一、关于文件读写的笔记
文件的使用分为3步:打开文件、读写文件、关闭文件。
(2)文件的打开与关闭
Python对文本文件和二进制文件采用统一的操作步骤,即“打开-操作-关闭”
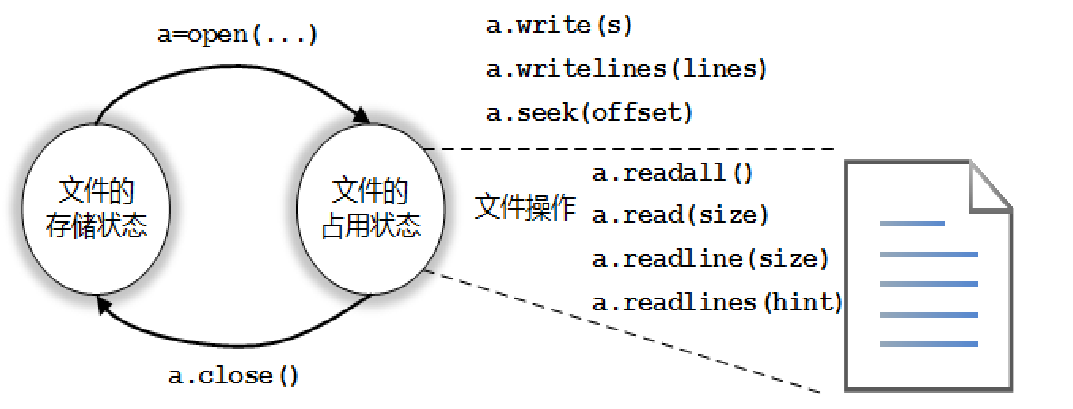
Python通过解释器内置的open()函数打开一个文件,并实现该文件与一个程序变量的关联,open()函数格式如下:
<变量名> = open(<文件名>, <打开模式>)
>>> f = open('test.txt', 'r')
r表示是文本文件,rb是二进制文件。(这个mode参数默认值就是r)
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
open()函数有两个参数:文件名和打开模式。文件名可以是文件的实际名字,也可以是包含完整路径的名字
open()函数提供7种基本的打开模式:

根据打开方式不同可以对文件进行相应的读写操作,Python提供4个常用的文件内容读取方法

- read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。如果文件大于可用内存,为了保险起见,可以反复调用
read(size)方法,每次最多读取size个字节的内容。 - readlines() 之间的差异是后者一次读取整个文件,象 .read() 一样。.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。
- readline() 每次只读取一行,通常比readlines() 慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用 readline()。
(三) 使用实例

>>> f = open("D:\\joke.txt", 'r') # 打开文件,只读模式
>>> for line in f.readlines(): # 输出文件内容
print(line)
交警站在红绿灯路口把一辆小汽车拦住。
交警说:“你还不停车,车轮压线了。”
司机说:“这是我的压轴好戏。”
交警说:“我看你没有拿出刹手锏。”
司机说:“我把握得好,没有把线压坏吧?”
交警说:“这是一根高压线,不容你触及。”
司机说:“没关系,我的车轮是绝缘体。”
>>> f.close() # 关闭文件
>>> fp = open("D:\\joke.txt", 'w+') # 打开文件,读写模式
>>> text = "我买了王羲之的亲笔写的大字:同一个世界同一个梦想。"
>>> fp.write(text) # 将字符串text写入文件
25
>>> fp.seek(0) # 将文件指针移至文件开头
0
>>> fp.read() # 读入文件所有内容
'我买了王羲之的亲笔写的大字:同一个世界同一个梦想。'
>>> f.close() # 关闭文件
(2)读取一个excel文件(以班上同学学习python的成绩作为一个例子)
步骤:在电脑上存有命名为Python成绩的excel 文件。
然后输入代码:
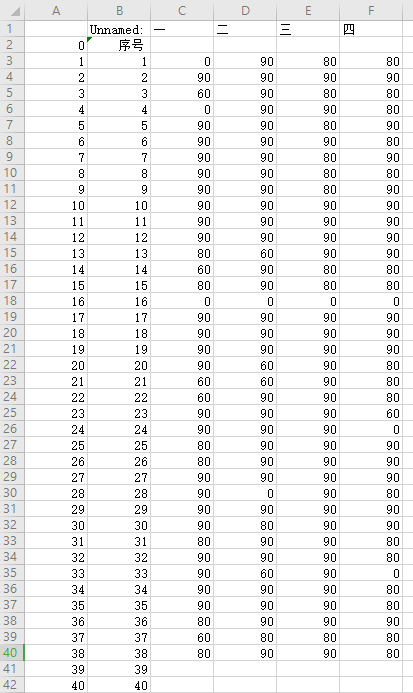
import pandas as pd df = pd.read_excel('file:Python成绩登记信计.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据 print(df) df1=df[:] df1['一']=df1['一'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['二']=df1['二'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['三']=df1['三'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['四']=df1['四'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1.to_csv('C:/Users\\86134\\.spyder-py3\\成绩表.csv')
运行结果:
将csv格式文件转化为html格式。
(Hyper Text Markup Language,超文本标记语言) 是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。
输入代码如下:
import pandas as pd df = pd.read_excel('file:Python成绩登记信计.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据 print(df) df1=df[:] df1['一']=df1['一'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['二']=df1['二'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['三']=df1['三'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1['四']=df1['四'].map({'优秀':90,'良好':80,'合格':60,'不合格':0}) df1.to_csv('C:/Users\\86134\\.spyder-py3\\成绩表1.html')
结果显示为:

3.运用python CGI把上面的csv格式文件,用网页显示并截屏出来。
CGI(Common Gateway Interface)也叫通用网关接口,它是一个web服务器主机提供信息服务的标准接口,只要遵循这个接口,web服务器就能获取客户端提交的信息,转交给服务端的CGI程序进行处理,然后将处理结果返回给客户端。CGI通讯是由两部分组成的:一部分是用户的浏览器显示的页面,也就是html页面,另一部分则是运行在服务器上的CGI程序。
输入代码为: