Hadoop实现词频统计(按照词频降序排列以及相同词频的单词按照字母序排列)
一.环境
ubuntu虚拟机,使用的是伪分布式的hadoop集群(对于做实验使用伪分布式的更方便),代码通过eclipse来提交
二.实现步骤
一共使用了两个MapReduce,第一个MapReduce实现词频统计,第二个MapReduce实现排序
1.数据
实验数据:链接:https://pan.baidu.com/s/14_2yoGVpN4Web89M6pXGlQ
提取码:jo80
停词表:链接:https://pan.baidu.com/s/14vt7AJRLqx0VOF4hCr22NA
提取码:2k1q
2.主函数
其中将停词表的路径作为全局参数传入第一个MapReduce的配置文件中。还设置了词频的阈值,通过args传入main函数,自己运行程序的时候设置。
两个MapReduce顺序执行,第一个的输出作为第二个的输入,因为第二个MapReduce依赖第一个所以要设置依赖
public static void main(String[] args ) throws Exception
{
Configuration conf1 = new Configuration(true);
// 停词表所在的路径
conf1.setStrings("stopwords", "hdfs://localhost:9000/stopword/stopwords.txt");
// 设置词频阈值,小于该阈值的不输出
conf1.set("num", args[0]);
// 输入文件输出文件的路径
String[] ars=new String[]{"hdfs://localhost:9000/stopword/data","hdfs://localhost:9000/stopword/output/output1","hdfs://localhost:9000/stopword/output/output2"};
String[] otherArgs=new GenericOptionsParser(conf1,ars).getRemainingArgs();
// job1,词频统计
Job job1= Job.getInstance(conf1,"world count");
job1.setJarByClass(WordSort.class);
job1.setMapperClass(Map.class);
job1.setReducerClass(Reduce.class);
job1.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job1,new Path(otherArgs[0]));
// job.setOutputFormatClass(TextOutputFormat.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job1,new Path(otherArgs[1]));
// 将job1加入控制器
ControlledJob ctrlJob1 = new ControlledJob(conf1);
ctrlJob1.setJob(job1);
// job2,将词频按照降序排列,并且相同词频的单词按照字母序排列
Configuration conf2 = new Configuration(true);
Job job2= Job.getInstance(conf2,"sort");
job2.setJarByClass(WordSort.class);
job2.setMapperClass(Map2.class);
job2.setReducerClass(Reduce2.class);
job2.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job2,new Path(otherArgs[1]));
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
// 设置对map输出排序的自定义类
job2.setSortComparatorClass(Sort.class);
FileOutputFormat.setOutputPath(job2,new Path(otherArgs[2]));
// 将job2加入控制器
ControlledJob ctrlJob2 = new ControlledJob(conf2);
ctrlJob2.setJob(job2);
//设置作业之间的依赖关系,job2的输入以来job1的输出
ctrlJob2.addDependingJob(ctrlJob1);
//设置主控制器,控制job1和job2两个作业
JobControl jobCtrl = new JobControl("myCtrl");
//添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrlJob1);
jobCtrl.addJob(ctrlJob2);
System.out.println("Job Start!");
//在线程中启动,记住一定要有这个
Thread thread = new Thread(jobCtrl);
thread.start();
while (true) {
if (jobCtrl.allFinished()) {
System.out.println(jobCtrl.getSuccessfulJobList());
jobCtrl.stop();
break;
}
}
}
3.第一个MapReduce
Map
首先在setup中读取停词表(好处是只需要读一次,如果在map中会重复读,浪费资源),然后在map中使用正则表达式出去标点符号,因为这个表达式会留下单词和数字,所以再对数字进行清除,留下来的单词作为reduce的输出
// 第一个map
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable>
{
private Set<String> stopwords;
private String localFiles;
@Override
public void setup(Context context) throws IOException,InterruptedException{
stopwords = new TreeSet<String>();
// 获取在main函数中设置的conf配置文件
Configuration conf = context.getConfiguration();
// 获取停词表所在的hdfs路径
localFiles = conf.getStrings("stopwords")[0];
FileSystem fs = FileSystem.get(URI.create(localFiles), conf);
FSDataInputStream hdfsInStream = fs.open(new Path(localFiles));
// 从hdfs中读取
InputStreamReader isr = new InputStreamReader(hdfsInStream, "utf-8");
String line;
BufferedReader br = new BufferedReader(isr);
while ((line = br.readLine()) != null) {
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
// 得到停词表
stopwords.add(itr.nextToken());
}
}
}
// 用来判断字符串是否为数字
Pattern pattern = Pattern.compile("^[-\\+]?[\\d]*$");
@Override
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String temp = new String();
final IntWritable one = new IntWritable(1);
// 使用正则表达式除去标点符号
StringTokenizer itr = new StringTokenizer(value.toString().toLowerCase().replaceAll("\\pP|\\pS", ""));
// String[] itr = value.toString().toLowerCase().split("[^a-zA-Z']+");
for(;itr.hasMoreTokens();){
temp = itr.nextToken();
// 如果是数字则不保存
if (pattern.matcher(temp).matches()){
continue;
}
// 判断单词是否在停词表中,如果不在则保存
if (!stopwords.contains(temp)) {
Text word = new Text();
word.set(temp);
context.write(word, one);
}
}
}
}
Reduce
首先需要在setup中读取设置的阈值,因为相同单词发送到一个reduce上,所以对其频数求和得到总频数,并将其与阈值做比较,大于的才进行输出
// 第一个reduce
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>
{
String num;
public void setup(Context context) throws IOException,InterruptedException{
Configuration conf = context.getConfiguration();
// 获取词频阈值
num = conf.get("num");
}
IntWritable result = new IntWritable();
@Override
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException
{
int sum = 0;
// 统计词频
for (IntWritable val : values) {
sum += val.get();
}
if (sum > Integer.parseInt(num)){
result.set(sum);
context.write(key,result);
}
}
}
4.第二个MapReduce
Map
首先读取第一个MapReduce的输出,得到单词和频数,因为想要对频数排序,再因为map传到reduce会经过sort这个过程,所以可以利用这个过程对频数进行排序,只需要将词频作为键,单词作为值从map函数中输出
// 第二个map
public static class Map2 extends Mapper<LongWritable,Text,IntWritable,Text>
{
private Set<String> stopwords;
private Path[] localFiles;
@Override
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
// 读取第一个mapreduce的结果,通过制表符将键和值分开
String[] data = value.toString().split("\t");
// 将词频作为键,单词作为值
context.write(new IntWritable(Integer.parseInt(data[1])), new Text(data[0]));
}
}
Reduce
在map中已经实现了频数的排序,现在需要实现相同词频的单词按照字母序排列,因为相同词频的单词被发送到一个reduce上,所以对reduce输入的值按字母序排列,然后按照排列好的顺序依次写入(单词作为键,词频作为值),即可实现相同词频下按照字母序排列
// 第二个reduce
public static class Reduce2 extends Reducer<IntWritable,Text,Text,IntWritable>
{
IntWritable result = new IntWritable();
@Override
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException,InterruptedException
{
// 相同词频的单词发送到一个reduce上,则只需要将相同词频的单词在第二个reduce中按字母序排列即可
List<String> sort = new ArrayList<String>();
// Iterator<Text> it = values.iterator();
for(Text value : values){
sort.add(value.toString());
}
String[] strings = new String[sort.size()];
sort.toArray(strings);
// 对单词按照字母序排序
Arrays.sort(strings);
for (int i = 0;i<strings.length;i++){
// 相当于是相同词频的键是按照字母序排的
context.write(new Text(strings[i]), key);
}
}
}
Sort
由于默认的sort是升序排列的所以需要自定义一个sort来实现降序排列
// 对第二个mapreduce中map的key进行排序,实现降序排列
public static class Sort extends IntWritable.Comparator{
public int compare(WritableComparable a, WritableComparable b){
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
三.代码总览
package test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.TreeSet;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
//import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.jobcontrol.JobControl;
public class WordSort {
// 第一个map
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable>
{
private Set<String> stopwords;
private String localFiles;
@Override
public void setup(Context context) throws IOException,InterruptedException{
stopwords = new TreeSet<String>();
// 获取在main函数中设置的conf配置文件
Configuration conf = context.getConfiguration();
// 获取停词表所在的hdfs路径
localFiles = conf.getStrings("stopwords")[0];
FileSystem fs = FileSystem.get(URI.create(localFiles), conf);
FSDataInputStream hdfsInStream = fs.open(new Path(localFiles));
// 从hdfs中读取
InputStreamReader isr = new InputStreamReader(hdfsInStream, "utf-8");
String line;
BufferedReader br = new BufferedReader(isr);
while ((line = br.readLine()) != null) {
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
// 得到停词表
stopwords.add(itr.nextToken());
}
}
}
// 用来判断字符串是否为数字
Pattern pattern = Pattern.compile("^[-\\+]?[\\d]*$");
@Override
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String temp = new String();
final IntWritable one = new IntWritable(1);
// 使用正则表达式除去标点符号
StringTokenizer itr = new StringTokenizer(value.toString().toLowerCase().replaceAll("\\pP|\\pS", ""));
// String[] itr = value.toString().toLowerCase().split("[^a-zA-Z']+");
for(;itr.hasMoreTokens();){
temp = itr.nextToken();
// 如果是数字则不保存
if (pattern.matcher(temp).matches()){
continue;
}
// 判断单词是否在停词表中,如果不在则保存
if (!stopwords.contains(temp)) {
Text word = new Text();
word.set(temp);
context.write(word, one);
}
}
}
}
// 第一个reduce
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>
{
String num;
public void setup(Context context) throws IOException,InterruptedException{
Configuration conf = context.getConfiguration();
// 获取词频阈值
num = conf.get("num");
}
IntWritable result = new IntWritable();
@Override
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException
{
int sum = 0;
// 统计词频
for (IntWritable val : values) {
sum += val.get();
}
if (sum > Integer.parseInt(num)){
result.set(sum);
context.write(key,result);
}
}
}
// 第二个map
public static class Map2 extends Mapper<LongWritable,Text,IntWritable,Text>
{
private Set<String> stopwords;
private Path[] localFiles;
@Override
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
// 读取第一个mapreduce的结果,通过制表符将键和值分开
String[] data = value.toString().split("\t");
// 将词频作为键,单词作为值
context.write(new IntWritable(Integer.parseInt(data[1])), new Text(data[0]));
}
}
// 第二个reduce
public static class Reduce2 extends Reducer<IntWritable,Text,Text,IntWritable>
{
IntWritable result = new IntWritable();
@Override
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException,InterruptedException
{
// 相同词频的单词发送到一个reduce上,则只需要将相同词频的单词在第二个reduce中按字母序排列即可
List<String> sort = new ArrayList<String>();
// Iterator<Text> it = values.iterator();
for(Text value : values){
sort.add(value.toString());
}
String[] strings = new String[sort.size()];
sort.toArray(strings);
// 对单词按照字母序排序
Arrays.sort(strings);
for (int i = 0;i<strings.length;i++){
// 相当于是相同词频的键是按照字母序排的
context.write(new Text(strings[i]), key);
}
}
}
// 对第二个mapreduce中map的key进行排序,实现降序排列
public static class Sort extends IntWritable.Comparator{
public int compare(WritableComparable a, WritableComparable b){
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
public static void main(String[] args ) throws Exception
{
Configuration conf1 = new Configuration(true);
// 停词表所在的路径
conf1.setStrings("stopwords", "hdfs://localhost:9000/stopword/stopwords.txt");
// 设置词频阈值,小于该阈值的不输出
conf1.set("num", args[0]);
// 输入文件输出文件的路径
String[] ars=new String[]{"hdfs://localhost:9000/stopword/data","hdfs://localhost:9000/stopword/output/output1","hdfs://localhost:9000/stopword/output/output2"};
String[] otherArgs=new GenericOptionsParser(conf1,ars).getRemainingArgs();
// job1,词频统计
Job job1= Job.getInstance(conf1,"world count");
job1.setJarByClass(WordSort.class);
job1.setMapperClass(Map.class);
job1.setReducerClass(Reduce.class);
job1.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job1,new Path(otherArgs[0]));
// job.setOutputFormatClass(TextOutputFormat.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job1,new Path(otherArgs[1]));
// 将job1加入控制器
ControlledJob ctrlJob1 = new ControlledJob(conf1);
ctrlJob1.setJob(job1);
// job2,将词频按照降序排列,并且相同词频的单词按照字母序排列
Configuration conf2 = new Configuration(true);
Job job2= Job.getInstance(conf2,"sort");
job2.setJarByClass(WordSort.class);
job2.setMapperClass(Map2.class);
job2.setReducerClass(Reduce2.class);
job2.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job2,new Path(otherArgs[1]));
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
// 设置对map输出排序的自定义类
job2.setSortComparatorClass(Sort.class);
FileOutputFormat.setOutputPath(job2,new Path(otherArgs[2]));
// 将job2加入控制器
ControlledJob ctrlJob2 = new ControlledJob(conf2);
ctrlJob2.setJob(job2);
//设置作业之间的依赖关系,job2的输入以来job1的输出
ctrlJob2.addDependingJob(ctrlJob1);
//设置主控制器,控制job1和job2两个作业
JobControl jobCtrl = new JobControl("myCtrl");
//添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrlJob1);
jobCtrl.addJob(ctrlJob2);
System.out.println("Job Start!");
//在线程中启动,记住一定要有这个
Thread thread = new Thread(jobCtrl);
thread.start();
while (true) {
if (jobCtrl.allFinished()) {
System.out.println(jobCtrl.getSuccessfulJobList());
jobCtrl.stop();
break;
}
}
}
}
四.运行结果
输入参数为4,表示词频大于4的才保存
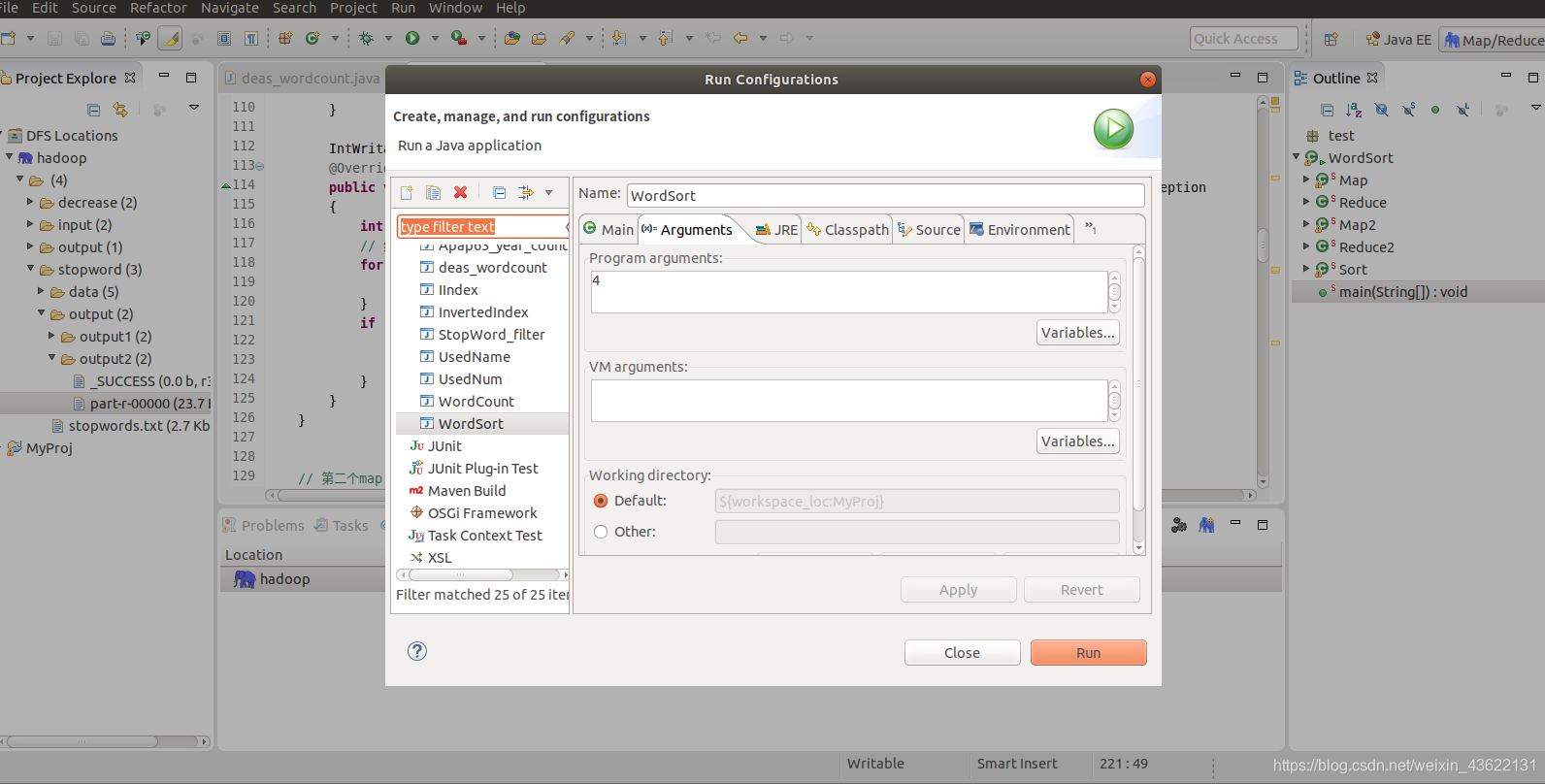
第一个MapReduce输出的结果,只是统计出了词频,没有排序

第二个MapReduce输出的结果,首先是按照词频降序排列的,相同词频的单词是按照字母序排列的


五.问题与解决
1.停用词表共享问题
怎样在所有节点上共享一张停用词表?本文是通过将停用词表传入hdfs,然后再在map的setup中读取来全局共享,初次之外还可以使用分布式缓存的方式来共享
2.实现词频降序问题
需要用户自定义数据类型来实现,自定义了排序的类并通过job2.setSortComparatorClass(Sort.class);传入MapReduce中
3.保证字母序问题
对于怎样使相同词频的单词保证字母序排列通过在第二个reduce中直接对相同词频的单词按照字母序排列,然后依次写入文件中来保证字母序
六.总结与感悟
1.不要局限于一个MapReduce
遇到问题应该想想是否能够用一个MapReduce解决,一定要先分析可行性,就像本文的问题无法仅仅使用一个MapReduce解决,那么就要开阔自己的思维,尝试用两个甚至多个MapReduce来解决问题
2.学会自定义数据类型
对于词频的降序排列,因为MapReduce的sort过程默认就是升序排列,想要实现降序就必须自己来定义数据类型解决问题,在遇到想要更改MapReduce默认机制的问题时应该想到自定义数据类型