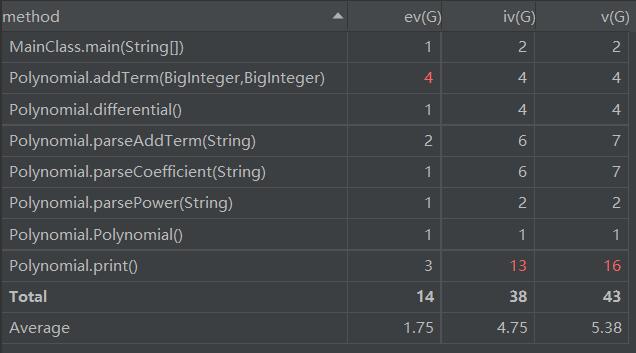
代码量不是很大,因此也比较容易管理。代码复杂度分析如下,可见除了print()外都还可以,print比较复杂是因为本次作业的优化都是在print这一步完成的。
Bug分析
如上所说,因为程序比较简单,因此没有出现明显bug,在强测中得到了100分,互测阶段也没有被发现bug。
在寻找别人的bug的时候,我采用了人工阅读代码+自动化测试相结合的方法。自动化测试采用随机生成的数据,其实自动生成的数据真的很弱,在前两次基本上没有用自动测试程序发现任何bug。在阅读代码的时候,我选取了一些最容易理解也比较容易出错的地方阅读。比如正则表达式部分,我阅读了其他同学的正则表达式,并发现一名同学在多个符号相连时会出现问题,由此发现了bug。除此之外,还发现出现的bug是当输入为常数时,有的同学会没有输出。
第二次作业
第二次作业在第一次作业的基础上增加了sin()、cos()两种三角函数项,并要求进行格式异常判断。虽然难度有所增加,但理清思路后也比较简单。
程序结构分析
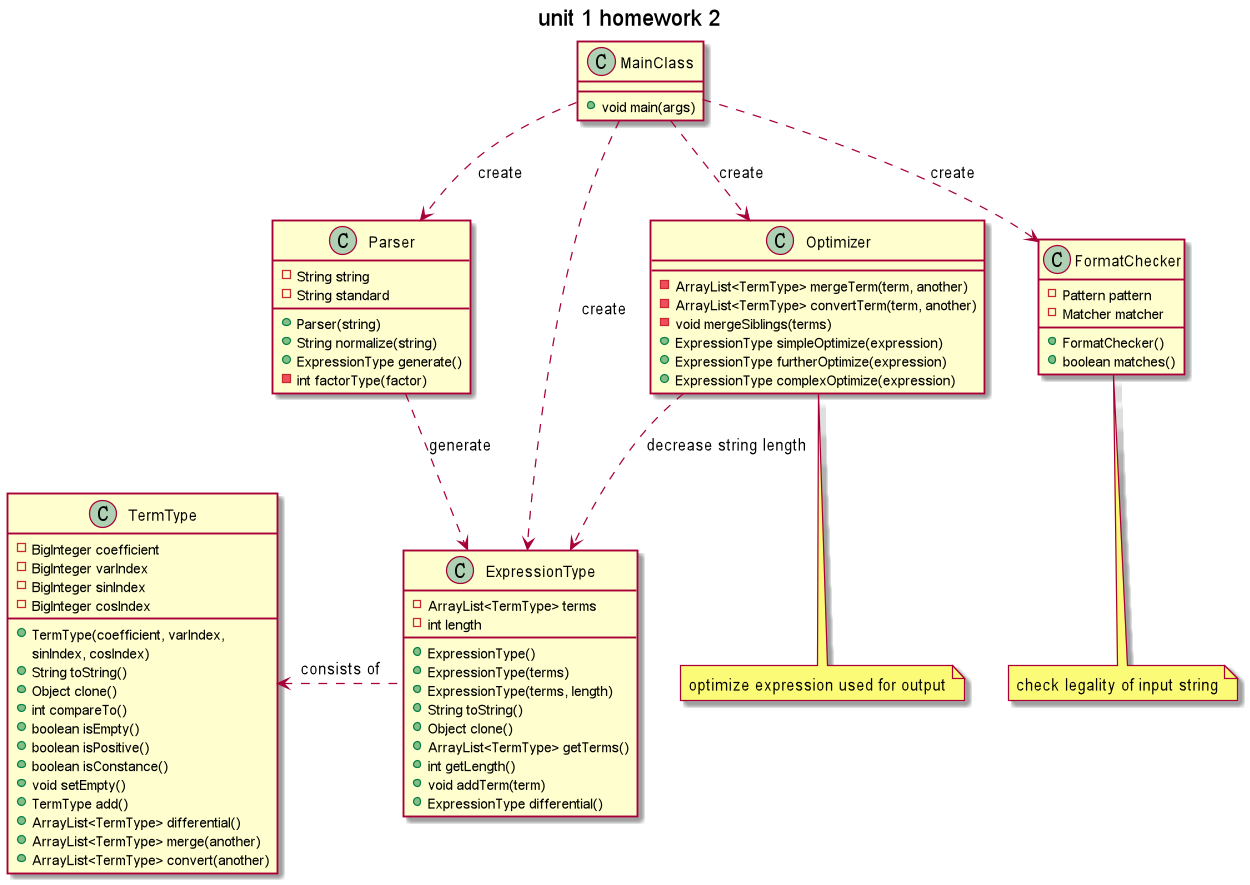
这次用到的类更多了,除了主类外,有两个类(表达式类与表达式项类)用来管理数据,有三个类用来管理行为(格式检查器类、解析器类、优化器类)。但这次仍然没有用到继承、实现等层次化设计结构。
分析与评价
这次作业增加了需求,不仅加入了三角函数因子,还要求判断格式的合法性,并且优化方式也更加灵活。
在主类获得输入后,首先将输入传到FornatChecker中判断格式,matches()直接返回和正则表达式匹配的结果。因为在指导书中给出了形式化表述,所以直接将形式化表述翻译成正则表达式,采取“用基本零件组合成复杂结构”的策略,组合出一个巨大的正则表达式,直接用于格式判断。
判断结构正确后,将字符串传入Parser()类进行解析。Parser类首先用normalize()方法将字符串标准化,采用正则表达式替换的方式,将连续多个正负号、指数运算、乘号和指数后的负号等情况分别替换为独特的形式。例如,+-+1-23*x**-45*cos(x)**-78在标准化后变成+|1+|23*x^|45*cos(x)^|78。标准化后,按照+号将表达式拆开即得每一项,按照*号把项拆开即得每一个因子。分别判断因子类型解析即可。
得到表达式并求导后,将求导得到的表达式传入Optimizer()类进行输出优化。优化主要在两个方面,第一个方面是优化a*x^b*sin(x)^(n+2)*cos(x)^m+a*x^b*sin(x)^n*cos(x)^(m+2)这一类,两者合并后即得a*x^b*sin(x)^n*cos(x)^m;第二方面是优化a*x^b*sin(x)^n*cos(x)^m-a*x^b*sin(x)^(n+2)*cos(x)^m型,合并即得a*x^b*sin(x)^n*cos(x)^(m+2)。在Optimizer类中这两种优化分别是通过simple()与further()实现的,两个方法分别对表达式的每一项进行O(N^2)的遍历,并将可合并的项合并。由于合并需要访问TermType的内部属性,因此将合并作为了TermType的方法,Optimizer类的合并方法仅仅是调用TermType类中的相应方法。最后,两个optimize()方法由complex()方法进行整合,得到较优解。
在数据存储方面,采取了四元组的存储方法。因为表达式格式比较固定,也不存在嵌套,因此四元组足以满足需求。
这一次的程序有一点面向对象的感觉了,学会了使用不同的类对行为相似的内容进行封装,也能够通过实现一些内置接口、重写某些函数来完成一些功能了。不过不足的是,Parser()、Optimizer()两个类的功能的实现完全依赖于Expression、TermType两个类的实现,耦合度比较高。
本次作业的代码量如下,由于行为的增加,这次代码量也有较大的增加,主要体现在TermType上(这也和两个合并不同项的方法有很大关系)。
NUMOF LINES FILENAME
102 lines Homework2\src\ExpressionType.java
33 lines Homework2\src\FormatChecker.java
23 lines Homework2\src\MainClass.java
110 lines Homework2\src\Optimizer.java
122 lines Homework2\src\Parser.java
287 lines Homework2\src\TermType.java
-------------------------------------------------
total : 677 lines.
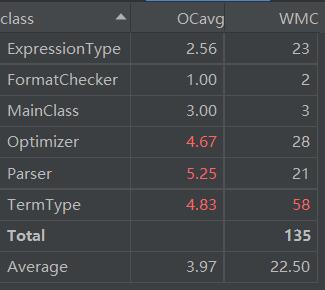
在程序复杂度方面,TermType有些过于复杂(其实也是因为两个合并方法),在解析与优化方面同样采取了比较复杂的分支结构,导致了程序较高的复杂性。
Bug分析
这次作业虽然复杂度提高了,但因为bug都在发现时被随即解决,因此也没有出现令人印象深刻的bug。在强测中除了两个点只得到了部分性能分外,其他点都得到了满分。在互测阶段也没有被发现bug。
在寻找其他人的bug时,仍然是采用阅读代码+自动评测相结合的方式。但实际上,自动评测仍然没有找到别人的bug,找到的两个bug都是通过手动构造测试用例发现的。第一个bug是一名同学的边界值设置错误,应当指数绝对值小于等于10000为合法,而这位同学判断成了小于,导致指数绝对值为10000时出错。另外一名同学的bug是因为投机而出现的,也就是当三角函数指数很大的时候,将这个三角函数因子整体舍弃。从评测方法上来看,这个方法得到的结果虽然不正确,但因为被舍弃的项太小,而无法被发现。不幸的是,这位同学没有考虑指数为负数的情况,导致出错。
直至这一次,大家仍然没有出现比较严重的bug,基本上都是一些细节上的出错。
第三次作业
第三次作业在第二次的基础上,增加了三角函数嵌套表达式的情况。因为正则表达式难以嵌套定义,因此出现了一些麻烦。
程序结构分析
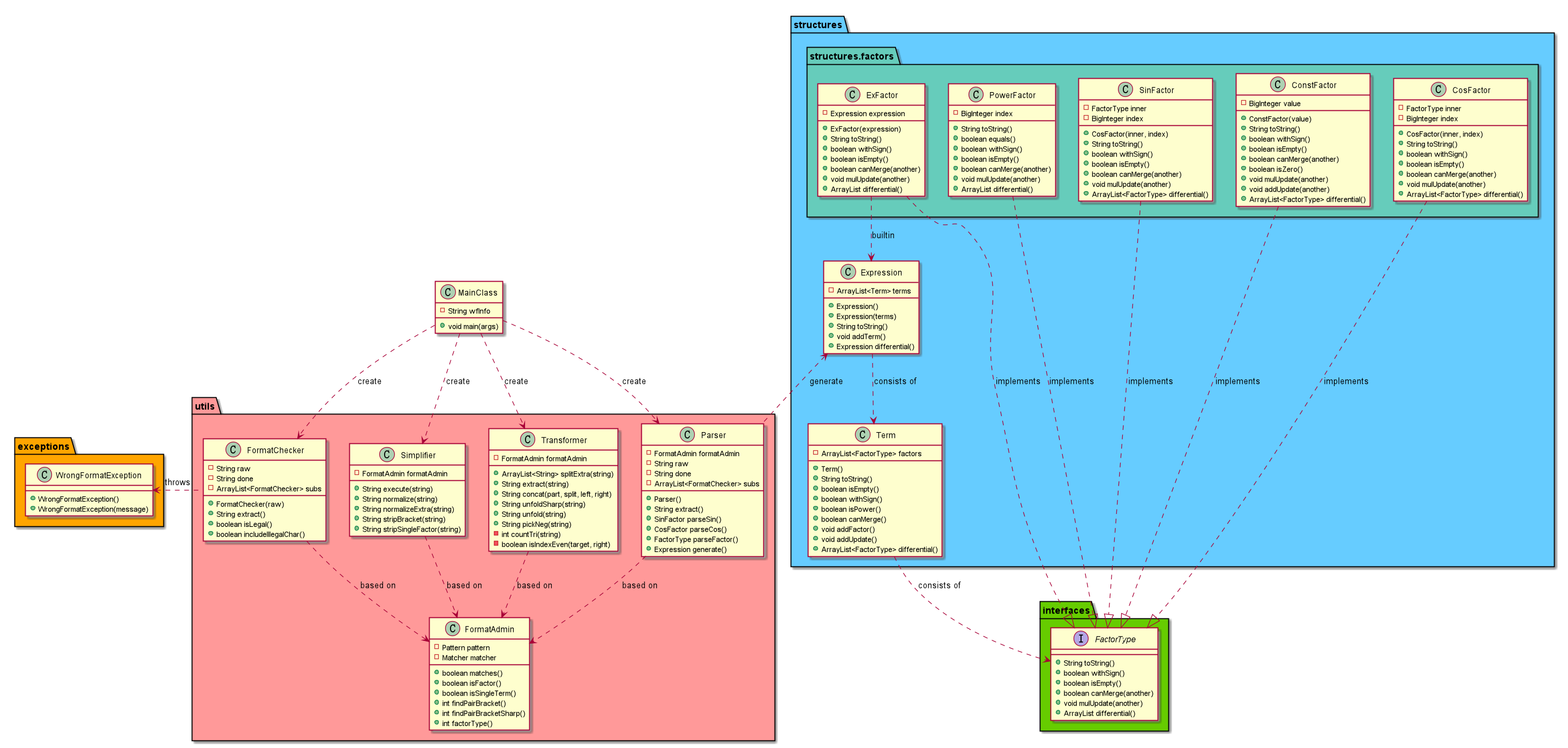
这一次作业用到了接口、异常处理等特性,并采取树状嵌套的方式来保存数据。
分析与评价
因为这次增加了嵌套,所以本程序的核心问题都在于对嵌套的处理。首先,定义了FormatAdmin类,用来管理与格式相关的各种各样可能用到的属性与方法,util包中的各种工具都基于这个类实现。在格式检查方面,仍然采用与上次相似的大型正则表达式匹配的方法,但因为嵌套的存在,需要先将最外层的括号所包含的内容替换为特殊字符,再进行匹配。这里采用的方法是,将表达式的最外层括号,从左到右标为A,B,…替换后先判断格式,然后再对每个括号里的内容继续判断格式。例如sin(cos(x**2))+(x+2)就被替换为sinA+B,再进行格式正确性的判断。由于嵌套和递归的存在,在不同层级间传递布尔值过于繁琐,因此采用了抛出异常的方式,只要判断出错便抛出异常,避免了传值可能存在的问题。
在判断格式正确后,使用Simplifier类,将其标准化并去掉多余的括号,以减少后期的递归次数。随后送入Parser类进行解析,Parser解析的方式与FormatChecker判断格式的方式类似,将括号替换后层次化地解析。在数据存储方面,定义了FactorType接口,用来同一各种因子的行为。与上次的四元组法不同的是,本次将常数项、幂函数项、三角函数项以及新加入的表达式项分开存储,从而支持嵌套。
本次作业用到了较多的面向对象编程思想,进行了层次化设计并统一了具有相同特性对象的行为,个人认为较前两次有比较大的提升。
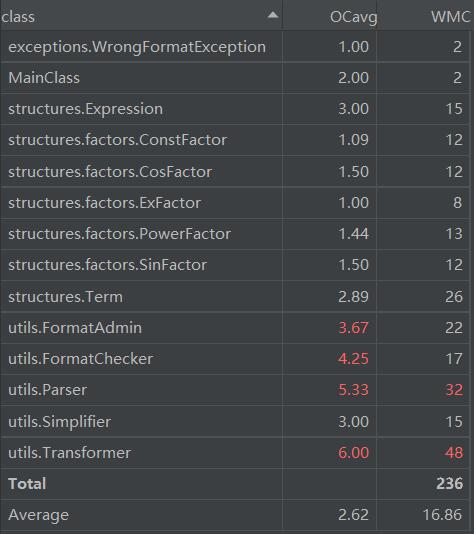
代码量统计如下,总代码量超过了1300行。除了必要的部分外,Transformer类是一个比较臃肿的类,它被用来将输入的字符串通过变形,将括号展开、符号提取,从而减少嵌套层数。现在看来这是没有必要的,设置这一个类的原因将在Bug分析一节进行说明。
NUMOF LINES FILENAME
12 lines Homework3\src\exceptions\WrongFormatException.java
19 lines Homework3\src\interfaces\FactorType.java
34 lines Homework3\src\MainClass.java
67 lines Homework3\src\structures\Expression.java
67 lines Homework3\src\structures\factors\ConstFactor.java
78 lines Homework3\src\structures\factors\CosFactor.java
53 lines Homework3\src\structures\factors\ExFactor.java
68 lines Homework3\src\structures\factors\PowerFactor.java
77 lines Homework3\src\structures\factors\SinFactor.java
114 lines Homework3\src\structures\Term.java
116 lines Homework3\src\utils\FormatAdmin.java
89 lines Homework3\src\utils\FormatChecker.java
162 lines Homework3\src\utils\Parser.java
121 lines Homework3\src\utils\Simplifier.java
261 lines Homework3\src\utils\Transformer.java
------------------------------------------------------------------
total : 1338 lines.
在程序复杂度方面,Parser类与Transformer类是比较复杂的。前者的复杂是不可避免的,因为涉及到比较复杂的字符串解析;而后者的复杂是没有必要的,可以说引入Transformer类源于本程序测试阶段的bug定位不准确造成的。
Bug分析
本次作业出现了一个比较严重的问题(虽然不能算是bug),就是在表达式嵌套层数很多的时候会运行超时。在程序测试阶段我发现了这个问题,并且在周五和周六两天的时间里一直在想办法解决这个问题。起初我认为是嵌套层数过多导致解析或求导用时过长,因此我在解析方法之后插入了打印log的语句(示意如下),输入后即刻便有输出,发现并不是因为解析缓慢。
1 Expression expression = parser.generate();
2 System.out.println("Parse done.");
3 System.out.println(expression.differential());
因此我着手于判断求导过程超时的原因。首先我从静态阅读代码的角度思考这个问题,根据我的算法,在N层嵌套时,需要调用求导方法的次数应当在N^2次左右,不应该超时。所以我十分困惑,并试图使用单步调试的方式理解问题。在单步调试进入求导方法后,每进入一层,都要卡住很久,在监视数据的一栏里也一直是collecting data。所以我依然没有找到超时的原因。在单步调试失败后,我试图在每一步求导的末尾输出已经求导得到的部分,发现每求一次导都要很久才能输出。我依然没有通过这一现象理解超时的原因。
在定位超时原因失败后,我试图从另一个角度来解决这个问题,也就是减少嵌套。因此,我写了Transformer类,用于将表达式中的括号全部展开,从而降低嵌套层数;以及将三角函数中的符号提出,从而将三角函数嵌套的表达式因子转化为普通因子。这个方法是奏效的,原本超时的多层加减法、多层乘法、多层sin等都不再超时,但当cos嵌套超过6层时依然无法得到结果。因此我在强测中错了一个点,并在互测中被hack一次。
在评测和互测结束后,我从微信群的讨论中听说,可能是toString()方法超时导致的。于是我去检查我的toString()方法,发现为了减少不必要的多重加减号,我使用了withSign()来检查字符串原本是否带有符号,而这个方法会调用toString(),导致toString()与withSign()反复互相调用多次,导致超时。在注释掉这个函数后,问题解决。
而之所以单步调试和插入print的方法没能成功定位问题的原因也在于此,因为两者都会在每一步调用toString(),这导致在表观上,每一步都运行得很慢,但实际上这并不是真实原因。这个bud的确非常难以发现,其实如果我在写代码时将求导与输出分开,也不会遇到如此棘手的问题。没能定位到TLE原因,是我这次作业的一个极大的失败,我也因此付出了比较惨痛的代价。
除了这个问题外,我也在格式判断方面有一个小bug。因为我判断格式是层次化的,因此当我遇到形如sin(- x)这样的非法表达式时,会在外层和内层都判断合法,导致格式判断错误。这个bug可以加一步正则判断,很容易就解决了。
因为以上两个问题,我在强测中WA一个点,TLE一个点,在互测中被hack一次。实在是不应该。
在寻找别人的bug时,我直接采取了自动化测试的方法。可能是因为我错了两个点的缘故,同一个room的同学程序bug都很多,轻而易举便能找出许多bug。
重构历程
这三次作业,我经历了类似一main到底→将数据与行为分别封装管理→使用包和层次化进行设计的变化。虽然基本上每次作业都在重构,但感觉收获是很大的。在最后一次重构时,我也用到了工厂模式(尽管不是非常经典的工厂模式,但思想与之相符),即在Parser类内置一个工厂,用来生产各种不同的因子,并以FactorType的统一形式返回。在重构的过程中,我感受到了面向对象思想的逐渐形成。
他人代码阅读体验
在互测过程中阅读了一些别人的代码,也clone了优秀代码仓库。发现有的人从第一次作业开始,就采用了我在第三次作业中采用的架构,感觉十分佩服。除此之外,我发现优秀的代码更容易阅读,体现在思路清晰、变量命名规范等方面,这都是我需要在今后进一步学习与巩固的。但也遇到过一些不忍直视的代码,感觉读起来很别扭。愿我们都能变成自己所向往的样子。