Hello,everyone!
我是CS科研GO,一个热衷于科研和软开的胖子!
论文题目:Simultaneous Localization and Mapping: Part I
论文作者:Hugh Durrant-Whyte,Tim Bailey;工作单位:悉尼大学,澳大利亚;
发表期刊:IEEE ROBOTICS & AUTOMATION MAGAZINE(SCI二区)。
话不多说,先来张SLAM效果图

这篇早期很有名气的SLAM综述性论文,发表于2006年。主要内容如下:
一、SLAM的早期发展史
1.1 SLAM问题起源
SLAM问题起源于1986年举行的IEEE Robotics and Automation Conference (San Francisco, California)。会议结束后,参会的研究人员做了许多相关的理论工作。
1.2 理论发展受阻
1990年,Smith等人的研究表明,对于定位和地图构建问题的完整解决方案需要估算机器人(载具)姿态和每个地标位置组成的联合状态,并在每次观察地标之后进行更新。这将要求估算函数采用复杂的状态向量(按地图中维护的地标数量的顺序),计算规模为地标数量的平方。此外,这项工作没有考虑地图映射的收敛性或稳定性,这意味着问题的计算复杂度很高,而且地图估计的误差不会收敛。
1.3 理论突破
1997年,Univ. Oxford博士生M. Csorba给出了SLAM问题的收敛性理论和初始结果。
1.4 理论改进
在97年的理论工作基础上,研究人员关注改进计算能效性,解决数据关联和回环问题。1999年International Symposium on Robotics Research (ISRR)首次举办SLAM研讨会,S. Thrun等人将基于Kalman滤波器的SLAM方法与概率定位和映射方法进行了一定程度的融合。
1.5 研究热点
2002年,ICRA的SLAM研讨会吸引了150位兴趣广泛的研究人员;由H. Christiansen同年举办的SLAM暑期学校吸引了来自世界各地的重要研究人员和50名博士生,在此领域的建设上取得了巨大影响。
二、SLAM理论及演变过程
SLAM是一个过程,移动机器人可以通过该过程构建环境地图,并同时使用该地图推断其位置。在SLAM中,无需任何先验位置知识即可在线估算机器人的轨迹和所有地标的位置。

2.1 预备知识
图1描述一个基本的SLAM过程。在时刻 ,定义以下变量:
- : 描述机器人(载具)位置和方向的状态向量;
- : 控制向量,用于描述机器人从 时刻到 时刻的变化;
- : 描述第 个地标位置的向量,假定地标位置不随时间发生改变;
- : 在 时刻,机器人对第 个地标位置的观测值;若此时观测到多个地标,或无需关注的地标,则用 表示。
此外,定义以下集合:
- : 表示机器人的历史位置;
- : 表示控制输入的历史数据;
- : 表示所有地标的集合;
- : 表示所有地标观测的集合。
2.2 SLAM问题的概率分布
表达式描述了,当给定 时刻的地标观测值,控制输入值和机器人初始状态时,此时地标位置和机器人状态的联合后验概率密度。通常,SLAM问题可以递归求解。从 时刻的分布 的估计值开始,根据 和 ,使用贝叶斯定理计算 。该计算要求定义状态转换(运动)模型和观测模型,分别描述控制输入和观测的影响。
-
运动模型: ,状态转换被假定为一个马尔科夫过程,在这个过程中,下一个状态 只依赖于紧邻前一个状态 ,和应用的控制 ,并且独立于观测值和地图。
-
观测模型: ,描述机器人位置和地标位置已知时,观测 的概率。
SLAM算法可分为以下两步:

上述公式提供了一个递归过程,用于计算联合后验分布
。此递归是运动模型
和观测模型
的函数。
2.3 SLAM概率分布讨论
为方便讨论,将 简写为 。由于观测模型 表明地标观测值和机器人和地标之间存在依赖关系,因此 。
回顾图1,地标的估计值和真实值之间存在误差,然而,这些误差是高度相关的。更重要的是,随着越来越多的观测,地标间估计值的相关性单调递增。实际上,这意味着无论机器人如何运动,对地标的相对位置的认知总是在提高(收敛),而不是发散。
三、SLAM解决方案
3.1 EKF-SLAM
- 运动模型: ,其中, 指非线性的系统状态转换函数, 指运动过程中的预测误差,服从 的高斯白噪声。
- 观测模型: ,其中, 是非线性测量模型, 代表观测误差,服从 的高斯白噪声。
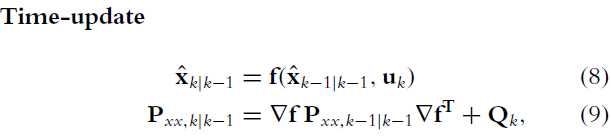
其中,
是
的雅可比矩阵。

其中,
是
的雅可比矩阵。
EKF-SLAM的缺点
- 算法的时间复杂度为 , 代表锚点的数量。
- EKF假定机器人的运动和观察存在高斯噪声。在这种情况下,传感器中的不确定性必须相对较小,因为EKF中的线性过程可能会引入无法忍受的噪声。
- EKF代表高斯后验模型,它是一种单峰分布,仅对处理后验围绕真实状态且不确定性很小的问题时才有效。
3.2 FastSLAM
FastSLAM以递归蒙特卡罗采样或粒子滤波为基础,首次直接表示了非线性过程模型和非高斯姿态分布。FastSLAM的基本结构是一个R-B状态(求最优解过程),轨迹由加权样本表示,并通过解析计算得到地图。算法基本思想是通过粒子滤波对运动状态进行递归估计,通过EKF对地图映射状态进行递归估计。
对于SLAM, R-B粒子滤波的一般形式如下。
假设在 时刻,联合状态(机器人位置姿态,观测地标位置姿态)可以用 表示,则有:
-
对于每个粒子,以特定的粒子历史为条件,计算提出的分布,并从中提取样本
-
根据重要的函数对样本进行加权,下面方程的分子项分别为观测模型和运动模型
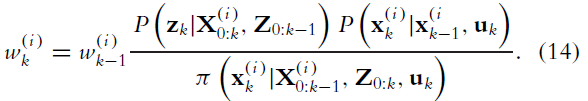
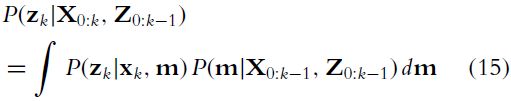
-
如果有必要,执行重采样。(什么时候重采样是一个未解决的问题。有些方案会对每个时刻重采样,有些则在固定时间间隔后取样,还有一些则在权重方差超过阈值时取样)重采样是通过从集合 中选择粒子,并替换它们,包括它们的相关映射来完成的,选择的概率与 成正比。选定的粒子给予均匀的权值, 。
-
对于每个粒子,用已知姿态的简单映射操作对观测到的地标进行EKF更新。
与EKF-SLAM相比,FastSLAM具有许多优势。
- FastSLAM可以在时间上以锚的数量为对数实现,与普通的EKF-SLAM相比具有计算优势。
- FastSLAM提供了显著的数据关联鲁棒性,因为它可以保持多个数据关联的后验,而不仅仅是基于EKF-SLAM中包含的增量最大似然数据关联,在任何时间点仅跟踪单个数据关联。
- FastSLAM还可以处理非线性模型,因为粒子滤波器可以处理非线性机器人运动模型,并且可以保证在某些假设下收敛。
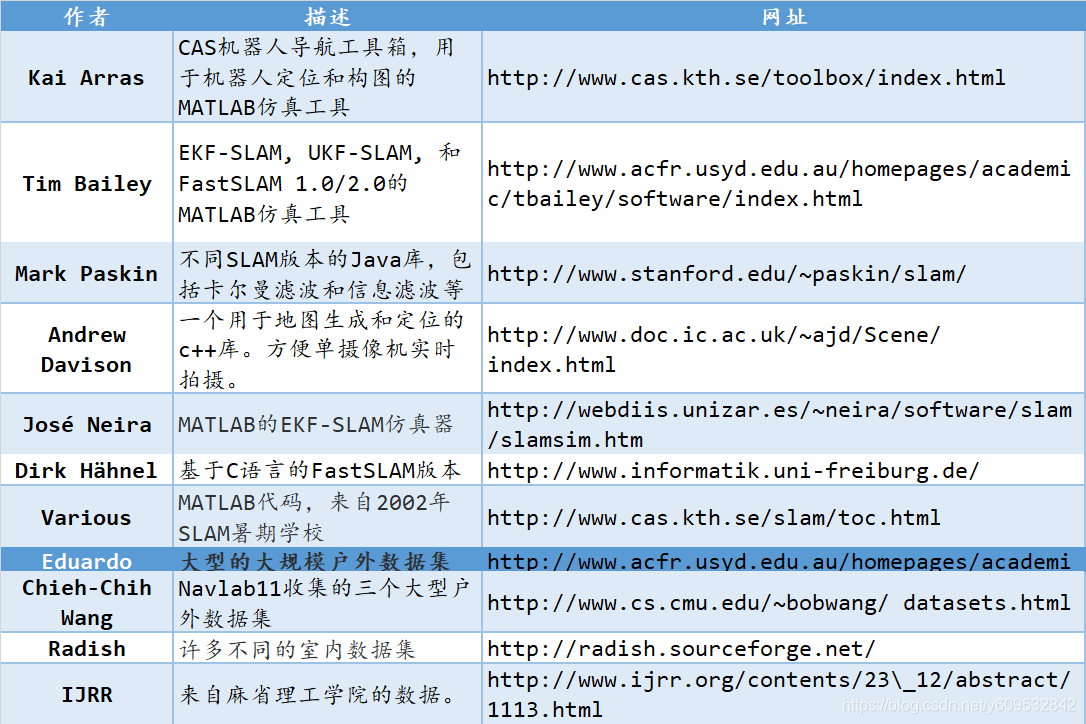
四、SLAM实现
截至2006年,SLAM领域的研究人员编写了演示SLAM的软件,分别在MATLAB、C++和Java中实现;此外,他们还提供了一些来自真实环境中传感器数据集,这是评估各种SLAM算法的宝贵资源。具体内容见下表。
内容靠得住,关注不迷路。
