清晰记得本次实验在推了两次项目集规范簇之后,发现文档中给出的文法有错误,联系老师得到改正后,遂顺利完成。简单记录一下本次实验的经历,留作以后备用,若有错误之处,还请路过的博友不吝赐教。
实验设计目标
构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子。
实验原理
整体思路:在总控程序的控制下,从左到右扫描输入符号串,根据状态栈中的栈顶状态、符号栈中的栈顶字符和文法及当前输入符号,按分析表完成相应的分析工作。
LR分析器由三个部分组成:
- 总控程序,也可以称为驱动程序。对所有的LR分析器总控程序都是相同的。
- 分析表或分析函数,不同的文法分析表将不同,同一个文法采用的LR分析器不同时,分析表将不同,分析表又可以分为动作表(ACTION)和状态转换(GOTO)表两个部分,它们都可用二维数组表示。
- 分析栈,包括文法符号栈和相应的状态栈,它们均是先进后出栈。
-
分析器的动作就是由栈顶状态和当前输入符号所决定。
GOTO[i,X]=j表示,规定当栈顶状态为i,遇到当前文法符号为X时应转向状态j,X为非终结符。
ACTION[i,a]规定了栈顶状态为i时,遇到输入符号a应执行的动作有四种可能:
-
-
-
移进:
action[i,a]= Sj:状态 j 移入到状态栈,把 a 移入到文法符号栈,其中 i , j 表示状态号。
- 归约:
action[i,a]=Rk:当在栈顶形成句柄时,则归约为相应的非终结符A,即文法中有A->B的产生式,若B的长度为R(即|B|=R),则从状态栈和文法符号栈中自顶向下去掉R个符号,即栈指针SP减去R,并把A移入文法符号栈内,j=GOTO[i,A]移进状态栈,其中i为修改指针后的栈顶状态。
- 接收Acc:
当归约到文法符号栈中只剩文法的开始符号S时,并且输入符号串已结束即当前输入符是'#',则为分析成功。
- 报错:
当遇到状态栈顶为某一状态下出现不该遇到的文法符号时,则报错,说明输入端不是该文法能接受的符号串。
-
实验文法
(0)S->E
(1)E->E+T
(2)E->E-T
(3)E->T
(4)T->F
(5)T->T*F
(6)T->T/F
(7)F->(E)
(8)F->i
实验输入、输出
- 输入数据:
case1: i+i*i#
case2: i+i*#
- 输出结果:
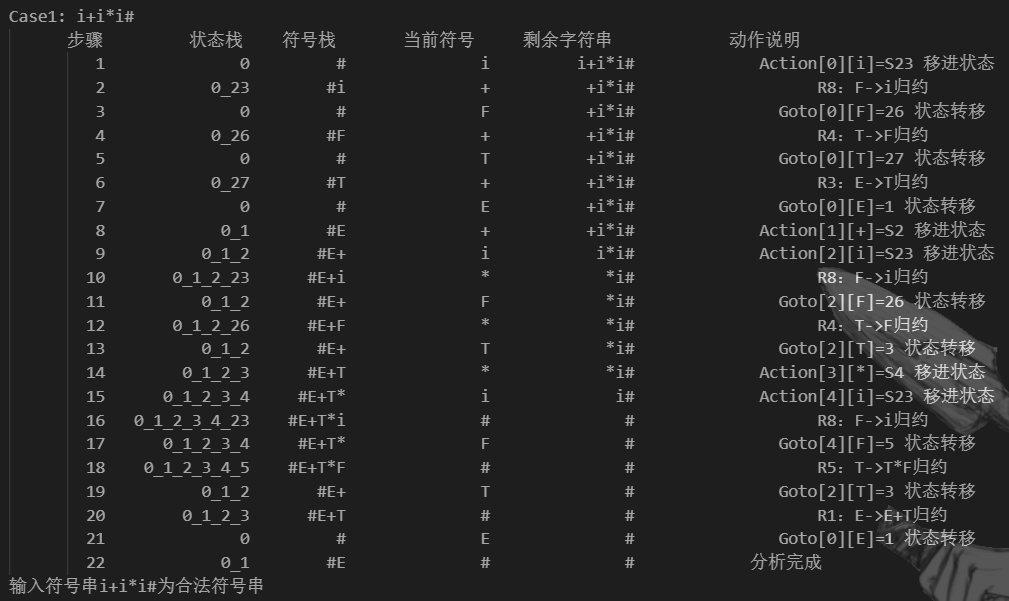

实验实现过程
- 首先就是秃头三次的项目集规范簇(一开始打算手写来着,画满一张A4纸之后, Visio好香啊……)
这里我是采用类似DFS深度遍历的思想来画的,对于一个输入就按着他一个输入分支往下画,直到不能再往下扩展。便回溯将前边的分支填充,所以画出来的最后的图片就出现了这样一个特点,靠前的很多分支都是直接写编号就可以了。当然也可以采用像BFS遍历的思想来画,个人感觉效果应该是一样的。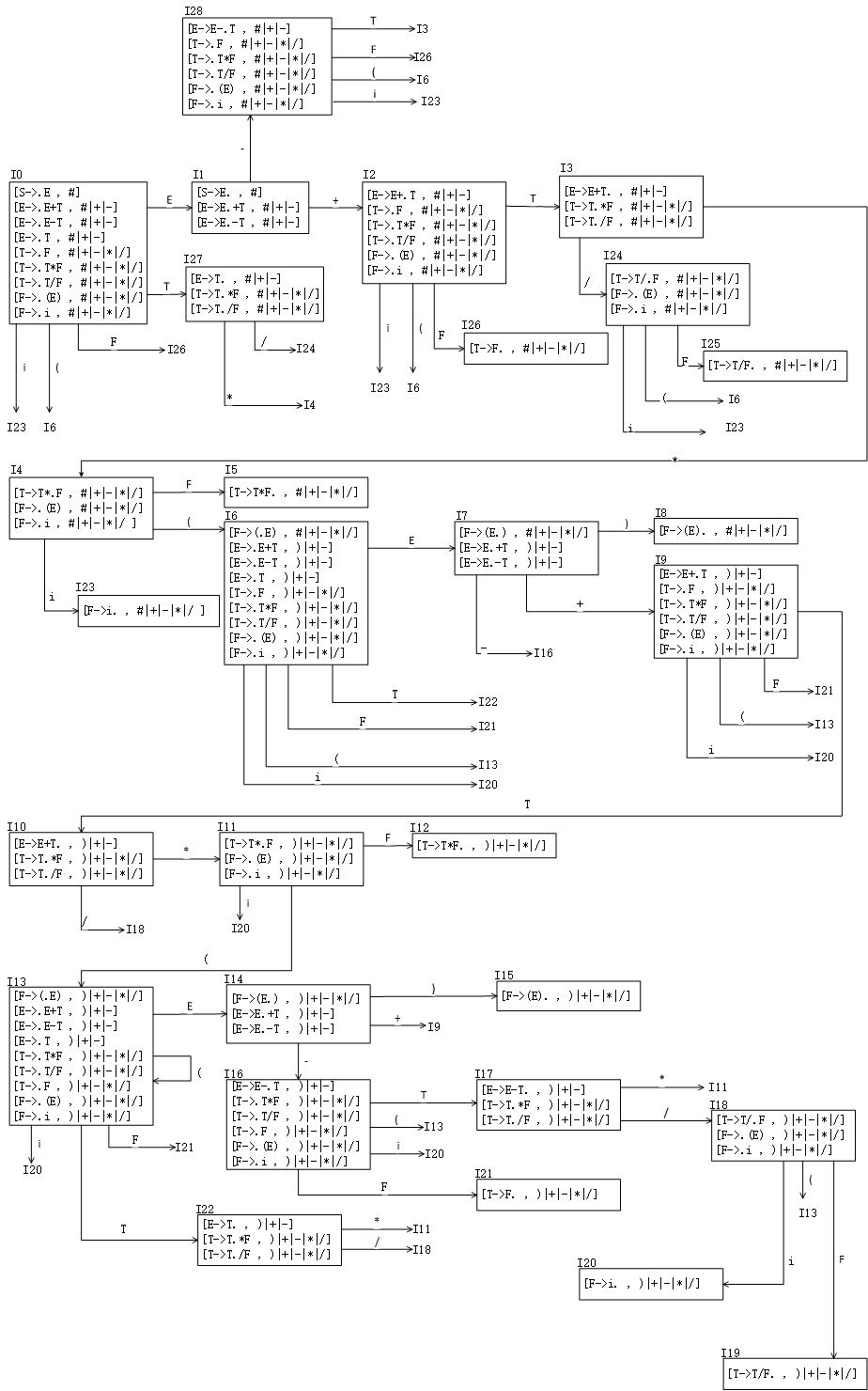
2. 那有了项目集规范簇,接下来就要构建相应的Action表和Goto表了,这里照着项目集规范簇来并不难,麻烦的是将其转换为代码中对应的表(建表时,眼都看花了……)
-
- Action表
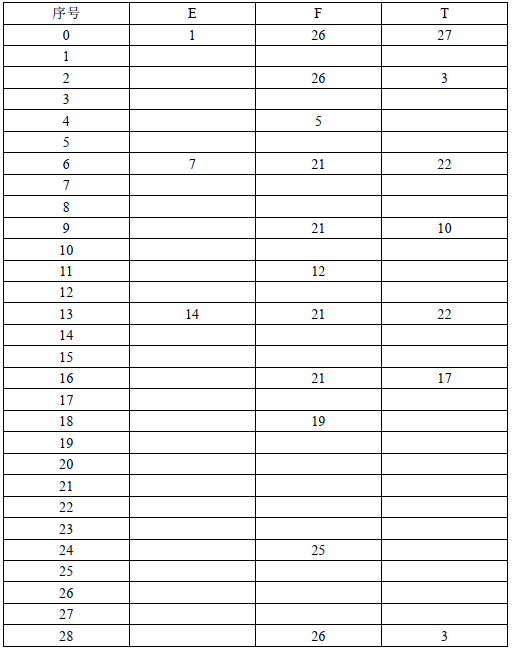
-
- Goto表:
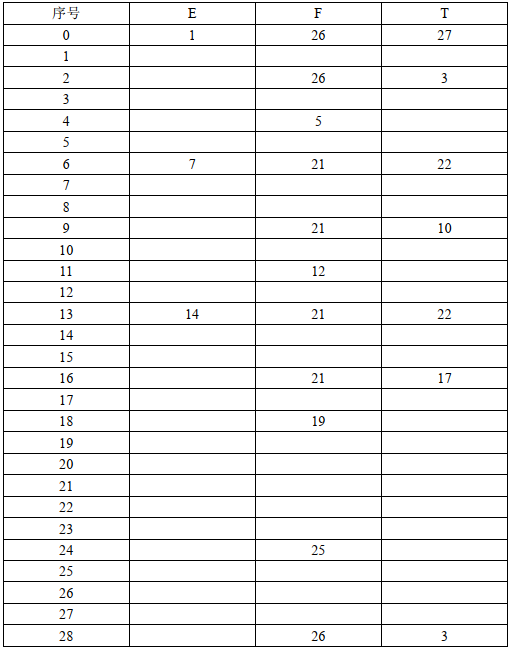
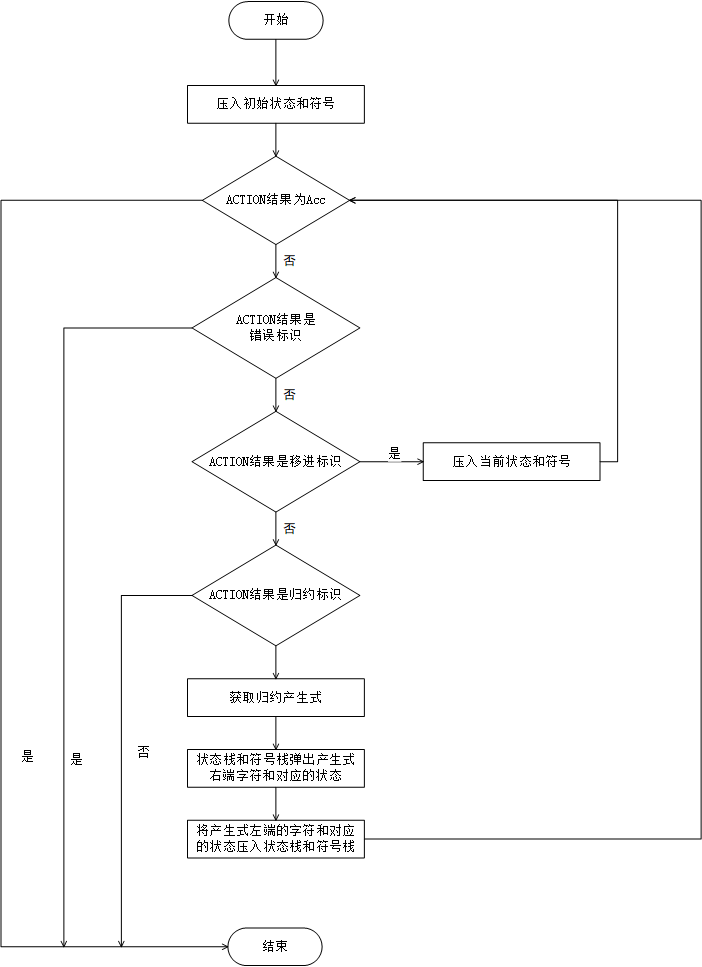
3. 有了Action表和Goto表,剩下的就好办了,为了能更好的理清思路,我又画了LR(1)控制器的流程图。
代码实现部分
(待实验统计完毕之后,在统一上传一下XD)