此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
本次作业代码地址:https://git.coding.net/Ljr6899/wf.Java.git
设计:
1.曾用比较熟悉的C语言编写,但是编译了很久总是有算法错误。不得已选择了不太熟悉的面向对象Java。
2.整个词频统计分为三个部分,第一部分是读取文件并把所有单词截出来,第二部分是统计词频(利用树),第三部分是排序及输出。
代码实现:
本次代码的前三个功能设计了三种模式,输入1则执行功能一,输入2则执行功能二,输入3则执行功能三。
1 public static void main(String[] args) { 2 //主程序逻辑入口 3 while (true) { 4 System.out.println("本程序有三种模式:1.单行语言处理;2.单个文件处理;3.批量处理;0.退出程序\n请键入1 2 3选择您需要的模式,模式2指定具体路径为d盘根目录"); 5 Scanner readerScanner = new Scanner(System.in); 6 int flag = readerScanner.nextInt(); 7 if (flag == 0) { 8 break;
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
解析:读取一行英文句子,并截成单个单词。
1 else if (flag == 1) { 2 try { 3 System.out.println("当前为当行语言处理模式,请输入您要评测的语句"); 4 BufferedReader bf =new BufferedReader(new InputStreamReader(System.in)); //读取命令行中一行 5 String s=bf.readLine(); 6 LineCode(s); 7 } catch (IOException ex) { 8 System.out.println("请按单行输入句子"); 9 }
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
解析:因为题目要求只输入文件名称,没有具体文件路径,所以用户只需要输入文件名称即可。
1 else if (flag == 2) { 2 System.out.println("当前为单个文件处理模式,请输入您要输入的文件名,格式:aaa.txt"); 3 String s = readerScanner.next(); 4 try { 5 TxtCode(s); 6 } catch (Exception ex) { 7 System.out.println("请输入正确的文件名称,确定后文件存在以及文件是否放在d:根目录下"); 8 }
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
解析:要做批量文件处理,让用户输入文件路径,不要输入具体文件名称。遍历文件夹下所有文件(求只有文件),把需要处理的都放在文件夹下,就会遍历每一个文件,把每一个文件的单词都进行词频统计,它每执行一个文件都会输入文件具体路径和文件名称。
1 else if(flag==3){ 2 System.out.println("当前为批量文件处理模式,请输入文件具体路径,格式:d:/ljr"); 3 String path=readerScanner.next(); 4 File file =new File(path); 5 if (file.isDirectory()) { 6 File[] filelist =file.listFiles(); 7 for(File file1:filelist){ 8 try { 9 String s=file1.getPath();//地址回溯 10 System.out.println(s); 11 FileCode(s); 12 } catch (Exception ex) { 13 System.out.println("请输入正确的路径,若程序无法结束请重新运行程序"); 14 } 15 } 16 } 17 }
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
解析:功能四只是尝试了一下,不知道是否符合要求。
1 File file =new File(path); 2 if (file.isDirectory()) { 3 File[] filelist =file.listFiles(); 4 for(File file1:filelist){ 5 try { 6 String s=file1.getPath();//地址回溯
访问文件,把数据读到缓存区,用“String.split()+正则表达式”把所有单词截出来,再添加到链表里。统计词频,这里新建了一棵树作为对象,用来遍历lists。将单词作为树的key值,词频作为树的value值,实际上达到了统计词频的目的。排序及输出,首先是以oldmap.entrySet()方法将树里的映射关系存放到Set容器中,然后创建一个树的节点类型的链表,再调用一个系统库里的排序方法collection.sort对链表进行排序,最后遍历链表,从大到小输出。
1 //统计单个文件 2 public static void TxtCode(String txtname) throws Exception { 3 BufferedReader br = new BufferedReader(new FileReader("C:/word/" + txtname)); 4 List<String> lists = new ArrayList<String>(); //存储过滤后单词的列表 5 String readLine = null; 6 while ((readLine = br.readLine()) != null) { 7 String[] wordsArr1 = readLine.split("[^a-zA-Z]"); //过滤出只含有字母的 8 for (String word : wordsArr1) { 9 if (word.length() != 0) { //去除长度为0的行 10 lists.add(word); 11 } 12 } 13 } 14 br.close(); 15 StatisticalCode(lists); 16 } 17 18 //统计单行 19 public static void LineCode(String args) { 20 List<String> lists = new ArrayList<String>(); //存储过滤后单词的列表 21 String[] wordsArr1 = args.split("[^a-zA-Z]"); //过滤出只含有字母的 22 for (String word : wordsArr1) { 23 if (word.length() != 0) { //去除长度为0的行 24 lists.add(word); 25 } 26 } 27 StatisticalCode(lists); 28 } 29 30 public static void FileCode(String args) throws FileNotFoundException, IOException { 31 BufferedReader br = new BufferedReader(new FileReader(args)); 32 List<String> lists = new ArrayList<String>(); //存储过滤后单词的列表 33 String readLine = null; 34 while ((readLine = br.readLine()) != null) { 35 String[] wordsArr1 = readLine.split("[^a-zA-Z]"); //过滤出只含有字母的 36 for (String word : wordsArr1) { 37 if (word.length() != 0) { //去除长度为0的行 38 lists.add(word); 39 } 40 } 41 } 42 br.close(); 43 StatisticalCode(lists); 44 } 45 46 public static void StatisticalCode(List<String> lists) { 47 //统计排序 48 Map<String, Integer> wordsCount = new TreeMap<String, Integer>(); //存储单词计数信息,key值为单词,value为单词数 49 //单词的词频统计 50 for (String li : lists) { 51 if (wordsCount.get(li) != null) { 52 wordsCount.put(li, wordsCount.get(li) + 1); 53 } else { 54 wordsCount.put(li, 1); 55 } 56 } 57 // System.out.println("wordcount.Wordcount.main()"); 58 SortMap(wordsCount); //按值进行排序 59 } 60 //按value的大小进行排序 61 public static void SortMap(Map<String, Integer> oldmap) { 62 63 ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(oldmap.entrySet()); 64 Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { 65 @Override 66 public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { 67 return o2.getValue() - o1.getValue(); //降序 68 } 69 }); 70 for (int i = 0; i < list.size(); i++) { 71 System.out.println(list.get(i).getKey() + ": " + list.get(i).getValue()); 72 } 73 } 74 }
验证实例为泰戈尔诗作《生如夏花》

功能执行截图:
功能一:

功能二:

功能三:

功能四:

PSP报告:
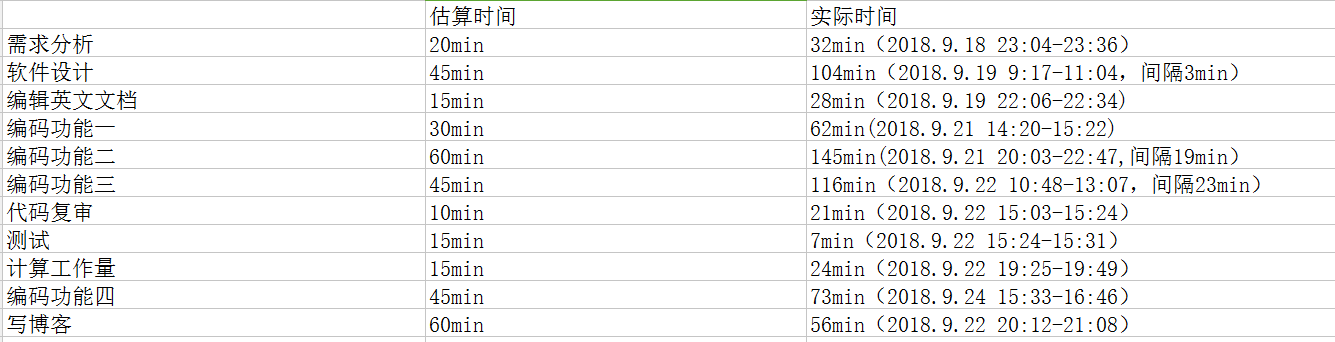
PSP每项时间花费分析原因:
需求分析:实不相瞒,作业要求中的很多内容初次看见真的看不懂,所以比预想多花费了一些时间百度了一下。
软件设计:此处的软件设计应为C语言的算法设计,想用链表来做,但是对我来讲实现挺难的。但由于最终放弃C语言,时间都白费了。
编辑英文文档:这项上就是百度一个英文文档啊,选取了其中三遍《曼德拉演讲稿》《纪伯伦:论友谊》《生如夏花》
编码功能一:虽然之前过了一遍书,但是很多细节都记不清楚,重新翻书找的。
编码功能二:试了哈希和树两种方法,最后用了树,耽误了一些时间。
编码功能三:这项在算法上并没有什么纠结的,知识语法废了很多时间,还是基础不好造成的。
代码复审:在文件路径上换了好几次,其他方面都还可以。
测试:其实挺顺利的,测了两篇文章都能实现。
计算工作量:计时用的是手机截图,真的好乱啊,整理就耽误不少时间,下次要下载一个计时软件。
编码功能四:本来想放弃了,后来想着还有时间就试一下,比较拖沓,花费时间又不知道是否符合要求。
写博客:这是本篇博客最后一句话。
遇到的困难:
由于编程基础较差,编译这个软件还是挺费劲的。刚开始想用自己比较熟悉的C语言,编译了很久还是不能运行,总是有算法错误,最后放弃了,不过这个过程耽误了不少时间,实为可惜。后来才不得不用了自己不熟悉的Java语言,配置JDK也失败了,就只能用NetBeans环境了。大三后期就没怎么碰过Java了,因为准备考研,对面向对象完全生疏了。所以用了一天时间又翻出了Java教材通读了一遍,编程时也是一边翻书一边编译,实在是艰辛。我的编程能力绞尽脑汁依然不能完成作业中要求的四个功能,只能编出这个简单的读取文件进行词频统计(心塞)。Java语言的薄弱基础就是我最大的困难。
感到得意的地方:
整个作业完成过程都在被虐,丝毫没有得意的地方。
感到突破的地方:
自己已经很久没有使用Java,对Java在内心中总是有一种陌生感和恐惧感。但是这次作业完成过程,自己独立编写出一个小程序并且能成功运行,还是感觉自己有迈出再次学习Java的勇敢一步,Java的加强已经刻不容缓,此后我会每天学习Java,认真的,欢迎各种形式监督。