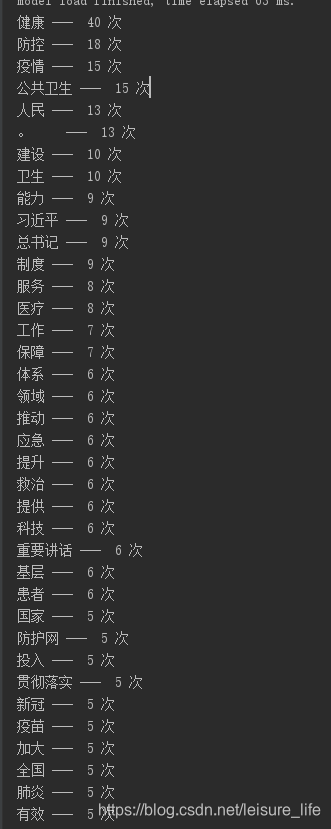
需求是统计一篇文章、一段话中各种词汇出现的次数,比如有一篇文章如下:为维护人民健康提供有力保障,希望统计文章中的高频词,如下结果
难点在于分词,例如这段换:工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作,如果分的不好,那会十分的尴尬!!!
找了很多工具,在网上发现一个比较合适的分词算法,且是用java实现的,经过简单改动,实现了功能,代码放在gitee上,地址:https://gitee.com/langhu/jieba-analysis-mend
导下项目后长这个样子:
直接运行com.qianxinyao.analysis.jieba.keyword包下的main方法即可
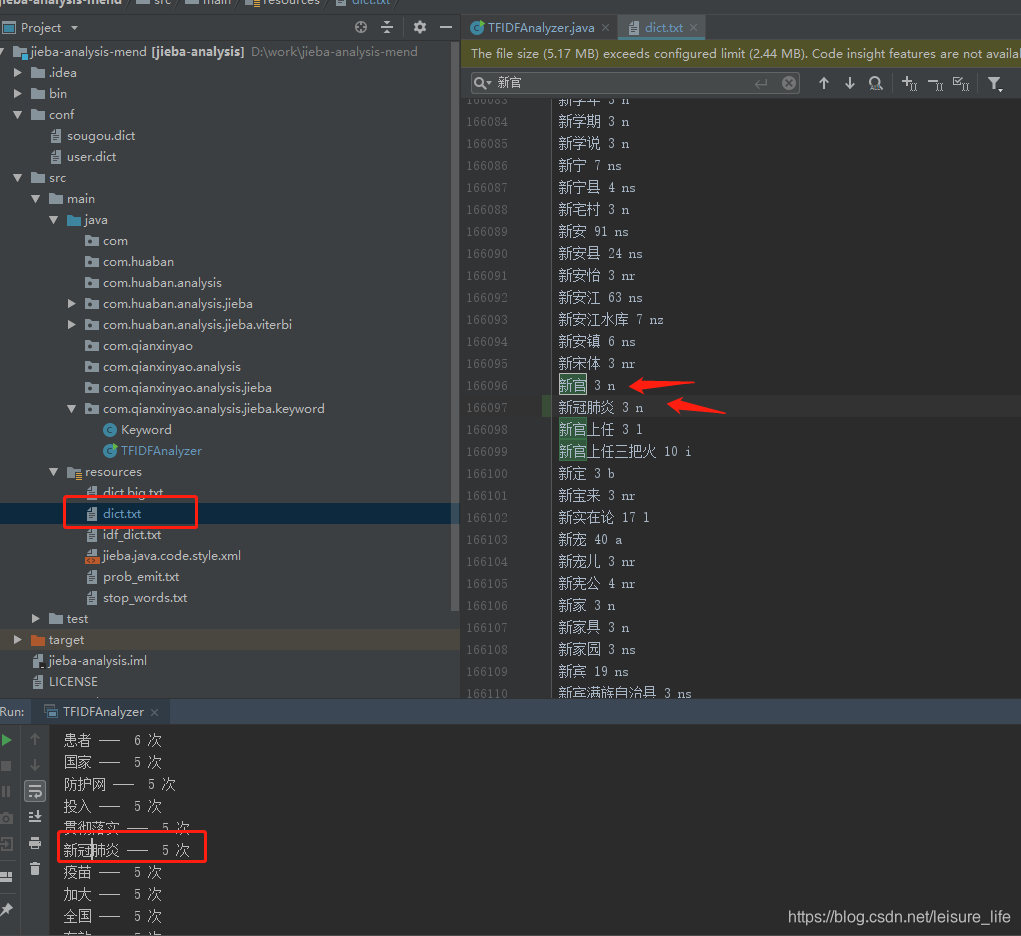
问题:在这个工具中,通过训练过的算法,给出了很多词汇切割的标准,但发现有些新词汇,特别是专有词汇它并不能很好的识别,比如文中的新冠肺炎,它就拆成了新冠和肺炎,这个怎么处理呢?
1、要么你去训练算法,如果你牛。
2 直接改分词规则(可能会破坏算法的合理性),我不牛,所以我改
怎么改,肯定不能瞎改,找到dict.txt,找一个和你要统计的词汇,在拼音顺序上差不多的词,直接按照它的格式来,如下:我想加一个新冠肺炎,于是找到了它的邻居新官,没的说,复制新官改成新冠肺炎,再试一下截图如下: