!!!我的.txt文件以tap作为分割不是空格
1.框架结构如下
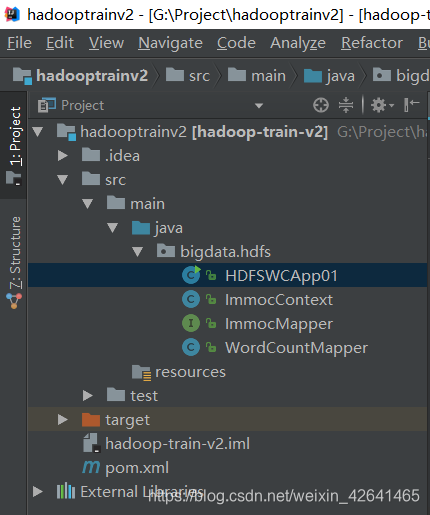
2.
package bigdata.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Map;
import java.util.Set;
/**
* 使用HDFS API完成wordcount统计
*
* 需求:统计HDFS上的文件 WC,然后将统计结果输出到HDFS
* 功能拆解:
* 1) 读取HDFS上的文件
* 2)业务处理(词频统计):对文件中的每一行数据都要进行业务处理(按照分隔符分割)==》Mapper
* 3)将处理的结果缓存起来 ==》Context
* 4)将处理的结果输出到HDFS ==>HDFS API
*/
public class HDFSWCApp01 {
public static void main(String[] args) throws Exception{
//(1)读取HDFS上的文件 ==> HDFS API
Path input=new Path("/hdfsapi/test/hello.txt");
//获取要操作的HDFS文件系统
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.19.3:8020"),new Configuration(),"jerry");
RemoteIterator<LocatedFileStatus> iterator=fs.listFiles(input,false);//迭代器,是集合专有的遍历方式
ImmocMapper mapper =new WordCountMapper();
ImmocContext context= new ImmocContext(); //new一个上下文
while ((iterator.hasNext())){
LocatedFileStatus file=iterator.next();
FSDataInputStream in=fs.open(file.getPath());
BufferedReader reader =new BufferedReader(new InputStreamReader(in));
String line="";
while ((line=reader.readLine())!=null){
//(2)业务处理(词频统计)
mapper.map(line,context);
}
reader.close();
in.close();
}
//Map 键值对:每个键后面对应着相应的值, 当按下相应的键时, 就会输出相应的结果
//TODO (3)将处理的结果缓存起来 Map
//Map<Object,Object> contextMap= new HashMap<Object, Object>();
Map<Object,Object> contextMap =context.getCacheMap();
//(4)将结果输出到HDFS ==> HDFS API
Path output=new Path("/hdfsapi/output");
FSDataOutputStream out = fs.create(new Path(output,new Path("wa.out")));
//TODO 将第三步缓存中的内容输出到out中去
Set<Map.Entry<Object,Object>> entries= contextMap.entrySet();
for (Map.Entry<Object,Object> entry:entries){
out.write((entry.getKey().toString() + "\t" + entry.getValue() + "\n").getBytes());
}
out.close();
fs.close();
System.out.println("运行成功");
}
}
package bigdata.hdfs;
import java.util.HashMap;
import java.util.Map;
/**
* 自定义上下文,缓存
*/
public class ImmocContext {
private Map<Object,Object> cacheMap = new HashMap<Object, Object>();
public Map<Object,Object> getCacheMap(){
return cacheMap;
}
/**
*写数据到缓存中去
* @param key 单词
* @param value 次数
*/
public void write (Object key,Object value){
cacheMap.put(key,value);
}
/**
* 从缓存中取值
* @param key 单词
* @return 单词对应的词频
*
* */
public Object get(Object key) {
return cacheMap.get(key);
}
}
package bigdata.hdfs;
public interface ImmocMapper {
/*
* @param line 读取到每一行数据
* @param context 上下文/缓存
* */
public void map(String line,ImmocContext context);
}
package bigdata.hdfs;
public class WordCountMapper implements ImmocMapper {
public void map(String line, ImmocContext context) {
String[] words = line.split("\t");
for (String word : words){
Object value=context.get(word);
if (value==null){ //表示没有出现过该单词
context.write(word,1);
} else {
int v=Integer.parseInt(value.toString());
context.write(word,v+1); //取出单词的次数+1
}
}
}
}
验证:
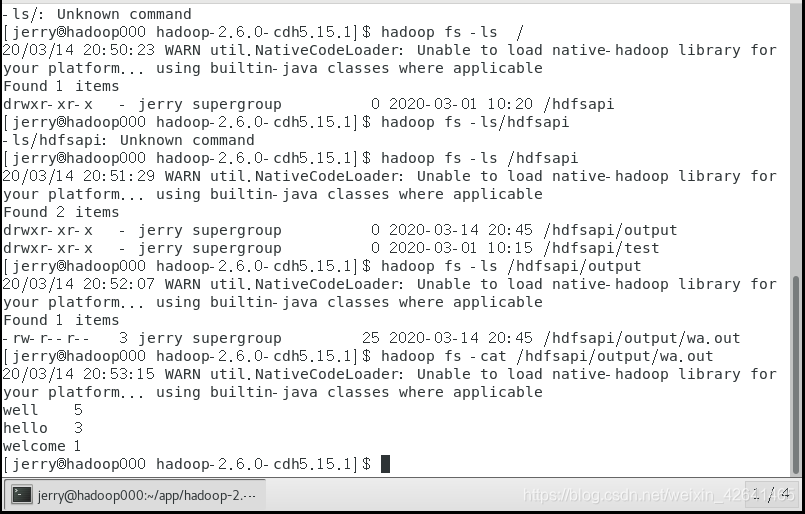
浏览器访问50070端口也可验证!
硬编码在编程过程中是非常忌讳的分享一下自定义文件配置重构代码
1.
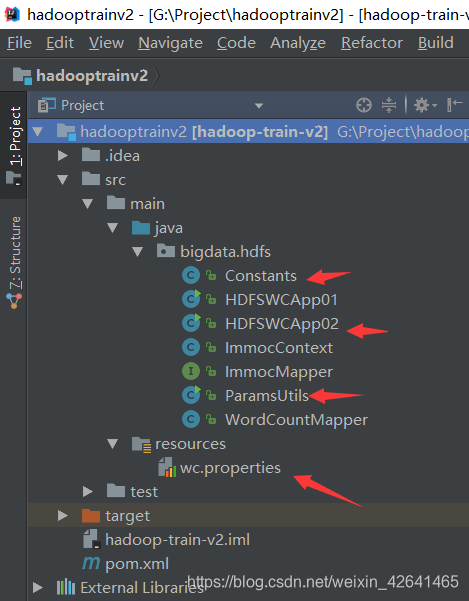
2.在resources配置文件夹新建配置文件(Mark Directory as)
wc.properties
INPUT_PATH=/hdfsapi/test/hello.txt
OUTPUT_PATH=/hdfsapi/output
OUTPUT_FILE=wa.out2
HDFS_URL=hdfs://192.168.19.3:8020
3.读取配置文件
package bigdata.hdfs;
import java.io.IOException;
import java.util.Properties;
/**
*读取属性配置文件
*/
public class ParamsUtils {
private static Properties properties=new Properties();
static {
try {
properties.load(ParamsUtils.class.getClassLoader().getResourceAsStream("wc.properties"));
} catch (IOException e) {
e.printStackTrace();
}
}
public static Properties getProperties() throws Exception{
return properties;
}
public static void main(String[] args) throws Exception{
System.out.println( getProperties().getProperty("INPUT_PATH"));
}
}
4.定义常量
package bigdata.hdfs;
/**
* 常量
*/
public class Constants {
public static final String INPUT_PATH="INPUT_PATH";
public static final String OUTPUT_PATH="OUTPUT_PATH";
public static final String OUTPUT_FILE="OUTPUT_FILE";
public static final String HDFS_URL="HDFS_URL";
}
5.实现
package bigdata.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
/**
* 使用HDFS API完成wordcount统计
*
* 需求:统计HDFS上的文件 WC,然后将统计结果输出到HDFS
* 功能拆解:
* 1) 读取HDFS上的文件
* 2)业务处理(词频统计):对文件中的每一行数据都要进行业务处理(按照分隔符分割)==》Mapper
* 3)将处理的结果缓存起来 ==》Context
* 4)将处理的结果输出到HDFS ==>HDFS API
*/
public class HDFSWCApp02 {
public static void main(String[] args) throws Exception{
//(1)读取HDFS上的文件 ==> HDFS API
Properties properties=ParamsUtils.getProperties();
Path input=new Path(properties.getProperty(Constants.INPUT_PATH));
//获取要操作的HDFS文件系统
FileSystem fs=FileSystem.get(new URI(properties.getProperty(Constants.HDFS_URL)),new Configuration(),"jerry");
RemoteIterator<LocatedFileStatus> iterator=fs.listFiles(input,false);//迭代器,是集合专有的遍历方式
ImmocMapper mapper =new WordCountMapper();
ImmocContext context= new ImmocContext(); //new一个上下文
while ((iterator.hasNext())){
LocatedFileStatus file=iterator.next();
FSDataInputStream in=fs.open(file.getPath());
BufferedReader reader =new BufferedReader(new InputStreamReader(in));
String line="";
while ((line=reader.readLine())!=null){
//(2)业务处理(词频统计)
mapper.map(line,context);
}
reader.close();
in.close();
}
//Map 键值对:每个键后面对应着相应的值, 当按下相应的键时, 就会输出相应的结果
//TODO (3)将处理的结果缓存起来 Map
//Map<Object,Object> contextMap= new HashMap<Object, Object>();
Map<Object,Object> contextMap =context.getCacheMap();
//(4)将结果输出到HDFS ==> HDFS API
Path output=new Path(properties.getProperty(Constants.OUTPUT_PATH));
FSDataOutputStream out = fs.create(new Path(output,new Path(properties.getProperty(Constants.OUTPUT_FILE))));
//TODO 将第三步缓存中的内容输出到out中去
Set<Map.Entry<Object,Object>> entries= contextMap.entrySet();
for (Map.Entry<Object,Object> entry:entries){
out.write((entry.getKey().toString() + "\t" + entry.getValue() + "\n").getBytes());
}
out.close();
fs.close();
System.out.println("运行成功");
}
}
