BUAA_OO_2020_UNIT1_Summary
第一单元的整体任务为,给出一串字符串,判定是否合乎规范,并按照一定的规则将字符串解析为表达式,并将表达式求导后的结果输出
一、程序分析
第一次作业
第一次作业较为简单,只包含带系数的幂函数项组成的表达式,并且不涉及WF判断
1. 设计思路
整体架构
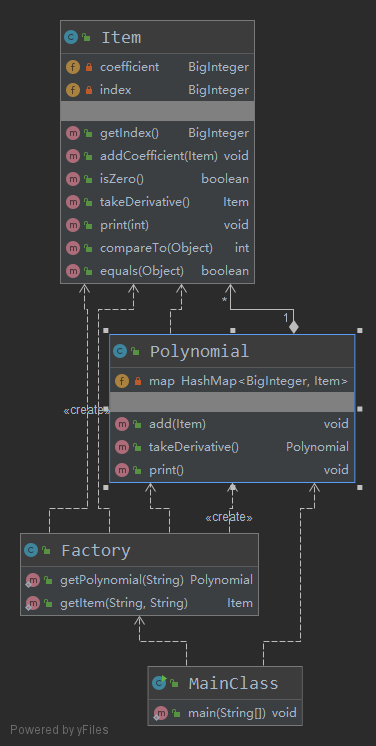
- 将带系数的幂函数抽象为类Item,内含两个BigInteger类的变量管理项和系数
- 将表达式抽象为类Polynomial,用容器HashMap管理若干项
- 使用简单工厂模式解析字符串并生成对象
输入处理
- 由于不涉及WF,将所有空白字符去掉
- 将++、-- 、+-、-+分别替换为+、+、-、-,便于处理
输出处理:Polynomial对象的print方法调用容器中每一个Item对象的print方法输出
化简
- Item的print方法中,分别对系数为1或-1、指数为1或0等情况进行特殊处理
- Polynomial的print方法中,寻找系数最大的项优先输出,使得有正项先输出正项,避免表达式开头的输出负号增加长度
UML图
2. 代码质量分析
Metrics:由于在输出部分化简,因此Item的print方法复杂度较高
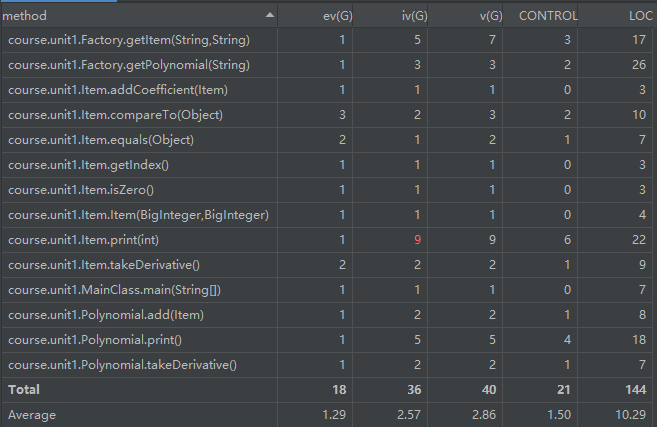
code lines:代码总行数167
扫描二维码关注公众号,回复: 9940112 查看本文章

DesigniteJava工具分析

通过以上工具的分析结果,可以看出,由于第一次作业较为简单,代码复杂度不高,耦合程度较好,方法复杂度也都较低,只有输出方法涉及化简因此复杂度较高
第二次作业
第二次作业添加了三角函数和部分判断,考虑到向后兼容,便重构了架构,使得整体架构具有较好的扩展性。另外,第二次作业中的化简部分也是一大难点
1. 设计思路
整体架构
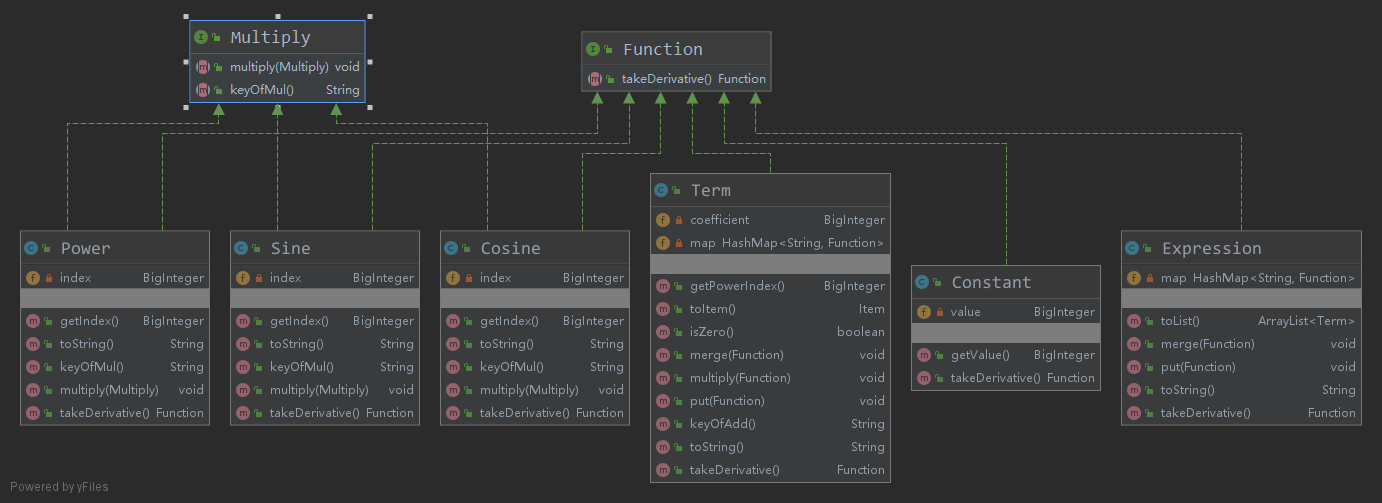
- 按层次设计6个实体类,Expression, Term, Constant, Power, Sine, Cosine,这6个类均实现Function接口,需实现求导方法takeDerivative();此外Power, Sine, Cosine需实现Multiply接口,以能够被Term对象所管理
- Expression类中使用容器HashMap管理Term对象
- Term类中使用HashMap管理实现了Multiply接口的因子对象,同时包含一个BigInteger类变量存储系数:当put常数项时,使其与系数相乘而非将其put进Map
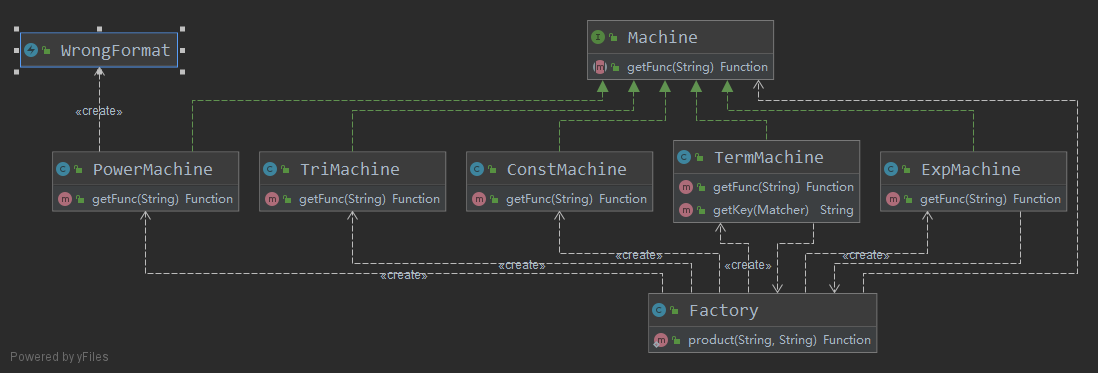
- 使用抽象工厂模式解析字符串并生成对象
- 使用深搜剪枝的方法进行深入化简
输入处理
- 按照指导书分层次构造正则表达式,判断合法后去掉空白字符,换掉连续的正负号
- 将处理后的字符串交给工厂生成对象,在生成对象时进行WF判断(如指数绝对值超过范围等等),若WF则抛出异常,否则返回生成的对象。
输出处理:
- 每一个实例类复写toString方法
- Power等因子类按照输出要求进行复写,并针对指数为0等特殊情况进行化简
- Term则将HashMap中每一个因子的toString以及系数的toString组合作为Term对象的toString,同时针对系数为1或-1等特殊情况进行化简
- Expression则将HashMap中每一个项的toString组合作为其toString,对特殊情况进行化简
化简相关
生成对象部分:在向Term的Map中put因子时,若检测到key值相同,则调用实现的multiply()方法进行合并化简;在向Expression中put项时同理进行合并化简
深搜化简部分:
将构造好的表达式的每一项,按照x的指数相同进行分类,分为(系数,sin指数,cos指数)的三元组
对于x指数相同的两个三元组,按照下面六种转化情况进行深搜剪枝化简,搜完得到的新表达式长度短于原表达式则进行替换。
① (a, m, n) + (b, m, n+2) --> (a+b, m, n) + (-b, m+2, n)
② (a, m, n) + (b, m, n+2) --> (a, m+2, n) + (a+b, m, n+2)
③ (a, m, n) + (b, m+2, n) --> (a+b, m, n) + (-b, m, n+2)
④ (a, m, n) + (b, m+2, n) --> (a, m, n+2) + (a+b, m+2, n)
⑤ (a, m, n+2) + (b, m+2, n) --> (a, m, n) + (b-a, m+2, n)
⑥ (a, m, n+2) + (b, m+2, n) --> (a-b, m, n+2) + (b, m, n)
注意设定时间阈值进行熔断:程序运行时间超过指定值时抛出异常
输出化简部分:在各个类的toString中,针对特殊情况进行化简
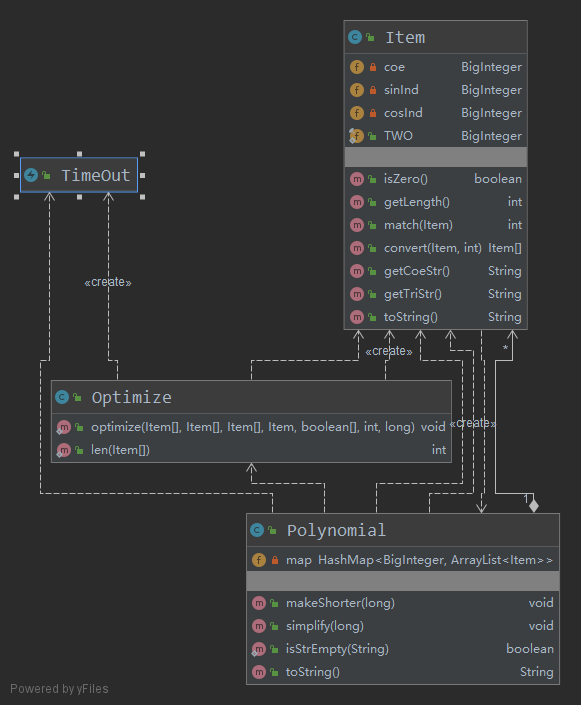
UML图:
- 数据管理部分
- 工厂部分
- 深搜化简部分
2. 代码质量分析
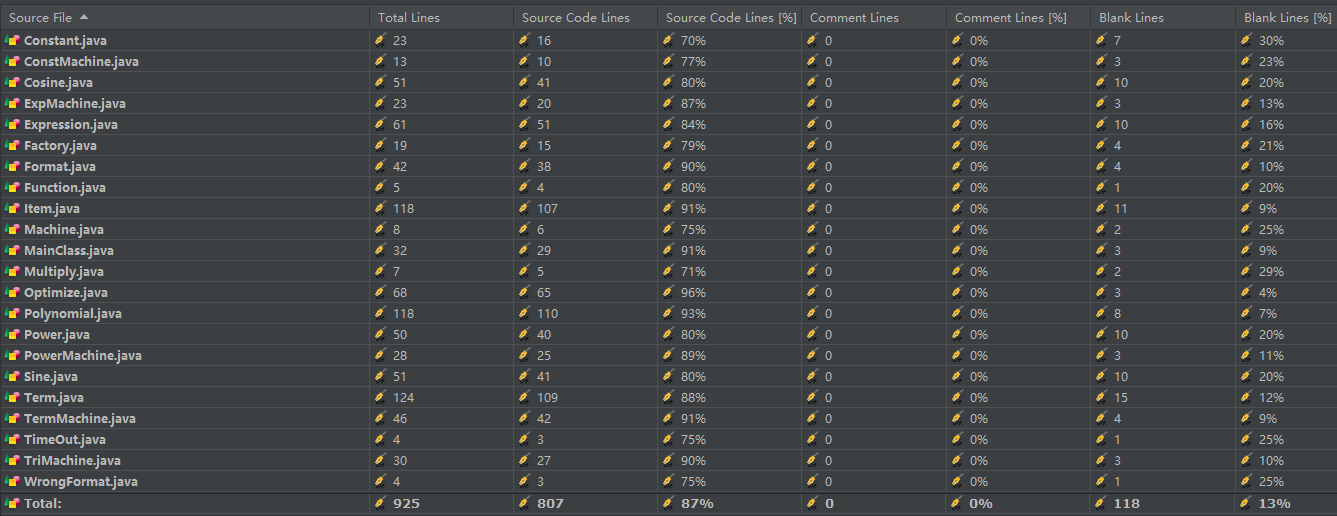
Metrics:

code lines:共807行
DesigniteJava工具分析:

通过以上工具的分析结果可以看出,由于较好地进行了类的规划和分工协作,在数据存储和处理部分的方法复杂度和类复杂度均较好。但是在深搜优化部分,由于进行了递归,方法复杂度较大。整体类之间的耦合性较好
第三次作业
第三次作业加入了嵌套因子和表达式因子,以及完全的WF判断。因此本次作业的重点在于架构设计,数据处理,对于优化,只做了较为简单的、力所能及的优化
1. 设计思路
整个架构的设计延续了第二次作业的设计,只进行了一些扩展和优化;解析字符串部分由于有嵌套因子和表达式因子的存在,扩展较多
整体架构
- 设计了
Function接口,包含Function takeDerivative()求导方法;设计了Factor接口继承了Function接口,包含了void multiply(Factor another)乘法合并方法以及String keyOfMul()方法(得到在Term的Map中的key值) - 实体类方面,在作业2的基础上增加了
Nested嵌套因子类,包含两个成员变量:private Factor outer和private Factor core,分别管理嵌套因子的外层和内层因子。同时使Expression、Constant、Nested类实现Factor接口。此外Expression类增加index变量,用来管理输入中多个相同表达式因子相乘的情况 - 延续第二次作业,采用抽象工厂模式解析输入并生成对象,增加
Format类,内置一些存储正则字符串的静态变量,和一些处理字符串的静态方法 - 为保证安全,使所有实体类实现
Serializable接口,以通过流序列化与反序列化实现对象克隆。同时增加CloneUtil类,内置一些克隆实体类对象的静态方法
- 设计了
输入处理
- 增加预处理步骤,将最外层括号内的字符串替换为"$x",并将被替换的内容存储到一个
StringList中传递下去。替换的同时检查括号匹配情况 - 延续作业二中的正则表达式字符串,增加表达式因子
($x),将原三角正则改为sin($x)的形式,判断处理后表达式是否合法:若不合法,抛出异常;否则进行去空白字符和连续正负号处理,将处理结果以及上述StringList传递给工厂生成对象 - 工厂采用递归模式生成对象,并在每一层检查字符串是否合法,以及解析的相应数据是否超过指导书的限定:若为否,则返回生成的对象;否则抛出异常
- 增加预处理步骤,将最外层括号内的字符串替换为"$x",并将被替换的内容存储到一个
输出处理:延续作业二的方式,对以下几点进行扩展
Expression作为因子时,其toString需加上外层括号;当其index不为1时,由于指导书要求表达式因子不能含有幂次,因此toString需要变为"() * () * ()..."的形式- 嵌套因子的toString为,
outer.toString().replaceAll("x", core.toString())
化简相关
- 解析输入部分:去掉外层多余嵌套括号,如将 "((((((x))))))" 化简为 "(x)"
- 生成对象部分:延续作业二的同类项合并(加或乘)化简,同时扩展一下两点,以减少不必要的嵌套
- 向Term类对象term中put一个表达式因子exp时,若exp中只包含一项t,则将t与term合并,而不是将exp作为因子put到term中,减少嵌套
- 向Expression类对象exp中put一个项term时,若term只包含一个表达式因子e,且term的系数为1(或-1)时,则将e(或-e)与exp合并,而非将term作为项put到exp中,减少嵌套
- 输出部分:延续作业二中的模式,对特殊情况进行处理
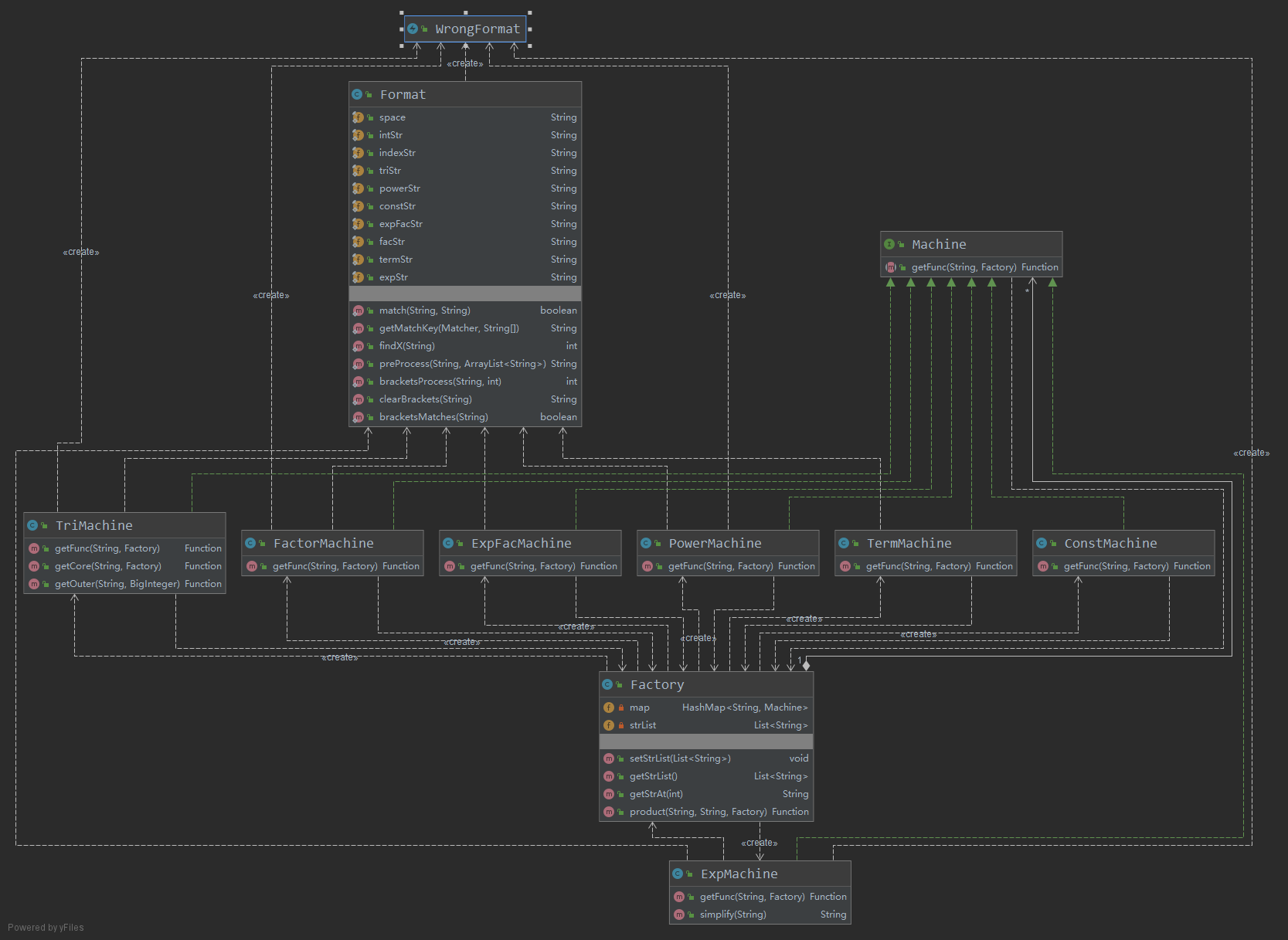
UML图:
- 数据管理部分

- 工厂部分
2. 代码质量分析
Metrics
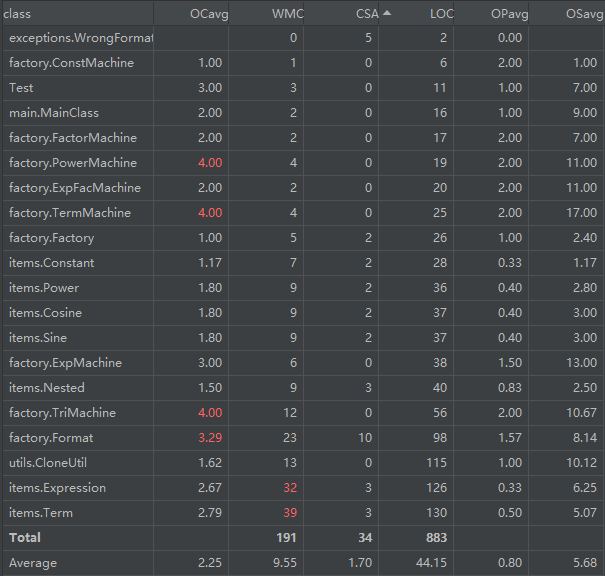
code lines:共1007行

DesigniteJava工具分析:

通过以上结果看出,随着作业复杂度增大,类与方法的复杂度也随之增大。其中PowerMachine、TermMachine、TriMachine由于生成对象时需要大量循环和判断,平均复杂度较高。Format由于内置了大量静态变量和复杂的静态方法,平局复杂度和耦合性较高。而Expression和Term类由于处理核心数据,类总复杂度较高。除此之外,其他类的复杂度与耦合性均较好
整体而言,此次作业由于第二次作业留出的扩展性,几乎没有重构的部分,主要是进行扩展。同时由于类的规划较好,整体的复杂度与耦合性均较好。
二、测试与bug
1. 公测:
本单元作业均未在中测以及强测中被发现bug。其中第一次与第三次由于优化较好,性能分获得满分;第二次作业由于优化不够彻底(测评方式有问题),获得97.7583分。
2. 互测:
被hack:
第一次作业中采用TreeSet对项按照系数大小进行排序,由于对容器TreeSet和接口Comparable理解不深,导致系数相同的项只会输出一项,从而被hack出bug
第二次与第三次均未被hack出bug
hack:
第一次作业hack出的bug有:
系数为1或-1时省略系数却为省略乘号,导致输出WF
部分数据将幂指数符号输出位^,不符合指导书规范,输出WF
连续的正负号处理问题,将 - - x识别为-x
均为细节处理问题
第二次作业hack出的bug有:
- 将x*x**10000识别为WF,对指导书所说的指数绝对值超过10000理解不深
- 输入包含(sin(x)**2 + cos(x)**2)**n的展开时,会出现错误,为输出处理的问题
- 部分数据会抛出
java.util.ConcurrentModificationException异常,经检查代码发现是在HashMap的两重循环迭代的内层循环中,remove元素所致
第三次作业hack出的bug有:
- 处理多个相同表达式相乘时(如 (x+1) * (x+1) * (x+1)),会当成一次幂处理(即当成(x+1)处理)
- 将cos(0)化简为0
hack的主要思路有:
- 在自己写代码的过程中记录自己碰到的bug以及可能出现的bug的数据
- 黑盒测试,得到错误结果后逐步解析
- 阅读代码,精准hack
三、设计模式
主要采用了工厂模式
在第一次作业中,采用了简单工厂模式来解析输入字符串,由于比较简单,没有考虑向后兼容
在第二次作业中,由于解析字符串的复杂性,以及考虑到向后兼容,采用了抽象工厂模式:设计接口Machine,内置方法Function getFunc(String str) throws WrongFormat,再设计各种具体的Machine实现Machine接口,以通过正则捕获到的字符串生成对应的对象。设计一个Factory类,通过HashMap管理这些Machine的实例化对象,通过输入命令的方式获得需要生产的对象
在第三次作业中,延续了第二次作业的工厂模式,对于嵌套因子和多项式因子进行了相应的扩展
工厂模式使得创建过程透明于用户,业务逻辑代码不需要过多地关注对象是如何由输入产生的,降低了程序的耦合性和业务逻辑代码的复杂度
同时工厂模式有利于扩展,当出现新的产品对象时,设计相应的生产类并实现接口即可
四、心得体会
需要更多地从设计的层面思考问题
需要分层次地、结构化地、面向对象地进行程序架构的设计,以留出更好的扩展性
需要善用讨论区,多于同学交流。三次作业我均在于同学交流中收获巨大,包括:
- 黑盒测试机的搭建思路
- 第二次作业中三角函数深搜优化的思路,以及x**2 化简成 x*x的技巧
- 各种概念的理解
- 一些比较难以发现的bug的启发
总而言之,这三次作业使我对于java的继承、接口、多态、容器等有了更进一步的理解;在设计上,如何使得代码耦合程度和复杂度较好,如何留出更多的扩展性,也有了进一步的思考